raft算法
raft算法可以看做是paxos算法的工程实现。
拜占庭失效
又称任意失效,主要指远端服务不可信任,比如假冒、发送错误信息。
需要注意的是,FLP 不可能性指出:没有任何算法可以在存在失效的异步系统中达成共识[4]。所以现有的异步系统中的共识算法都只能做到较大概率达成共识,这类算法使用故障检测、随机化等手段,将异步模型改造成部分同步系统,规避 FLP 不可能性的约束。raft 算法使用的正是故障检测和随机化。
raft的两个子问题
- leader election
- log replication
leader election
三种状态
每个结点在任意时刻都处于三种状态之一:
- leader
- follower
- candidate
以看出所有节点启动时都是follower状态;在一段时间内如果没有收到来自leader的心跳,从follower切换到candidate,发起选举;如果收到majority的造成票(含自己的一票)则切换到leader状态;如果发现其他节点比自己更新,则主动切换到follower。
总之,系统中最多只有一个leader,如果在一段时间里发现没有leader,则大家通过选举-投票选出leader。leader会不停的给follower发心跳消息,表明自己的存活状态。如果leader故障,那么follower会转换成candidate,重新选出leader。
term
term(任期)以选举(election)开始,然后就是一段或长或短的稳定工作期(normal Operation)。从上图可以看到,任期是递增的,这就充当了逻辑时钟的作用;另外,term 3展示了一种情况,就是说没有选举出leader就结束了,然后会发起新的选举,后面会解释这种split vote的情况。
选举过程
上面已经说过,如果follower在election timeout内没有收到来自leader的心跳,(也许此时还没有选出leader,大家都在等;也许leader挂了;也许只是leader与该follower之间网络故障),则会主动发起选举。步骤如下:
- 增加节点本地的 current term ,切换到candidate状态,
- 投自己一票,并行给其他节点发送 RequestVote RPCs
- 等待其他节点的回复
在这个过程中,根据来自其他节点的消息,可能出现三种结果
- 收到majority的投票(含自己的一票),则赢得选举,成为leader
- 被告知别人已当选,那么自行切换到follower
- 一段时间内没有收到majority投票,则保持candidate状态,重新发出选举
第一种情况,赢得了选举之后,新的leader会立刻给所有节点发消息,广而告之,避免其余节点触发新的选举。在这里,先回到投票者的视角,投票者如何决定是否给一个选举请求投票呢,有以下约束:
- 在任一任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(这一部分,后面介绍log replication和safety的时候会详细介绍)
- first-come-first-served 先来先得
第二种情况,比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。
第三种情况,没有任何节点获得majority投票,也就是没有结点能够获取超过二分之一的选票。如果出现平票的情况,那么就延长了系统不可用的时间(没有leader是不能处理客户端写请求的),因此raft引入了randomized election timeouts来尽量避免平票情况。同时,leader-based 共识算法中,节点的数目都是奇数个,尽量保证majority的出现。
log同步过程
当系统(leader)收到一个来自客户端的写请求,到返回给客户端,整个过程从leader的视角来看会经历以下步骤:
- leader append log entry
- leader issue AppendEntries RPC in parallel
- leader wait for majority response
- leader apply entry to state machine
- leader reply to client
- leader notify follower apply log
可以看到日志的提交过程有点类似两阶段提交(2PC),不过与2PC的区别在于,leader只需要大多数(majority)节点的回复即可,这样只要超过一半节点处于工作状态则系统就是可用的。
不难看到,logs由顺序编号的log entry组成 ,每个log entry除了包含command,还包含产生该log entry时的leader term。从上图可以看到,五个节点的日志并不完全一致,raft算法为了保证高可用,并不是强一致性,而是最终一致性,leader会不断尝试给follower发log entries,直到所有节点的log entries都相同。
在上面的流程中,leader只需要日志被复制到大多数节点即可向客户端返回,一旦向客户端返回成功消息,那么系统就必须保证log(其实是log所包含的command)在任何异常的情况下都不会发生回滚。这里有两个词:commit(committed),apply(applied),前者是指日志被复制到了大多数节点后日志的状态;而后者则是节点将日志应用到状态机,真正影响到节点状态。
Raft 也是分布式一致性协议,主要是用来竞选主节点。
单个 Candidate 的竞选
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
- 下图展示一个分布式系统的最初阶段,此时只有 Follower 没有 Leader。Node A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。

- 此时 Node A 发送投票请求给其它所有节点。
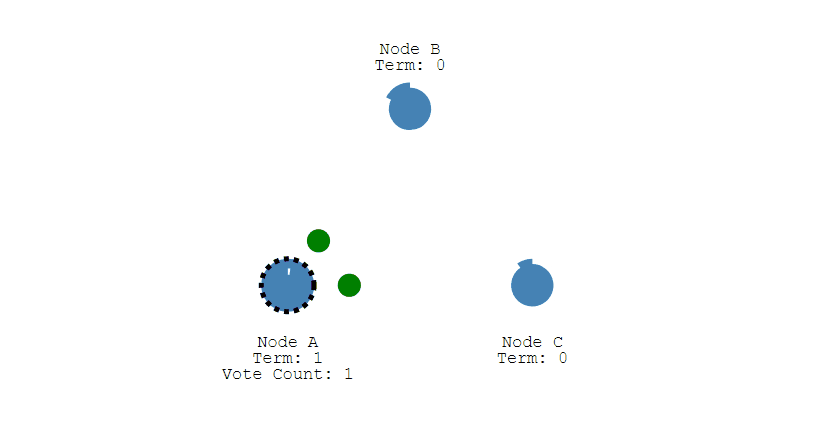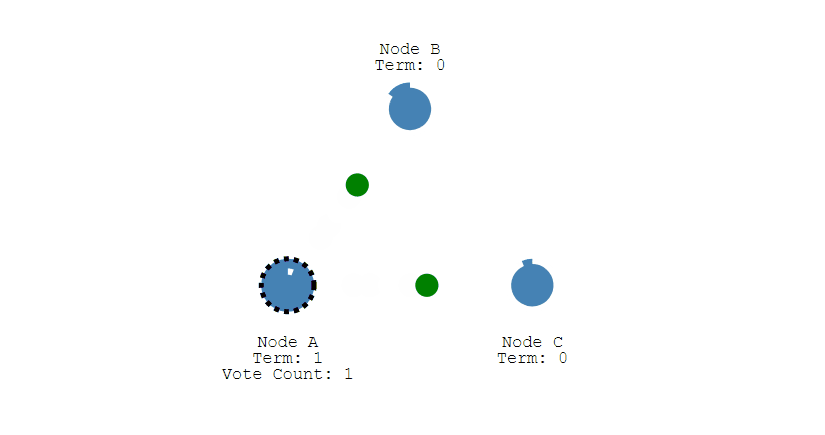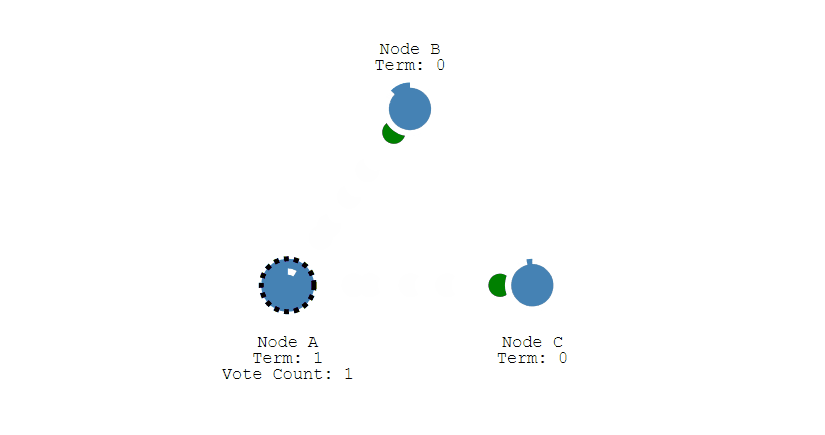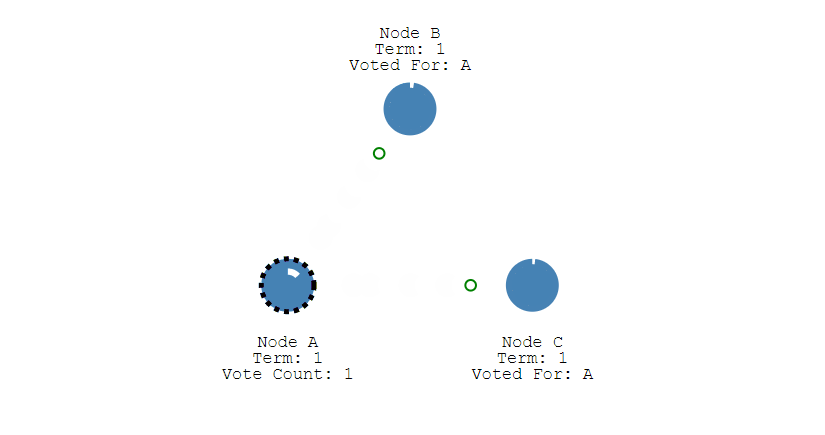
- 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。

- 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。

多个 Candidate 竞选
- 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。例如下图中 Node B 和 Node D 都获得两票,需要重新开始投票。

- 由于每个节点设置的随机竞选超时时间不同,因此下一次再次出现多个 Candidate 并获得同样票数的概率很低。

数据同步
- 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。

- Leader 会把修改复制到所有 Follower。

- Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。

- 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。

参考资料
- golang版raft算法实现:https://github.com/etcd-io/etcd/tree/master/raft
- raft算法演示:http://thesecretlivesofdata.com/raft/
- raft github.io:https://raft.github.io/
- raft PPT:https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
- raft 博客:https://www.cnblogs.com/xybaby/p/10124083.html
https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md#6-%E9%9B%86%E7%BE%A4%E6%88%90%E5%91%98%E5%8F%98%E5%8C%96 https://www.google.com.hk/search?newwindow=1&safe=strict&rlz=1C5CHFA_enCN915CN915&q=raft%E5%8F%AF%E8%A7%86%E5%8C%96&sa=X&ved=2ahUKEwjn-N3ojZbvAhVay4sBHfjhAacQ1QIwFnoECCEQAQ&biw=1164&bih=655 Raft:一种易于理解的共识算法 http://thesecretlivesofdata.com/raft/ https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md#6-%E9%9B%86%E7%BE%A4%E6%88%90%E5%91%98%E5%8F%98%E5%8C%96